딥네트워크는 전기차 모터 제어(PMSM, Permanent Magnet Synchronous Motor)와 배터리 관리 시스템(BMS, Battery Management System) 분야에서 핵심 알고리즘을 개발하고 기술 자문을 제공하는 일인 기업입니다. 비록 상용화된 제품 경험은 부족하지만, 지난 2년간 전기차 구현의 세부 기술 노하우를 축적해 왔으며, 이를 바탕으로 투자 유치를 통해 사업화를 준비하고 있습니다.
딥네트워크는 PMSM 모터 제어와 BMS 관련한 핵심 알고리즘 설계 및 구현 능력을 통해 전기차 성능을 극대화할 수 있는 기술력을 보유하고 있습니다. 이러한 전문 기술력은 투자자들에게 차별화된 경쟁 우위를 제공할 수 있으며, 사업화 가능성을 극대화하기 위한 추가적인 준비를 통해 전기차 시장에서 강력한 경쟁력을 확보할 것입니다.
2. 전기차 핵심 기술력 소개
PMSM 모터 제어 기술:
딥네트워크는 고성능 영구자석 동기 모터(PMSM)의 회전 자계와 자속 간의 상호 작용을 최적화하는 고급 제어 알고리즘을 개발 가능하도록 세부분석이 되있습니다. 이 기술은 벡터 제어(FOC, Field-Oriented Control)를 기반으로 하여, 정밀한 속도 및 위치 제어를 가능하게 합니다.
핵심 알고리즘은 전류의 d-q 좌표계 변환을 통한 모터의 자속 및 토크 제어에 최적화되어 있습니다. 이로 인해 모터의 효율성이 높아지고, 고속에서도 안정적인 성능을 유지할 수 있습니다.
모터 제어에서 가장 중요한 파라미터 튜닝 알고리즘도 개발되어 있습니다. 이를 통해 PID(비례, 적분, 미분) 제어기를 정확히 조정하여, 모터의 가속과 감속 시 발생할 수 있는 과도 현상을 최소화합니다.
배터리 관리 시스템(BMS) 기술:
딥네트워크의 BMS 기술은 배터리 셀 간의 균형을 유지하고, 충방전 과정을 효율적으로 관리하는 데 초점을 맞추고 있습니다. 셀 밸런싱 알고리즘은 전압 차이를 실시간으로 모니터링하고, 최적의 충전 상태(SOC, State of Charge)를 유지합니다.
배터리의 상태를 실시간으로 모니터링하기 위해 고급 필터링 기법(Kalman Filter 기반)을 사용하여, 배터리의 수명과 안전성을 극대화하는 기술을 가능하도록 세부분석이 되있습니다.
열 관리 알고리즘은 배터리 내부의 온도를 효과적으로 제어하여 과열을 방지하고, 최적의 온도 범위 내에서 충전 및 방전을 수행합니다. 이러한 기술은 전기차의 안전성을 높이고, 배터리의 효율성을 극대화하는 데 큰 역할을 합니다.
전기차 구현의 시스템 통합:
딥네트워크는 모터 제어 시스템과 BMS 간의 통신 프로토콜을 최적화하여, 전체 시스템의 성능을 극대화하는 기술을 보유하고 있습니다. CAN 통신을 기반으로 한 시스템 통합 기술을 통해 각 구성 요소 간의 데이터를 빠르고 정확하게 주고받을 수 있으며, 이를 바탕으로 전기차의 구동 효율성을 높일 수 있습니다.
3. 핵심 기술 알고리즘 설계 분석
Field-Oriented Control(FOC) 알고리즘:
FOC는 PMSM 제어에서 자주 사용되는 기술로, 딥네트워크는 d-q 좌표계에서 자속과 토크를 독립적으로 제어할 수 있는 고급 알고리즘을 구현했습니다. 이를 통해 모터의 효율을 극대화할 수 있으며, 특히 고속 주행 시 자속 약화 제어 기술이 도입되어 고성능을 유지할 수 있습니다.
플럭스 약화 제어(Flux Weakening Control)는 고속에서의 자속 제어를 최적화하여, 모터가 고속 영역에서도 효율적인 토크를 발휘할 수 있게 합니다.
현재 세부 구현 준비중인 Kalman Filter 기반 BMS 알고리즘:
딥네트워크의 BMS 알고리즘은 배터리의 충전 상태를 추정하는 데 Kalman 필터를 사용합니다. 이 알고리즘은 실시간으로 배터리 상태를 분석하고 예측하여, 충방전 시 발생할 수 있는 문제를 미연에 방지합니다. 또한, SOC(State of Charge) 예측 모델을 통해 배터리 잔량을 정확히 파악할 수 있습니다.
최적 제어 알고리즘:
모터 제어에 있어서 PID 제어기의 자동 튜닝 기술을 개발하였습니다. 이 기술은 각 전기차의 하드웨어 특성에 맞게 제어 파라미터를 최적화하여, 초기 구동 시 설정 오류를 최소화합니다.
또한, 딥네트워크는 전기차 주행 환경에 맞춰 실시간으로 제어 파라미터를 조정하는 적응형 제어 알고리즘도 연구 중입니다.
4. 투자 유치 및 사업화 계획
사업화 준비:
딥네트워크는 현재 모터 제어 및 배터리 관리 시스템 기술에 대한 핵심 알고리즘을 개발 완료한 상태입니다. 하지만 상용화된 제품 개발은 아직 이루어지지 않았으며, 이를 위해 투자 유치가 필요합니다.
전기차 시장의 빠른 성장에 발맞춰, 딥네트워크는 고성능 모터 제어 솔루션과 BMS 기술을 통합한 전기차 구동 시스템을 상용화하는 것을 목표로 하고 있습니다. 투자 자금을 통해 하드웨어 프로토타입 개발 및 검증, 실차 테스트 등을 진행할 계획입니다.
기술 고도화 및 확장 계획:
향후 투자 유치를 통해 딥네트워크는 FOC, BMS 기술을 더욱 고도화하여 다양한 전기차 모델에 적용 가능한 모듈형 솔루션을 개발할 것입니다.
또한, 자율주행 차량의 모터 제어 및 배터리 관리 시스템에도 적용할 수 있는 확장형 알고리즘을 개발할 계획입니다. 이를 통해 딥네트워크는 전기차뿐만 아니라, 자율주행차 및 미래 모빌리티 시장에서 경쟁력을 강화할 것입니다.
5. 결론
딥네트워크는 전기차 모터 제어 및 배터리 관리 시스템 분야에서 독자적인 알고리즘 설계와 개발 경험을 보유하고 있는 전문 스타트업입니다. 고도화된 기술력을 바탕으로, 투자 유치를 통해 전기차 시장에서 혁신적인 솔루션을 제공할 준비가 되어 있습니다.
반도체 제조에서 3 나노(nm) 공정은 매우 정밀한 공정으로, 원자층 수준의 정밀도를 요구합니다. 이를 위해 식각, 노광, 포토마스킹 등의 주요 공정은 각각 고유한 설계 원리와 기술적 개선을 통해 수율을 확보합니다.
1. 노광 장비 (Lithography)
노광 공정은 포토레지스트라는 감광 물질 위에 패턴을 형성하는 단계로, 반도체 회로의 미세한 선폭을 결정합니다. 3 나노 공정에서는 기존의 광원보다 훨씬 짧은 파장을 사용하는 극자외선(EUV) 노광 기술이 필수적입니다. EUV 노광은 파장이 약 13.5nm로 매우 짧아, 기존의 DUV(심자외선, 193nm) 노광보다 훨씬 더 작은 패턴을 만들 수 있습니다.
멀티 패터닝: 3 나노 공정에서 단일 노광만으로 원하는 패턴을 만드는 것이 어렵기 때문에 멀티 패터닝 기법이 사용됩니다. 이 과정에서 여러 번의 노광을 통해 매우 복잡한 패턴을 형성하여 미세한 회로를 만들어 냅니다.
EUV 노광의 도전 과제: EUV의 장비 비용이 높고, EUV 광원에서 나오는 빛을 균일하게 제어하는 것이 매우 어렵습니다. 이를 극복하기 위해 EUV 광원의 강도를 높이고, 포토마스크(마스크 블랭크)를 더 정밀하게 제작하는 기술이 필요합니다.
2. 포토마스킹 (Photomasking)
포토마스킹은 특정한 패턴을 마스크에 새긴 후, 이를 노광 공정에 사용하여 웨이퍼에 패턴을 전사하는 과정입니다. 3 나노 공정에서는 포토마스크의 정밀도가 더욱 중요해지며, 광학 근접 보정(Optical Proximity Correction, OPC) 같은 기술이 활용됩니다.
OPC는 마스크 패턴이 실제로 회로 패턴에 전사될 때 발생하는 왜곡을 보정하여, 보다 정확한 회로 선폭을 만들 수 있게 도와줍니다. 이는 광학 현상에 의한 패턴 왜곡을 미리 계산하고, 이를 마스크 디자인에 반영하는 방식으로 구현됩니다.
펠리클(pellicle): 마스크 위에 펠리클이라는 얇은 막을 씌워 마스크가 오염되지 않도록 보호하며, 미세한 회로를 유지하는 데 필수적입니다.
3. 식각 (Etching)
식각 공정은 웨이퍼 표면에 형성된 패턴에 따라 필요하지 않은 부분을 제거하는 단계입니다. 3 나노 공정에서는 원자층 식각(ALD, Atomic Layer Deposition) 및 원자층 증착(ALE, Atomic Layer Etching) 기술이 사용됩니다.
ALD 및 ALE: 원자층 단위로 물질을 증착하거나 식각하는 기술입니다. 기존의 식각 방식보다 훨씬 더 정밀하게 특정한 층을 원자 단위로 제거하거나 추가할 수 있습니다. 이를 통해 회로의 균일성과 정밀도를 크게 향상시킬 수 있습니다.
플라즈마 식각: 식각 과정에서 플라즈마를 사용하여 정확한 제어가 가능해지며, 3 나노급 회로 선폭의 정밀한 패턴을 구현할 수 있습니다. 특히, 하이애니소트로픽(highly anisotropic) 식각이 필요합니다. 이는 수직 방향으로만 식각이 이루어져, 패턴의 측면 침식이 최소화되도록 합니다.
4. 공정 설계 및 수율 확보
3 나노 공정에서는 수율이 크게 중요한데, 이를 위해 다음과 같은 설계 원리가 적용됩니다.
공정 제어(PCM, Process Control Monitoring): 각 단계에서 공정을 정밀하게 모니터링하고 피드백을 통해 실시간으로 공정 조건을 조정합니다. 이를 통해 불량률을 최소화하고 높은 수율을 유지할 수 있습니다.
멀티 패터닝 최적화: 3 나노 공정에서 멀티 패터닝은 필수적이지만, 추가 공정으로 인해 수율이 떨어질 수 있습니다. 이를 방지하기 위해, 패턴 정렬 및 레지스트 두께 등을 최적화하여 멀티 패터닝을 안정적으로 구현합니다.
결함 검사(Defect Inspection): EUV 및 식각 공정에서 발생할 수 있는 미세 결함을 초고해상도 검사 장비를 통해 확인하고, 이를 신속하게 수정하는 방법이 수율 확보에 필수적입니다.
결론
3 나노 공정에서 원자층 증착 장비와 관련된 공정은 EUV 노광, 멀티 패터닝, 원자층 식각 등의 고도화된 기술이 결합되어 작동합니다. 이를 통해 고정밀 회로를 구현하고, 공정 안정성과 수율을 높이기 위해 다양한 공정 제어 및 결함 검사 기술이 활용됩니다. 각 기술은 상호 보완적으로 작동하여, 미세 회로의 패턴 정확도를 높이고 양산 가능성을 극대화합니다.
원자층 식각(ALE, Atomic Layer Etching)과 원자층 증착(ALD, Atomic Layer Deposition) 기술은 3 나노 공정에서 매우 정밀한 회로를 형성하는 데 중요한 역할을 합니다. 이 두 기술은 원자 단위로 물질을 증착하거나 제거할 수 있어, 미세한 회로 선폭을 제어하고 공정 수율을 높이는 데 기여합니다. 아래에서 각각의 기술과 공정 설계 원리를 통해 3 나노 공정의 수율을 확보하는 방식을 살펴보겠습니다.
1. 원자층 증착 (ALD, Atomic Layer Deposition)
ALD는 원자 단위로 얇은 층을 균일하게 증착하는 기술로, 매우 얇고 균일한 박막을 형성하는 데 적합합니다. 특히 3 나노 공정과 같은 극미세 공정에서는 ALD의 정확성이 필수적입니다.
ALD의 작동 원리
ALD는 반응성 가스(reagent gases)를 주기적으로 웨이퍼에 공급하고, 각각의 반응은 웨이퍼 표면에서 일어나는 화학적 반응을 기반으로 합니다. 주기적인 반응을 통해 원자 단위로 박막을 쌓아 올리며, 각 반응 사이에서 웨이퍼를 세척하여 불필요한 물질이 축적되지 않도록 합니다.
표면 흡착: 첫 번째 반응성 가스가 웨이퍼 표면에 도달하여 화학적으로 결합합니다. 이때 표면에서만 반응이 일어나며, 그 이상의 두께로 증착되지 않습니다.
제거(배출) 및 세척: 반응이 완료된 후, 남은 가스를 제거하여 불순물 없는 상태를 유지합니다.
두 번째 가스 도입: 다음 반응성 가스를 도입하여 첫 번째 층과 반응시킵니다. 이 과정에서 다시 표면에만 반응이 일어납니다.
반복: 원하는 두께가 될 때까지 이 과정을 반복하여 원자층 단위로 박막을 형성합니다.
ALD의 공정 설계 원리와 수율 확보
정밀도 및 균일성: ALD는 주기적인 반응을 통해 원자 단위의 제어가 가능하므로, 3 나노 공정에서 요구되는 극히 얇고 균일한 박막을 형성하는 데 적합합니다. 균일한 증착은 회로 성능의 일관성을 보장하고, 불량률을 줄이는 데 기여합니다.
공정 제어 및 모니터링: ALD는 반응성을 철저하게 제어하기 때문에 매우 정밀한 두께 제어가 가능하며, 이는 선폭과 회로 패턴의 정확성을 높여 수율을 향상시킵니다.
재료 다양성: ALD는 다양한 재료에 적용 가능하므로, 트랜지스터 게이트, 배선 절연층 등 다양한 구성 요소에 사용됩니다. 이는 전체 공정에서 필요한 재료 특성을 최적화하여, 성능을 극대화하고 결함을 최소화할 수 있게 합니다.
2. 원자층 식각 (ALE, Atomic Layer Etching)
ALE는 ALD와 반대로, 웨이퍼 표면에서 원자층 단위로 불필요한 물질을 제거하는 기술입니다. ALE는 특히 3 나노 공정과 같은 초미세 공정에서 매우 중요한데, 불필요한 물질을 제거하는 동안 패턴의 변형이나 손상을 최소화할 수 있기 때문입니다.
ALE의 작동 원리
ALE는 화학적 식각과 물리적 식각을 결합하여 매우 정밀한 식각을 구현합니다. 다음은 ALE의 주요 단계입니다.
화학적 흡착: 첫 번째로, 화학적으로 반응하는 가스를 도입하여 웨이퍼 표면과 선택적으로 반응시킵니다. 이 가스는 제거할 층과 화학적 결합을 형성하지만, 반응은 표면에서만 일어납니다.
이온 활성화: 반응한 층을 플라즈마나 이온 빔을 사용하여 활성화시키면, 결합된 물질이 더 쉽게 제거됩니다.
제거: 물리적 또는 화학적 방식을 통해 활성화된 원자층을 제거합니다. 이 과정을 원자 단위로 반복하여 필요한 만큼의 층만 식각합니다.
ALE의 공정 설계 원리와 수율 확보
선택적 식각: ALE는 매우 선택적인 식각 공정을 사용하여 목표 물질만 제거하고, 주변의 다른 구조물이나 레이어에 손상을 주지 않습니다. 이는 초미세 회로에서 패턴 변형을 줄이고, 수율을 높이는 데 큰 기여를 합니다.
높은 애니소트로피(Anisotropy): ALE는 수직으로만 식각이 진행되므로, 측면 식각을 최소화합니다. 이는 패턴의 변형을 방지하고, 매우 정밀한 패턴을 유지하는 데 중요합니다.
정밀한 공정 제어: ALE는 식각 깊이를 원자 단위로 조정할 수 있어, 원하는 패턴의 두께와 모양을 매우 정밀하게 제어할 수 있습니다. 이를 통해 3 나노 공정에서 요구되는 극도로 얇은 층과 패턴을 정확하게 유지할 수 있습니다.
3. ALD와 ALE의 통합 설계 원리
ALD와 ALE는 서로 상호 보완적인 공정으로 함께 사용됩니다. 예를 들어, 특정 레이어를 ALD를 통해 증착한 후, 불필요한 부분을 ALE로 원자 단위로 제거하는 방식이 적용됩니다. 이러한 통합 공정은 다음과 같은 방식으로 3 나노 공정의 수율을 높입니다.
패턴 정밀도 향상: ALD는 매우 균일한 층을 형성하고, ALE는 불필요한 부분을 정확히 제거하므로, 패턴의 정밀도를 높일 수 있습니다. 이는 트랜지스터 게이트, 금속 배선, 절연막 등 미세한 회로 구성 요소에 필수적입니다.
공정 제어 최적화: 두 공정 모두 원자 단위로 물질을 제어할 수 있기 때문에, 전체 공정에서 발생할 수 있는 변동성을 줄이고, 이를 통해 불량률을 감소시켜 수율을 향상시킵니다.
공정 안정성: 반복적인 증착과 식각 공정을 통해 고정밀 패턴을 안정적으로 형성할 수 있으며, 이는 대량 생산에서도 안정적인 수율을 보장하는 데 기여합니다.
결론
ALD와 ALE 기술은 3 나노 공정에서 원자 단위로 물질을 증착하거나 제거할 수 있는 뛰어난 정밀도를 제공합니다. 이러한 기술은 회로 선폭의 정확성을 극대화하고, 패턴 변형이나 손상을 최소화하여 공정 수율을 높이는 데 중요한 역할을 합니다. 또한 이 두 기술의 통합 사용은 미세 공정에서 매우 중요한 균일성과 패턴 정밀도를 유지함으로써, 고성능 반도체 생산에 기여합니다.
딥네트워크는 LLM(대형 언어 모델)과 같은 인공지능(AI) 알고리즘의 효율적인 추론을 지원하기 위한 NPU(Neural Processing Unit) 칩셋을 상용화하는 것을 목표로 사업을 준비 중이다. NPU 설계의 핵심은 AI 모델에서 빈번하게 발생하는 행렬 곱셈의 병렬 처리를 최적화하여 추론 속도와 전력 효율을 극대화하는 것이다. 특히 Verilog Tool을 사용해 하드웨어 설계를 진행하며, AI 알고리즘의 요구사항에 맞는 구조적 최적화가 필요하다.
2. 주요 내용 요약
2.1. 행렬 곱셈의 병렬 처리
AI 모델에서의 행렬 곱셈은 Self-Attention Mechanism과 같은 핵심 연산에 주로 사용되며, 많은 계산 리소스를 요구한다. 특히 Transformer 모델에서는 여러 층에서 반복적으로 발생하는 행렬 곱셈을 어떻게 병렬로 효율적으로 처리할 것인지가 성능을 결정한다.
행렬 곱셈 병렬 처리를 위해 사용되는 대표적인 알고리즘은 GEMM(General Matrix Multiplication) 알고리즘이다. 이 알고리즘은 대규모 행렬 곱셈을 효율적으로 처리하기 위해 각 행렬을 작은 블록으로 분할하여 병렬 연산을 수행한다.
2.2. 병렬 처리 설계 구조
NPU에서 행렬 곱셈의 병렬 처리를 위해 다음과 같은 설계 구조를 구현한다:
PE(Processing Element) 구조: NPU의 핵심은 PE(Processing Element)이다. 각 PE는 부분적으로 분할된 행렬 블록을 병렬로 처리하는 유닛이다. 다수의 PE가 동시에 행렬 곱셈을 수행하며, 이를 통해 병렬성을 극대화한다.
데이터 재사용 및 캐싱: 연산에 사용되는 데이터는 메모리에서 매번 읽어오는 대신 캐시 구조를 통해 재사용한다. 특히 행렬 곱셈의 경우 동일한 데이터가 여러 번 사용되므로, 데이터 전송 병목을 줄이기 위한 온칩 캐시 설계를 통해 성능을 최적화한다.
파이프라인(Pipelining): 각 연산을 연속적으로 수행할 수 있도록 파이프라인 구조로 설계하여 처리 시간을 줄인다. 파이프라이닝은 연산과 데이터 전송을 중첩시켜, 연산이 완료되기 전에 데이터를 미리 준비할 수 있게 한다.
SIMD 구조: PE 내에서는 SIMD(Single Instruction, Multiple Data) 방식으로 다수의 데이터에 대해 동시에 동일한 연산을 수행하여 병렬성을 극대화한다. 이를 통해 행렬 곱셈뿐만 아니라 다양한 AI 연산에서 성능을 향상시킬 수 있다.
2.3. Self-Attention Mechanism 최적화
Transformer 모델의 Self-Attention Mechanism은 특히 많은 연산이 필요한 부분이다. 이를 최적화하기 위해서는 다음과 같은 방법이 적용된다:
Query, Key, Value 병렬화: Self-Attention 연산은 Query, Key, Value 행렬에 대한 병렬 처리가 핵심이다. 각 Query는 독립적으로 Key와 Value와의 연산을 수행할 수 있으므로, 이를 병렬로 처리할 수 있는 구조로 설계한다.
Multi-Head Attention 병렬화: Multi-Head Attention에서는 각 헤드가 독립적인 연산을 수행하므로, 각 헤드를 병렬로 처리할 수 있도록 한다. 이를 통해 Attention 연산의 병목을 줄이고, 연산 성능을 크게 향상시킨다.
2.4. 연산 스케줄링 최적화
연산 스케줄링은 NPU에서 연산 유닛의 유휴 시간을 최소화하는 것이 목표이다. 이를 위해 비동기 처리와 파이프라인 설계를 통해 연산과 데이터 전송을 동시에 진행한다.
또한, 연산과 데이터 전송의 중첩을 통해 각 레이어의 연산이 완료되기 전에 다음 연산에 필요한 데이터를 미리 전송하여 병목을 줄인다.
2.5. 메모리 사용 최적화
메모리 사용량을 줄이기 위해 Mixed Precision 연산을 적용한다. FP16 또는 BF16과 같은 정밀도를 낮춘 연산을 통해 메모리 사용량을 줄이면서도 높은 성능을 유지한다. 특히, LLM 모델의 대규모 추론에서 메모리 사용 최적화는 매우 중요한 역할을 한다.
3. 상용화 전략
딥네트워크의 NPU 상용화를 위한 전략은 다음과 같다:
칩셋 설계 최적화: Verilog Tool을 사용하여 병렬 행렬 곱셈을 효과적으로 처리할 수 있는 NPU 설계를 완료하고, AI 알고리즘의 요구사항에 맞게 하드웨어 최적화를 지속한다.
칩셋 검증 및 테스트: 설계한 NPU 칩셋의 성능을 검증하기 위해 다양한 AI 모델을 사용한 테스트를 진행하고, 특히 Transformer 기반의 LLM 모델에서 성능을 평가한다.
파트너십 구축: 칩셋 상용화를 위해 대형 반도체 제조업체와의 협력을 통해 제조 공정 및 양산 계획을 수립하고, AI 솔루션 제공 업체와 협력하여 NPU 칩셋의 실제 적용 가능성을 검증한다.
시장 진출 계획: NPU 칩셋이 AI 추론 시장에서 경쟁력을 확보하기 위해 주요 클라우드 업체나 AI 플랫폼에서의 도입을 목표로 한다. 특히, LLM 모델을 지원하는 클라우드 AI 인프라와의 협력을 통해 상용화를 추진한다.
4. 결론
딥네트워크는 AI 알고리즘의 고성능 추론을 지원하는 NPU 칩셋을 Verilog Tool을 통해 설계하고, 병렬 행렬 곱셈과 Self-Attention Mechanism을 최적화하는 구조를 통해 성능을 극대화하고 있다. 이러한 설계는 상용화 단계를 거쳐 AI 칩셋 시장에서 혁신적인 솔루션을 제공할 수 있을 것으로 기대된다.
일인 기술 스타트업 딥네트워크 소개 : AI 모델 최적화 및 최첨단 기술로 혁신을 선도하는 스타트업
소개: 딥네트워크는 대형 언어 모델(LLM)과 통신 시스템의 개발, 분석, 최적화를 전문으로 하는 1인 AI 스타트업입니다. 창립자는 AI 기술, 특히 LLM 분산 학습과 트랜스포머(Transformer) 모델에 대한 심도 있는 이해를 바탕으로 첨단 솔루션을 제공합니다. 딥네트워크는 텐서플로우(TensorFlow)와 쿠버네티스(Kubernetes) 기반의 분산 시스템을 활용해 확장 가능한 AI 솔루션을 다수의 산업에 제공하고자 합니다.
핵심 기술력 및 주요 분야:
LLM 모델 최적화 및 분산 학습:
딥네트워크는 GPT, LLaMA, Google Gemma와 같은 트랜스포머 기반의 LLM 분석 및 구현에 강점을 가지고 있습니다. 이들 모델은 다양한 작업 간 학습을 통해 성능을 향상시키며, 요약 및 질의응답과 같은 여러 작업에서 뛰어난 결과를 보여줍니다.
분산 학습 기술을 통해 이 모델들을 최적화합니다. TensorFlow와 Horovod를 사용하여 NVIDIA GPU를 기반으로 대규모 학습 시스템을 구축하고 효율적으로 실행합니다. 특히 A100 시리즈 GPU를 활용한 쿠버네티스 클러스터의 리소스 할당과 스케일링, 오류 복구를 위한 기술력을 보유하고 있습니다.
쿠버네티스의 nvidia/k8s-device-plugin을 이용한 GPU 워크로드 관리 및 YAML 스크립트를 사용해 Pod 리소스 할당과 분산 모델 학습을 최적화하는 경험을 가지고 있습니다.
AI 추론을 위한 샘플링 기법:
딥네트워크는 Top-k 및 Top-p(Nucleus Sampling)과 같은 고급 샘플링 기법을 통해 추론 정확도와 다양한 출력을 향상시키는 데 주력합니다.
Top-k 샘플링은 예측 결과 중 상위 k개의 토큰을 선택하고, Top-p 샘플링은 누적 확률이 p 이상이 되는 토큰을 선택하여 동적으로 샘플링 범위를 조정합니다. 이를 통해 모델은 반복적인 응답을 방지하고 다양한 토큰 후보를 탐색하여 정확성과 창의성을 동시에 향상시킵니다.
트랜스포머 모델 경량화:
LoRA(저랭크 적응 기법)와 같은 경량화 기술을 활용하여, 컴퓨팅 복잡도를 줄이면서도 성능을 유지하는 트랜스포머 모델을 최적화합니다. 이를 통해 리소스가 제한된 환경에서도 효율적인 추론이 가능해집니다.
Horovod와 Kubernetes를 통한 분산 학습:
딥네트워크는 Horovod와 TensorFlow를 활용하여 NVIDIA GPU 클러스터 전반에 걸쳐 데이터 병렬화를 수행하는 분산 모델 학습에 대한 깊은 이해를 가지고 있습니다. 특히, Horovod의 집합 통신 전략을 통해 트랜스포머 모델을 확장 가능하게 만들고, 수조 개의 토큰을 처리하는 대규모 학습을 효율적으로 수행합니다.
LLaMA와 같은 모델의 토크나이저, 어텐션 메커니즘, 피드포워드 네트워크를 최적화하여 병렬 학습의 효율성을 극대화합니다.
양자 컴퓨팅 연구:
딥네트워크는 양자 컴퓨팅을 차세대 연구 주제로 삼고 있습니다. 양자 게이트 및 그로버 알고리즘을 연구하여, AI 모델에서 탐색 및 최적화 작업을 향상시키기 위한 양자 원리를 통합하는 것을 목표로 합니다.
또한, 딥네트워크는 양자 얽힘과 초위상성을 활용한 양자 텔레포테이션 연구를 진행 중이며, 이러한 개념을 AI 계산 및 암호화에 적용하는 가능성을 탐구하고 있습니다.
통신 시스템 전문성:
위상 배열 안테나 설계 및 신호 변조:
딥네트워크는 위상 배열 안테나 시스템, 빔포밍 제어, 16QAM 변조/복조 기술에 대한 깊이 있는 연구와 개발을 진행하고 있습니다. 이러한 시스템은 신호 무결성, 효율성 및 확장성을 향상시켜 5G 및 위성 네트워크와 같은 통신 시스템에 적합하게 설계되었습니다.
윌킨슨 파워 디바이더와 FEC 오류 수정 알고리즘을 사용하여 안테나 배열을 최적화함으로써, 복잡한 환경에서도 데이터 전송의 안정성을 확보할 수 있습니다.
Bluetooth 및 Zigbee 통신 프로토콜:
딥네트워크는 Bluetooth 5.1 및 Zigbee와 같은 다중 장치 통신 프로토콜 구현에 대한 실무 경험을 보유하고 있습니다. Nordic API와 nRF5 SDK를 사용하여 1:20 멀티 페어링 및 전력 관리를 효율적으로 처리하는 시스템을 개발했습니다.
Zigbee 1:20 통신 시스템은 저전력, 장거리 전송을 최적화하여 IoT 애플리케이션에 이상적입니다. 슬립, 대기, 깊은 슬립과 같은 전력 모드를 관리하여 배터리 수명과 통신 신뢰성을 극대화합니다.
안전한 통신과 TLS 1.2 보안:
딥네트워크는 TLS 1.2 보안에서 발생하는 암호화 키의 안전한 저장 문제를 해결하기 위해 통신 시스템에서의 보안 문제도 다루고 있습니다. 이 솔루션은 특히 금융 및 의료와 같은 보안이 중요한 산업에 필수적입니다.
AI 및 통신 기술 혁신:
특수 애플리케이션을 위한 맞춤형 솔루션:
딥네트워크는 STM32H743에서 WiFi 모듈을 사용하는 소켓 통신 등과 같은 영역에서 맞춤형 IT 솔루션을 제공합니다. 이러한 시스템은 산업용 IoT 및 임베디드 시스템에 적합하게 설계되었습니다.
AI와 통신 시스템의 통합:
딥네트워크의 핵심 혁신 중 하나는 AI 모델을 사용하여 위상 배열 안테나에서 빔포밍을 최적화하는 통신 기술과 AI의 통합입니다. 이를 통해 AI와 통신 기술의 융합 가능성을 넓히고 있습니다.
양자 컴퓨팅과 AI의 융합:
양자 컴퓨팅 연구를 통해 딥네트워크는 고전적 AI 모델과 양자 컴퓨팅의 융합을 시도하며, 최적화 알고리즘, 암호화, 통신 시스템에서 새로운 가능성을 열어가고 있습니다.
과제와 비전:
현재 과제:
딥네트워크는 상업화에 필요한 자금이 부족하다는 과제를 안고 있지만, 핵심 기술과 알고리즘을 성공적으로 확보하여 향후 성장의 기반을 마련하고 있습니다.
대량 생산 경험은 부족하지만, AI와 통신 시스템에서의 프로토타입 개발을 통해 상당한 잠재력을 입증하고 있습니다.
미래 비전:
딥네트워크는 LLM 모델 최적화 및 통신 시스템에서 리더로 자리매김하여, 분산 학습, 빔포밍 기술, 양자 컴퓨팅을 활용한 상업적 제품을 제공하는 것을 목표로 하고 있습니다.
투자 기회를 모색하여, 현재의 프로토타입을 확장 가능한 제품 및 서비스로 발전시키고 AI 기반 자동화, 양자 보안 시스템과 같은 분야에서 변화를 주도할 계획입니다.
결론: 딥네트워크는 혁신적인 연구와 최첨단 기술 솔루션을 통해 AI 및 통신 시스템의 경계를 넓히는 선도적인 스타트업입니다. LLM 분산 학습, 트랜스포머 모델 최적화, 고급 통신 프로토콜에 대한 전문성을 바탕으로, 딥네트워크는 AI 및 통신 기술의 미래를 이끌어갈 준비가 되어 있습니다.
저도 사회생활 30 년차면 적은 나이는 아닌것 같읍니다 ... 요즘 최근까지 저는 약 10 년 이상 IT 분야 개발용역 일을 했었읍니다 ... 돈을 벌어야 하니 개발용역 의뢰가 들어 올때 합리적인 제안(의뢰)을 하시는 분은 10 - 20 % 도 안되는것 같읍니다 ... 최근 기술이 몇배가 발전하다 보니 세상이 자본 여력이 있는 대기업들이 대부분의 IT 개발 분야 솔루션을 제공하다 보니 10 년전만 해도 이런 솔루션 제공으로 개발을 하려면 안정화가 덜된것들을 제공해서 애 먹어 가면서 개발해야 했었는데 이제는 기술이 몇배가 발전하다보니 이제는 퀄리티가 되는것들을 제공하긴 하는데 문제는 IT 제품 개발 이라는게 반도체 칩셋을 사용해서 구현하기 때문에 반도체 칩셋사에서 제공하는 솔루션으로 개발시 퀄리티는 꽤 되는데 제품으로써의 가치평가 기준이 되는 크리티컬한 세부분야의 개발을 하려면 칩셋사에 MOQ 구매오더가 없이는 퀄리티 있는 정보제공을 안해 주니 역시 이것도 자금 여력 문제가 가장 중요해 보인다 ... 자본주의는 자본 여력이 안되면 뭐 하나 되는게 없는것 같다 ... 반도체 칩셋사도 이것 개발하는라고 개발비가 엄청 많이 들었을텐데 고객들이 칩셋은 소량으로 몇개 구매하면서 거액들여 개발해 논 고급정보를 달라고 하면 아무리 바보라도 고급정보는 절대 제공치 않을것 같읍니다 ... 그리고 또 절감하는것은 내가 몇가지 분야라도 일등 기술력이 없으면 요즘 같이 AI 기술 발전으로 인해 세상이 뒤집어졌는데 나의 히든 카드가 준비가 안되있으면 요즘같이 대기업이든 중소기업이든 나가는 돈 줄일라고 한국 이건 미국이건 사활을 거는 세상인데 내가 히든카드가 없으면 이런 세상에서 돈 버는것은 매우 어려운 세상 입니다 ... 이건 한국의 중소기업 이건 대기업이건 모두 해당된다 ... 한국의 대기업도 히든카드 준비가 부족하면 강대국한데 갑질 당하는게 다반사 인것 같읍니다 ... 내가 요즘 또 느끼는게 한국의 중소기업이 대기업에 대응하기 위해 히든카드가 필요한것 처럼 한국의 대기업도 강대국에 대응하기 위해 히든카드 준비를 해야 하는데 이 히든 카드라는게 한국의 대기업이 준비하는 히든카드를 강대국은 이미 앞선 기술을 이미 갖고 있는 경우가 많다 ... 나의 블로그를 자세히 살펴 보시면 제가 왜 이런 내용을 언급하는지 이해 하실수 있을것 같읍니다 ... 저도 소기업 이지만 한국 대기업이 가진 히든 카드를 확보하려고 노력중이구요 ... 요즘은 정보 공유가 워낙 활발해서 돈이 되는 히든카드 확보는 한국 이건 미국인건 어디서나 똑 같다는거구요 ... 이렇게 정보 공유가 활발한 세상에서 맥 놓고 앉아 있으면 곧 바로 도퇴되는 세상이니 사람들이 탐내는 히든카드 확보 노력을 하는 제가 그렇게 쓰잘데기없는 것만은 아닌것 같읍니다 ..
Deep Network는 최신 대형 언어 모델(LLM)의 분석 및 구현을 전문으로 하는 1 인 스타트업으로, 특히 대규모 분산 학습 환경에서 Horovod와 TensorFlow를 기반으로 한 최적화 기술의 노하우 분석에 강점을 가지고 있습니다. 이 회사는 대형 트랜스포머 기반 모델의 설계, 분산 학습 구현, 그리고 경량화 기법을 연구하며, Kubernetes 클러스터 환경에서 Nvidia A100 GPU를 활용한 병렬 처리 시스템의 세부 구현 노하우 준비하는 중이고 이를 통해 고성능 모델 학습을 효율적으로 수행합니다.
1. LLM의 분석과 최적화 경험
Deep Network는 LLaMA, LoRA 등 경량화된 트랜스포머 모델의 분석과 최적화를 분석한 경험이 있으며, 이를 통해 대규모 트랜스포머 모델의 성능을 개선 노하우를 분석에 성공했고, 상업적 AI 서비스로의 전환 가능성을 모색하고 있습니다. 특히, 다양한 학습 알고리즘과 데이터셋 쌍을 바탕으로 모델 간의 상호 작용을 최적화하여 더 높은 학습 효율을 구현하는 데 집중해왔습니다.
2. 분산 학습 환경 설계
Horovod와 TensorFlow를 기반으로 한 분산 학습 설계는 Deep Network의 주요 강점 중 하나입니다. 특히 MPI(Message Passing Interface)와 NCCL(NVIDIA Collective Communication Library)을 활용한 노드 간 파라미터 동기화는 대규모 분산 환경에서 최적의 성능을 이끌어내기 위한 핵심 요소로 작용합니다.
Horovod AllReduce 알고리즘을 사용하여 각 GPU 노드 간의 그라디언트를 병렬 처리하며, NCCL을 통해 그라디언트 동기화 성능을 최적화합니다.
TensorFlow 기반의 분산 옵티마를 활용하여 각 노드에서의 모델 학습 및 파라미터 동기화를 동시에 진행합니다.
이러한 구조는 수천 대의 Nvidia A100 GPU를 Kubernetes 기반 클러스터에서 관리하며, 대규모 LLM 학습을 효율적으로 분산 처리하는 방안을 제시합니다.
3. Kubernetes 환경에서의 GPU 관리 및 클러스터 구성
Deep Network는 Kubernetes를 이용해 대규모 GPU 클러스터를 구성하고 관리하는 노하우를 보유하고 있습니다. 특히, Nvidia A100 GPU를 활용한 분산 학습 처리를 위한 nvidia/k8s-device-plugin과 NVIDIA GPU Operator를 통해 GPU 자원의 상태를 모니터링하고, 각 Pod에 GPU 자원을 할당하여 병렬 학습을 수행합니다.
Pod 간 분산 처리: 각 Pod에 할당된 GPU 자원은 Horovod의 분산 학습 알고리즘에 따라 서로 다른 데이터를 병렬로 처리하며, 이를 통해 학습 속도를 극대화합니다.
GPU 자원의 최적 활용: Kubernetes 환경에서 Horovod와 TensorFlow의 조합을 통해 각 Pod에 적절한 자원을 할당하고, 이를 동적으로 관리하여 클러스터의 성능을 극대화합니다.
4. Horovod 및 TensorFlow의 통합을 통한 학습 환경 구현
Horovod는 MPI와 NCCL을 사용하여 노드 간의 데이터 교환을 최적화하며, Deep Network는 이를 기반으로 각 GPU 간의 그라디언트 동기화 작업을 효율적으로 처리합니다.
Horovod 설치 및 환경 설정: 모든 노드에 동일한 학습 환경을 제공하기 위해 Docker를 사용하여 Horovod와 TensorFlow 환경을 일관되게 설정합니다.
mpirun 명령을 사용한 학습 실행: mpirun을 통해 여러 노드에 분산된 GPU 자원으로 병렬 학습을 실행하며, 각 노드가 계산한 그라디언트를 NCCL을 사용해 동기화합니다.
5. Python 기반의 구현 방안
Deep Network는 TensorFlow와 Horovod를 Python 기반으로 통합하여 분산 학습 노하우를 일부 확보하고 있으며, Python 코드에서 Horovod와의 통합을 통해 각 노드의 그라디언트를 동기화하고 이를 사용하여 모델 파라미터를 업데이트하는 과정을 자동화합니다.
6. LLM 경량화 및 상업화 준비
Deep Network는 LLM 모델의 경량화에도 집중하고 있으며, 이를 통해 상업적 서비스로 전환 가능한 AI 솔루션을 현재는 세부 노하우를 분석하고 있습니다. LoRA와 같은 경량화 기술을 통해 모델의 파라미터 수를 줄이고, 이를 통해 학습 속도를 개선하고, 메모리 사용을 최소화하여 더 빠른 추론 속도를 달성합니다.
7. 실용적인 연구 성과 및 기술력
수천 대의 GPU 노드를 동기화하는 Horovod 기반의 분산 학습 환경을 성공적으로 분석하였고 대규모 LLM 모델 학습을 효율적 처리를 준비 하였습니다.
TensorFlow와 Horovod를 결합하여, Kubernetes 클러스터에서 효율적인 GPU 자원 관리 및 자동화된 학습 환경을 제공하는 기술력을 일부 보유하고 있습니다.
LoRA 및 LLaMA 모델을 포함한 최신 경량화 기술을 분석하고 이를 실용적으로 활용하여 상업적 AI 솔루션 개발을 준비 중입니다.
결론
Deep Network는 LLM 분석 및 구현에 대한 전문 지식을 바탕으로 복잡한 학습 환경에서 고성능 AI 모델을 구축하는 기술적 능력을 보유하고 있습니다. 특히, Horovod, TensorFlow, Kubernetes를 활용한 대규모 분산 학습 환경을 구성하고, 이를 효율적으로 관리하며, LLM 모델의 최적화 및 경량화에 주력하고 있습니다. 이를 통해 상업적 AI 서비스로 확장 가능한 기술적 기반을 확보하였으며, 앞으로도 이러한 기술력을 바탕으로 다양한 산업에 혁신적인 AI 솔루션을 제공할 계획입니다.
nRF5 SDK for Thread and Zigbee 환경에서 1:20 송수신 시나리오에 맞는 송수신 로직과 전력관리를 구현
nRF52840 DK (Development Kit)
제품 설명: nRF52840 DK는 nRF52840 칩을 기반으로 Zigbee, BLE, 2.4GHz 무선 통신 등을 개발할 수 있는 공식 개발 키트입니다.
기능: Zigbee 네트워크에서의 송신/수신/대기/슬립/딥 슬립 모드 제어를 위한 Nordic SDK를 지원하며, 특히 Zephyr RTOS와 통합하여 Zigbee 통신을 구현할 수 있습니다.
API 제어: Nordic의 Zigbee SDK는 송신/수신과 같은 기능을 포함하여 전력 소비를 줄이기 위한 여러 모드 제어 API를 제공합니다. zigbee_stack_init(), zb_set_sleep_mode(), zb_set_power_mode() 등의 함수가 있으며, 전력 관리와 관련된 API가 준비되어 있습니다.
사용 가능한 운영 모드:
TX 모드 (송신 모드): 데이터를 송신할 때 전력을 사용.
RX 모드 (수신 모드): 수신 모드에서 지속적으로 수신을 대기.
Standby 모드 (대기 모드): 일부 모듈만 활성화된 상태로 빠르게 전환이 가능.
Sleep 모드: Zigbee를 포함한 무선 기능을 완전히 비활성화하고 낮은 전력 모드로 전환.
Deep Sleep 모드: 가장 낮은 전력 소비 모드로, 외부 인터럽트에 의해 다시 활성화.
nRF52840 Dongle
제품 설명: nRF52840 Dongle은 저렴한 Zigbee 및 BLE 개발을 위한 USB 동글로, 작은 크기에도 불구하고 nRF52840 칩셋의 기능을 충분히 활용할 수 있습니다.
기능: 전력 관리 기능을 포함한 Nordic Zigbee SDK와 통합 가능.
API 제어: 송신 및 수신 모드를 제어하는 Zigbee API와 슬립 및 대기 모드를 제어하는 전력 관리 API 제공.
Zigbee 1:20 송수신 구현을 위한 시나리오는 하나의 송신 노드가 20개의 수신 노드로 데이터를 브로드캐스트하거나 멀티캐스트하는 것을 의미합니다. 이를 구현하기 위해서는 송신과 수신 시 Zigbee 네트워크 통신을 설정하고, 전력 소비를 관리하기 위해 송신(TX), 수신(RX), 대기(Standby), 슬립(Sleep), 딥 슬립(Deep Sleep) 모드를 제어할 수 있어야 합니다.
nRF5 SDK for Thread and Zigbee에서는 이러한 작업을 수행할 수 있는 다양한 API가 제공되며, 아래와 같은 시나리오와 API 설정을 통해 1:20 Zigbee 통신을 구현할 수 있습니다.
1:20 송수신 시나리오 개요 송신 노드: 데이터를 Zigbee 네트워크에 브로드캐스트/멀티캐스트하며, 송신 이후 슬립 모드나 딥 슬립 모드로 전환해 전력 절감. 수신 노드: 송신 노드에서 데이터를 수신하며, 데이터를 수신하지 않을 때 슬립 모드 또는 딥 슬립 모드로 전환해 대기. 전력 모드: 각 노드에서 상황에 맞게 전력 모드를 관리해 최대한의 전력 효율성을 달성. 1. 송신 (TX) 모드 설정 및 구현 송신 노드는 데이터를 주기적으로 송신하고, 송신 후 슬립 모드로 전환합니다. zb_zcl_start_attr_reporting() API를 사용하여 데이터를 송신할 수 있습니다.
// 송신 후 슬립 모드로 전환 zb_sleep_now(5000); // 5초 동안 슬립 모드 }
주요 API 설명: zb_zcl_start_attr_reporting(): 지정된 클러스터의 속성 보고를 시작하여 송신 모드를 활성화합니다. zb_zdo_send_data(): Zigbee 네트워크로 데이터를 브로드캐스트로 전송합니다. zb_sleep_now(): 송신 후 전력을 절약하기 위해 슬립 모드로 전환합니다. 2. 수신 (RX) 모드 설정 및 구현 수신 노드는 송신 노드에서 브로드캐스트된 데이터를 수신하며, 데이터를 수신하지 않을 때 슬립 모드로 전환됩니다. 수신 콜백 함수 zb_zcl_report_attr_cb()를 통해 데이터를 처리할 수 있습니다.
주요 API 설명: zb_zcl_report_attr_cb(): 송신된 데이터를 수신하고 처리하는 콜백 함수입니다. 수신된 데이터를 검사하고 필요한 동작을 수행합니다. zb_zcl_register_attr_report_cb(): 데이터 수신 시 호출될 콜백 함수를 등록합니다. zb_sleep_now(): 데이터 수신 후 슬립 모드로 전환하여 전력 소모를 줄입니다. 3. 대기 모드 설정 대기 모드는 데이터 송수신이 이루어지지 않는 상태에서 노드를 유지하는 모드입니다. 기본적으로 Zigbee 네트워크에서 활동이 없을 경우 대기 모드로 진입합니다.
void standby_mode(void) { zb_ret_t ret = zigbee_stack_init(); if (ret == RET_OK) { printf("Zigbee stack initialized, node in standby mode.\n"); } }
4. 슬립 모드 및 딥 슬립 모드 설정 슬립 모드는 전력 소비를 줄이기 위해 사용되며, 수신 대기 시간이 짧거나 활동이 없을 때 전환됩니다. 딥 슬립 모드는 더 긴 시간 동안 비활성화되며, 외부 인터럽트나 이벤트가 발생할 때만 활성화됩니다.
슬립 모드
void enter_sleep_mode(void) { zb_sleep_now(10000); // 10초 동안 슬립 모드 } 딥 슬립 모드 c 코드 복사 void enter_deep_sleep_mode(void) { zb_go_to_deep_sleep(60000); // 60초 동안 딥 슬립 모드 }
5. 1:20 송수신 시나리오 요약 송신 노드는 zb_zcl_start_attr_reporting() API를 통해 데이터를 브로드캐스트하고, 데이터 전송 후 슬립 모드로 전환하여 전력 소비를 줄입니다. 수신 노드는 zb_zcl_report_attr_cb() 콜백 함수를 통해 데이터를 수신하고 처리하며, 수신 후에는 슬립 모드 또는 대기 모드로 전환해 에너지를 절약합니다. 대기 및 슬립 모드는 zb_sleep_now()와 같은 전력 관리 API를 통해 적절하게 제어되며, 필요에 따라 딥 슬립 모드로 전환해 장시간의 저전력 상태를 유지할 수 있습니다. 이러한 전력 관리 및 송수신 제어는 nRF5 SDK for Thread and Zigbee에서 제공하는 API를 통해 쉽게 구현할 수 있으며, 전반적인 시스템 전력 효율성을 크게 향상시킬 수 있습니다.
수신 콜백 함수 zb_zcl_report_attr_cb()를 통해 어떻게 데이터를 수신하는지 세부 구현 예를 상세히 제시하라
zb_zcl_report_attr_cb()를 통해 데이터를 수신하는 과정은 Zigbee 클러스터의 속성(Attribute) 값이 변경되었을 때, 이를 보고하는 메시지를 수신하는 방식으로 이루어집니다. 수신된 데이터는 콜백 함수에서 처리되며, 이를 통해 노드는 해당 데이터를 파싱하고 적절한 동작을 수행할 수 있습니다.
아래는 zb_zcl_report_attr_cb()와 관련된 세부 구현 예시입니다. 이 코드는 nRF5 SDK for Thread and Zigbee에서 제공하는 콜백 기반 데이터 수신 구조를 설명합니다.
1. 콜백 함수 등록 먼저, 수신할 데이터를 처리할 콜백 함수를 등록합니다. 이를 위해 zb_zcl_register_attr_report_cb() 함수를 사용하여 지정된 콜백을 설정합니다.
void zigbee_receive_init(void) { // 속성 보고를 처리할 콜백 함수 등록 zb_zcl_register_attr_report_cb(receive_data_cb); } 2. 콜백 함수 정의 이제 콜백 함수인 receive_data_cb()를 정의하여 실제로 데이터를 수신하고 처리하는 로직을 구현합니다.
static void receive_data_cb(zb_uint8_t param) { // 버퍼에서 속성 보고 데이터를 가져옴 zb_zcl_report_attr_cmd_t *attr_report = (zb_zcl_report_attr_cmd_t*)ZB_BUF_BEGIN(param);
// 클러스터 ID가 온/오프 클러스터인지 확인 if (attr_report->cluster_id == ZB_ZCL_CLUSTER_ID_ON_OFF) { zb_uint16_t attr_id = attr_report->attr_id; zb_uint8_t *attr_data = attr_report->attr_data; // 수신된 데이터를 로그에 출력 printf("Attribute Report received:\n"); printf("Cluster ID: 0x%04x\n", attr_report->cluster_id); printf("Attribute ID: 0x%04x\n", attr_id); printf("Attribute Data: %d\n", *attr_data);
// 속성 값이 변경된 경우 처리 로직 추가 (예: LED on/off) if (*attr_data == ZB_TRUE) { printf("Turn on the LED\n"); // LED on 처리 로직 } else { printf("Turn off the LED\n"); // LED off 처리 로직 } }
// 버퍼 해제 zb_buf_free(param); }
3. 콜백 함수 세부 설명 zb_zcl_report_attr_cmd_t 구조체: 이 구조체는 수신된 속성 보고의 세부 내용을 담고 있으며, 클러스터 ID, 속성 ID, 그리고 실제 속성 데이터를 포함합니다.
cluster_id: 수신된 데이터가 어떤 클러스터(예: 온/오프 클러스터)에 속하는지 확인합니다. attr_id: 수신된 데이터가 어떤 속성에 해당하는지 나타냅니다. attr_data: 수신된 속성의 실제 데이터 값이 저장됩니다. 예를 들어, 온/오프 클러스터에서는 이 값이 0 (off) 또는 1 (on)입니다. 속성 값 검사: attr_data 값을 확인하여 수신된 데이터가 on/off인지 판단하고, 해당하는 동작(LED on/off)을 처리합니다.
zb_buf_free(): Zigbee 버퍼는 수신 데이터 처리 후 반드시 해제해야 하므로, zb_buf_free()로 해제합니다.
4. 전체 코드 흐름 전체적으로, zb_zcl_register_attr_report_cb()로 콜백 함수를 등록하고, 속성 보고(Attribute Reporting)가 발생했을 때 해당 콜백이 호출되어 데이터를 처리합니다.
void zigbee_receive_init(void) { // 수신 콜백 함수 등록 zb_zcl_register_attr_report_cb(receive_data_cb); }
// 클러스터가 온/오프 클러스터인지 확인 if (attr_report->cluster_id == ZB_ZCL_CLUSTER_ID_ON_OFF) { zb_uint16_t attr_id = attr_report->attr_id; zb_uint8_t *attr_data = attr_report->attr_data;
// 수신된 데이터 출력 printf("Attribute Report received:\n"); printf("Cluster ID: 0x%04x\n", attr_report->cluster_id); printf("Attribute ID: 0x%04x\n", attr_id); printf("Attribute Data: %d\n", *attr_data);
// 속성 값에 따라 LED 제어 if (*attr_data == ZB_TRUE) { printf("Turn on the LED\n"); // LED on 로직 } else { printf("Turn off the LED\n"); // LED off 로직 } }
// 버퍼 해제 zb_buf_free(param); }
요약 콜백 함수 등록: zb_zcl_register_attr_report_cb() API로 속성 보고를 수신할 콜백 함수를 등록합니다. 데이터 처리: zb_zcl_report_attr_cmd_t 구조체를 통해 수신된 데이터를 확인하고 적절한 동작(예: LED on/off)을 수행합니다. 버퍼 관리: 수신된 데이터를 처리한 후에는 zb_buf_free()로 버퍼를 해제하여 메모리를 관리합니다. 이 예시는 nRF5 SDK for Thread and Zigbee 환경에서 Zigbee 네트워크의 데이터 수신 및 처리 과정을 설명하며, 이를 통해 1:20 송수신 시나리오에 맞는 수신 로직을 쉽게 구현할 수 있습니다.
일인 스타트업 딥네트워크 - 기업 개요 및 고속 디지털 데이터 전송을 위한16QAM(Quadrature Amplitude Modulation)변조 및 복조 기술 핵심 기술력 소개
딥네트워크는 창립자 장석원의 주도하에 첨단 통신 시스템 개발을 목표로 하는 IT 스타트업입니다. 딥네트워크는 방산 및 위성 통신을 포함한 여러 산업에서 응용 가능한 다양한 고급 기술을 확보하고 있으며, 특히 위상 배열 안테나 시스템과 16QAM 변조 기술을 통해 혁신적인 통신 솔루션을 제공하고 있습니다. 이 기술들은 차세대 무선 통신 및 위성 시스템에서 중요한 역할을 할 수 있으며, 투자 유치를 통해 상업화 및 대규모 제품 개발로 나아갈 계획을 가지고 있습니다.
기업의 핵심 기술력
일인 스타트업 Deep Network 의 기술력 소개
1. 16QAM 변조 및 복조 기술
딥네트워크는 고속 디지털 데이터 전송을 위한 16QAM(Quadrature Amplitude Modulation) 변조 및 복조 기술을 독자적으로 세부 구현 노하우 분석에 성공했습니다. 16QAM 기술은 특히 위성 통신 시스템과 같은 고속 데이터 전송 시스템에서 중요한 역할을 하며, 8 GHz 주파수 대역에서의 적용을 통해 높은 데이터 전송률을 유지합니다. 이 기술의 주요 기능과 구현 방식은 다음과 같습니다:
고속 데이터 전송: 16QAM은 16개의 심볼을 사용하여 각 심볼에 4비트의 데이터를 담을 수 있습니다. 이를 통해 높은 데이터 전송률을 실현하며, 8 GHz 대역에서 원거리 전송에 적합한 고속 통신을 제공합니다.
중간 주파수(IF) 변환 후 데이터 무결성 보장: 수신된 신호는 중간 주파수(IF)로 변환되더라도 원래의 데이터가 손실되지 않도록 설계되었습니다. 이 과정에서 변조된 신호가 변형되지 않도록 보장하기 위해 고주파 성분 필터링, 직교 복조 및 정확한 I/Q 성분 추출 기술이 적용됩니다.
알고리즘 및 설계 구조:
직교 복조: 수신 신호를 I(인페이즈)와 Q(쿼드라처) 성분으로 분리하여 베이스밴드 신호로 복원합니다. I와 Q 성분을 분리하기 위해 신호를 코사인 및 사인 신호와 곱하고, 저역 통과 필터(LPF)를 통해 고주파 성분을 제거합니다.
주파수 오프셋 보정: 코스탈루 및 PLL 알고리즘을 사용하여 주파수 오프셋을 추정하고 로컬 오실레이터의 주파수를 조정하여 신호의 왜곡을 최소화합니다.
위상 보정: 위상 추적기 알고리즘을 통해 I 및 Q 성분의 위상 오프셋을 추정하고 보정하여 신호의 정확성을 유지합니다.
이러한 알고리즘적 접근 방식은 데이터 전송의 안정성과 효율성을 크게 향상시키며, 위성 통신과 같은 장거리 데이터 전송에서 신뢰할 수 있는 성능을 제공합니다.
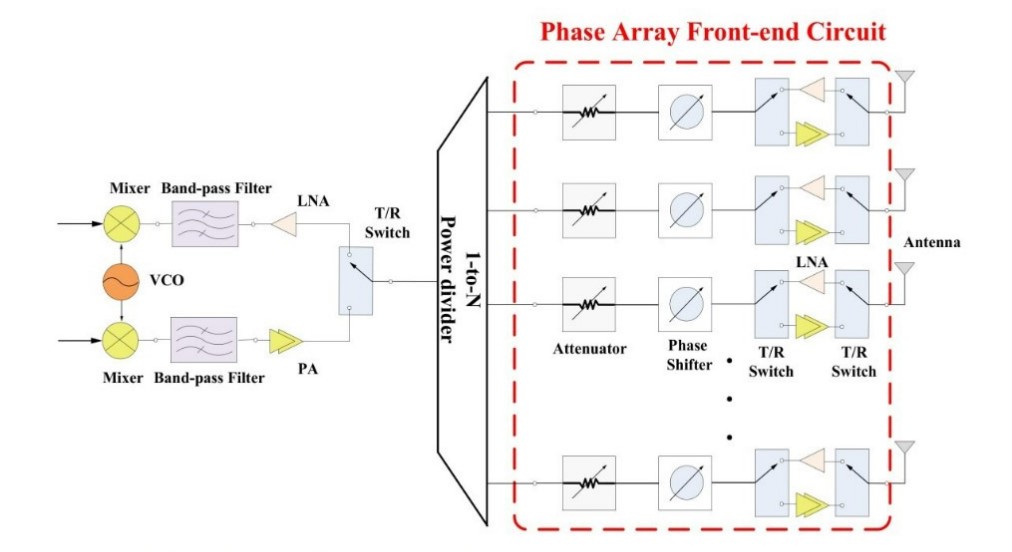
2. 위상 배열 안테나 시스템 및 빔포밍 제어
딥네트워크는 위상 배열 안테나 어레이(Phased Array Antenna Array) 기술을 기반으로 정밀한 빔포밍 제어 기술 세부 구현 노하우 분석에 성공했습니다. 이 기술은 여러 개의 안테나 요소를 독립적으로 제어하여 신호의 방향을 실시간으로 조정할 수 있으며, 레이더, 위성 통신 및 군사 통신 시스템에서 최적의 신호 품질과 성능을 제공하는 데 필수적입니다.
정확한 빔 조향: 각 위상 쉬프터의 위상을 제어하여 신호의 방향을 정확하게 조정합니다. 이를 통해 통신 신호의 품질을 극대화하고, 필요한 방향으로 신호를 집중할 수 있습니다.
Dolph-Chebyshev 윈도우 함수 적용: 메인 로브와 사이드 로브의 이득을 제어하여 통신 신호의 간섭을 최소화합니다. 이 함수를 사용하여 주파수 대역의 효율적인 사용과 간섭을 줄이면서 주요 빔 성능을 향상시킵니다.
설계 및 최적화:
위상 배열 설계: 고성능 위상 배열 안테나 어레이를 설계하여 방산 및 통신 시스템에 적합한 성능을 제공합니다. 이 설계는 다양한 응용 분야에서 안정성과 신뢰성을 보장합니다.
빔포밍 제어 알고리즘: 빔포밍 제어를 통해 신호의 방향을 실시간으로 조정하고, 주파수 대역에서 최적의 성능을 보장합니다. 이를 통해 다양한 통신 환경에서 최상의 성능을 발휘할 수 있습니다.
딥네트워크의 16QAM 변조 및 복조 기술과 위상 배열 안테나 시스템은 최신 통신 기술의 최전선에서 데이터 전송의 효율성과 신뢰성을 극대화합니다. 이러한 기술들은 고속 데이터 전송과 정밀한 신호 제어를 통해 위성 통신 및 군사 통신 시스템에서 뛰어난 성능을 제공하며, 우리의 전문성과 기술력을 입증합니다.
투자 유치 및 협력 제안
딥네트워크는 방산 및 위성 통신, 고속 무선 통신 분야에서 높은 상업적 잠재력을 가진 16QAM 변조 기술, 위상 배열 안테나 빔포밍 제어, FEC 오류 수정 알고리즘 등의 혁신적인 기술력을 보유하고 있습니다. 투자자의 관심과 지원을 통해 상용화 가능성을 높이고, 연구 및 개발의 속도를 높여 글로벌 시장에서 선도적인 위치를 차지할 수 있을 것입니다.
LLM 구현 분석 전문 일인 AI 스타트업 Deep Network: 사업화 준비 및 투자유치 계획
회사 소개
Deep Network는 인공지능(AI) 연구 및 솔루션 구현에 필요한 세부 구조 분석 및 구현 기술 분석에 특화된 일인 스타트업입니다. 우리는 2년 이상의 연구와 분석을 통해 대형 언어 모델(LLM) 및 Transformer 모델의 구조 최적화 및 경량화에 대한 전문 지식을 나름 확보하고 있습니다. 특히, LLM 모델의 분산 학습 및 병렬 처리 기술을 분석하고 이를 기반으로 나름의 경량화된 모델 설계와 학습 알고리즘 최적화 노하우를 나름 확보하여 기술적 우위를 선점하고 있습니다.
핵심 역량
LLM 분산 학습: TensorFlow 및 Horovod API를 활용한 분산 학습 구현에 대한 전문성(나름의 세부 노하우)을 보유하고 있습니다. Horovod API를 사용하여 데이터 분산 처리 및 그라디언트 동기화 설정을 통해 대규모 데이터셋을 효율적으로 학습하는것의 기술개발에 필요한 노하우를 확보 하였습니다.
Transformer 모델 경량화: Transformer 모델(예: LLaMA)의 Self-Attention, Feed-Forward 네트워크 및 Layer Normalization 모듈에 대해 경량화 알고리즘을 설계하여 연산량을 최소화하고, 모델의 성능을 유지하면서도 적은 자원을 요구하는 최적화된 구조를 확보하였습니다.
대규모 분산 학습 처리: Kubernetes 환경에서 Nvidia A100 GPU를 활용하여 대규모 학습 클러스터를 관리하고, Horovod 기반 분산 처리를 통해 수천 대의 GPU를 동기화하여 처리하는 인프라 설계에 필요한 나름의 일부 구현 관련 노하우를 가지고 있습니다.
제품 및 서비스
경량화된 LLM 모델 제공: 기업용 솔루션으로 경량화된 대형 언어 모델을 제공하여 AI 활용의 비용 절감 및 성능 향상을 지원합니다.
AI 인프라 최적화 컨설팅: 대규모 AI 모델 학습을 위한 분산 처리 및 클러스터 관리에 대한 컨설팅 서비스를 제공하여, 기업들이 효율적인 AI 모델을 운영할 수 있도록 지원합니다.
맞춤형 솔루션 개발: 고객의 요구에 맞는 커스텀 AI 솔루션을 설계하고, 이를 최적화하여 제공하는 서비스를 제공합니다.
기술 개요
LLaMA 및 유사한 Transformer 모델의 분산 학습 시 Horovod API를 사용하여 Self-Attention 및 Feed-Forward 레이어의 그라디언트 동기화를 구현하였습니다. MPI(메시지 전달 인터페이스) 기반의 Horovod는 GPU 간의 통신을 효율적으로 처리하여, 데이터 병렬 처리 및 모델 병렬 처리 모두에서 성능을 최적화합니다.
TensorFlow에서 Horovod로 분산 학습을 설정할 때, 각 노드에서 동일한 데이터셋을 사용하지 않도록 데이터 샤딩을 적용하고, 모든 GPU에서 동일한 모델 파라미터를 동기화하는 방식으로 학습의 일관성을 유지합니다. 이를 통해 대규모 데이터를 처리하면서도 빠른 속도로 학습을 완료할 수 있는 구조를 마련했습니다.
Kubernetes 환경에서 분산 학습을 실행할 때는, Nvidia A100 GPU의 활용을 극대화하기 위해 Pod 간 GPU 자원 할당 및 최적화된 네트워크 설정을 통해 학습 중단을 최소화하고 GPU 사용률을 최대화합니다.
시장 기회 및 경쟁력
AI 기술의 발전과 더불어, 많은 기업들이 대형 언어 모델을 활용한 솔루션을 도입하고자 하지만, 막대한 연산 자원과 시간 소모가 커 상용화에 어려움을 겪고 있습니다. Deep Network는 최적화된 경량화 LLM 모델을 제공함으로써, 기업들이 더 적은 자원으로 고성능 AI 모델을 활용할 수 있도록 지원합니다.
특히 클라우드 기반 AI 학습 인프라를 사용하여, 고객들이 복잡한 AI 모델 학습을 더 쉽게 수행할 수 있도록 맞춤형 솔루션을 제공하는 경쟁력을 가지고 있습니다.
사업화 전략
경량화된 AI 모델 상용화: 기업들에게 경량화된 LLM 모델을 제공하여 비용 절감 및 성능 향상을 유도합니다.
클라우드 기반 AI 인프라 서비스: 기업들이 대규모 데이터를 효율적으로 처리할 수 있는 클라우드 인프라 및 학습 환경을 구축하고, 이에 대한 컨설팅 및 기술 지원 서비스를 제공합니다.
맞춤형 AI 솔루션 개발: 고객의 니즈에 맞는 커스텀 AI 모델 및 솔루션을 개발하여 다양한 산업 분야에 적용할 수 있도록 상용화 계획을 수립합니다.
투자 유치 계획
초기 투자 유치 목표: 경량화된 LLM 모델을 상용화하기 위한 초기 자금으로 약 5억 원을 목표로 설정하고, 이 자금을 활용하여 인프라 확장, 개발 인력 채용, 마케팅 및 고객 확장을 위한 활동에 집중할 계획입니다.
확장 가능성: Deep Network의 기술은 다양한 산업에 적용 가능하며, 특히 의료, 금융, 제조업 등 대규모 데이터를 처리하고 최적화된 AI 모델이 필요한 분야에서 높은 수요가 예상됩니다.
파트너십: 주요 클라우드 서비스 제공업체 및 AI 솔루션 기업과의 협력 관계를 통해 기술을 확장하고, 공동 프로젝트를 통해 시장을 넓혀갈 계획입니다.
미래 비전
Deep Network는 경량화된 AI 모델 및 솔루션을 바탕으로 AI 기술 상용화를 선도하는 기업으로 자리 잡고자 합니다. 더 나아가 고성능 AI 솔루션의 대중화를 통해 AI 기술을 필요로 하는 모든 산업군에 혁신을 제공하고, 글로벌 시장에서 경쟁력을 갖춘 기술 기업으로 성장하는 것이 목표입니다.
IT 분야 개발용역 기술 보유 일인 스타트업 딥네트워크의 기업 개요 및 보유 기술력을 소개 드립니다 ...
1. IT 분야 개발용역 기술 보유 일인 스타트업 딥네트워크의 기업 개요 및 비전
Deep Network는 주로 IoT 및 임베디드 시스템의 네트워크 통신과 관련된 커스터마이징 솔루션을 제공하는 IT 전문 스타트업입니다. 우리는 ESP32 WiFi 모듈을 활용하여 STM32H743 마이크로컨트롤러와의 연동 작업을 통해 다양한 네트워크 스택, 특히 LWIP(경량 IP 스택) 기반 소켓 통신 구현에 강점을 두고 있습니다. 우리의 비전은 임베디드 시스템의 네트워크 통신 최적화를 통해 다양한 산업에 맞춤형 솔루션을 제공하는 것입니다.
2. 핵심 역량
STM32 및 ESP32 통신 연동: STM32H743 마이크로컨트롤러와 ESP32 WiFi 모듈을 SPI 또는 UART 통신 방식으로 연동하여, LWIP 스택을 활용한 네트워크 소켓 통신을 성공적으로 구현할 수 있습니다.
LWIP 스택 커스터마이징: LWIP의 low_level_output() 및 low_level_input() 함수를 직접 수정하여 WiFi 모듈과의 데이터 송수신을 적절히 처리하는 커스터마이징 능력을 보유하고 있습니다. 이러한 경험을 바탕으로, 고객 맞춤형 네트워크 솔루션을 설계할 수 있습니다.
ESP32 모듈의 통신 방식 분석: ESP32의 AT 명령어 및 SPI/UART 통신 프로토콜을 기반으로 하는 네트워크 송수신 과정을 상세히 분석하고, 필요한 경우 소프트웨어 최적화를 진행하여 성능 향상을 도모합니다.
프로토타입 개발 경험: 우리는 여러 차례 프로토타입을 성공적으로 개발한 경험이 있으며, 이를 통해 고객이 요구하는 다양한 네트워크 솔루션을 빠르게 제공할 수 있습니다.
3. 세부 기술력: STM32H743과 ESP32 연동을 통한 LWIP 스택 커스터마이징
1) low_level_output() 함수: 데이터 송신 처리
low_level_output() 함수는 LWIP 스택에서 네트워크 데이터가 발생할 때 이를 ESP32 모듈로 송신하는 중요한 역할을 합니다. 우리는 이 함수를 수정하여 ESP32의 SPI 또는 UART 통신 프로토콜을 통해 데이터를 적절히 전송할 수 있도록 커스터마이징한 경험이 있습니다.
송신 방식: SPI 또는 UART를 통해 데이터 패킷을 ESP32에 전달하며, AT 명령어를 사용할 경우 명령어 구문을 적절히 생성하여 TCP 또는 UDP 데이터 전송이 가능하도록 설계하였습니다.
2) low_level_input() 함수: 데이터 수신 처리
low_level_input() 함수는 ESP32 모듈에서 수신한 네트워크 데이터를 LWIP 스택으로 전달하는 역할을 합니다. 이 함수 역시 SPI/UART를 통해 ESP32에서 수신한 데이터를 pbuf 구조체로 변환하여 LWIP에 전달하는 커스터마이징 작업을 수행하였습니다.
수신 방식: SPI나 UART 인터페이스로 데이터를 수신하고, +IPD 응답을 파싱하여 실질적인 데이터를 추출한 후, 이를 네트워크 스택에 적절히 전달하는 알고리즘을 구현했습니다.
4. ESP32 및 STM32 기반 네트워크 솔루션의 강점
ESP32 모듈의 비용 효율성: 중국산 ESP32 WiFi 모듈은 저렴한 가격 대비 우수한 성능을 제공하며, 이를 STM32와 연동하여 고객의 비용을 절감하면서도 안정적인 네트워크 솔루션을 구현할 수 있습니다.
소형 임베디드 시스템에 적합: ESP32 모듈과 STM32H743 마이크로컨트롤러의 결합은 전력 소모가 적고, 컴팩트한 설계로 IoT 디바이스와 같은 소형 임베디드 시스템에 적합합니다.
LWIP 기반 네트워크 스택의 유연성: LWIP는 경량 네트워크 스택으로, 자원이 제한된 임베디드 시스템에서 효율적으로 동작하며, 소켓 통신 및 HTTP 서버와 같은 다양한 네트워크 기능을 제공할 수 있습니다.
5. 현재의 한계와 해결 방안
양산 경험 부족: 현재까지는 대량 생산 경험이 없지만, 프로토타입을 성공적으로 개발한 경험을 바탕으로 향후 양산 대응이 가능합니다. 우리는 빠르게 양산을 준비하기 위한 기술적 로드맵을 가지고 있습니다.
상용화 실적 미비: 아직 상용화된 프로젝트는 없지만, 고객의 요구에 맞춘 맞춤형 솔루션을 제공할 수 있는 기술적 역량을 보유하고 있습니다. 투자 유치를 통해 실질적인 프로젝트를 상용화할 계획입니다.
6. 차별화된 경쟁력
Deep Network는 소규모 스타트업이지만, 특정 기술 분야에서 깊이 있는 분석 능력을 보유하고 있으며, 고객 요구에 맞춘 맞춤형 솔루션을 신속하게 제공할 수 있는 기민한 조직 구조를 가지고 있습니다.
고유 기술력: 우리는 ESP32와 STM32 연동을 통해 복잡한 네트워크 통신 문제를 해결하고, LWIP 스택을 최적화하는 커스터마이징 기술을 보유하고 있습니다.
비용 효율성: 대기업 대비 저렴한 비용으로 고성능 임베디드 네트워크 솔루션을 제공할 수 있으며, 이를 통해 고객의 비용 절감을 실현합니다.
빠른 대응 및 유연성: 고객의 요구사항 변화에 신속히 대응할 수 있으며, 문제 해결에 있어 높은 유연성을 보유하고 있습니다.
7. 시장 가능성
IoT 산업은 전 세계적으로 빠르게 성장하고 있으며, 네트워크 연결성을 가진 소형 디바이스에 대한 수요가 급증하고 있습니다. Deep Network는 이러한 수요를 충족시키기 위해 ESP32와 STM32 기반의 맞춤형 네트워크 솔루션을 제공할 수 있는 강점을 가지고 있습니다.
IoT 디바이스: 스마트 홈, 헬스케어, 산업용 IoT 시스템 등 다양한 분야에서 네트워크 연결성을 가진 디바이스의 수요가 급증하고 있습니다.
저전력 네트워크 솔루션: 에너지 절약이 중요한 산업에서는 ESP32와 같은 저전력 WiFi 모듈을 활용한 네트워크 솔루션이 더욱 중요해지고 있으며, 우리는 이러한 솔루션을 제공할 수 있는 준비가 되어 있습니다.
8. 향후 계획
프로토타입 개선 및 PoC 구현: 투자 유치를 통해 기존 프로토타입을 개선하고, Proof of Concept(PoC)를 완성하여 기술력을 증명할 계획입니다.
양산 준비: 성공적인 PoC 이후, 양산을 위한 기술적 준비와 고객 수요에 맞춘 대량 생산 대응을 목표로 하고 있습니다.
기술 개발 및 상용화: ESP32와 STM32 기반 네트워크 솔루션을 상용화하여 다양한 고객에게 맞춤형 네트워크 서비스를 제공할 계획입니다.
9. 기술 포트폴리오
LWIP 스택 커스터마이징: low_level_output() 및 low_level_input() 함수를 포함한 LWIP 스택을 ESP32와 STM32 간의 통신 환경에 맞게 최적화하는 커스터마이징 작업을 수행한 경험이 있습니다.
ESP32와 STM32 연동: SPI, UART 인터페이스를 통한 데이터 송수신 구현 및 AT 명령어 기반 통신 프로토콜 설계 경험을 보유하고 있습니다.
네트워크 소켓 통신 구현: 임베디드 시스템에서 안정적인 TCP/IP 소켓 통신을 구현할 수 있는 기술적 역량을 갖추고 있습니다.
10. 투자 유치 목적
Deep Network는 임베디드 네트워크 솔루션의 상용화를 목표로 투자 유치를 진행하고 있습니다. 투자 자금을 통해 다음과 같은 계획을 실행할 것입니다:
PoC 개발 완료: 현재 개발 중인 프로토타입을 개선하고, PoC를 완성하여 시장에 기술력을 입증.
기술 개발 가속화: 새로운 프로젝트와 양산 준비를 위한 기술 개발에 집중.
시장 진출 및 고객 확보: 상용화된 네트워크 솔루션을 통해 다양한 산업군의 고객을 확보하고, 안정적인 성장을 도모.
11. 결론
Deep Network는 ESP32와 STM32 기반의 네트워크 통신 솔루션에 특화된 기술을 보유한 IT 전문 스타트업입니다. 우리의 기술력은 소형 IoT 디바이스부터 산업용 네트워크 시스템에 이르기까지 다양한 솔루션을 제공할 수 있으며, 투자자와 함께 성장할 수 있는 가능성이 높습니다. 우리는 투자 유치를 통해 더 빠르게 상용화 및 양산을 실현하고, 글로벌 시장에서 경쟁력을 갖춘 스타트업으로 자리 잡을 것입니다.
IT 분야 개발용역 기술 보유 일인 스타트업 딥네트워크 장석원 sayhi7@daum.net 010-3350 6509 많은 IT 기업의 WIFI 통신 관련 저의 보유 기술 관련 개발용역 문의 연락 부탁드립니다 ...
AI(인공지능/딥러닝) 일인 스타트업 딥네트워크의 기업 개요 및 보유 기술력을 소개 드립니다 ....
1. 기업 개요 및 비전
Deep Network는 대규모 언어 모델(LLM)과 그 데이터셋 및 학습 알고리즘 분석에 초점을 맞춘 AI 스타트업입니다. 우리는 혁신적인 자연어 처리(NLP) 기술을 개발하고, 최적화된 Transformer 모델을 텐서플로우 환경에서 구현하는 데 강점을 가지고 있습니다. 우리의 목표는 차세대 AI 솔루션을 통해 다양한 산업 분야에 걸쳐 혁신을 주도하는 것입니다.
2. 세부 기술력: LLM 모델 경량화 설계 분석
1) LoRA 모델
LoRA(Low-Rank Adaptation)는 대규모 모델을 경량화하는 데 중점을 둔 기술로, 기존 모델에 추가 파라미터를 도입하지 않고도 성능을 극대화할 수 있는 방식입니다.
핵심 기술: LoRA는 사전 학습된 모델에 저차원 행렬을 추가하여 모델을 경량화하고, 이를 통해 적은 연산 자원으로도 높은 성능을 유지합니다.
분석 포인트: LoRA의 경량화 메커니즘이 얼마나 효율적으로 대규모 언어 모델의 파라미터를 줄이는지, 그리고 이 과정에서 발생하는 성능 손실을 최소화하는 알고리즘을 분석했습니다.
2) LLaMA 모델
LLaMA는 메타(Meta)에서 개발한 대규모 언어 모델로, 상대적으로 적은 자원으로 높은 성능을 낼 수 있는 모델입니다.
핵심 기술: LLaMA는 모델 파라미터를 줄이면서도 텍스트 생성 및 요약, 질의응답 등 다양한 작업에서 뛰어난 성능을 보이는 것이 특징입니다.
분석 포인트: LLaMA의 학습 데이터셋 구조 및 알고리즘 설계를 분석하여, 다른 대규모 언어 모델 대비 적은 파라미터로 높은 성능을 내는 비결을 심도 깊게 연구했습니다.
3) Gemma 모델
Gemma는 구글에서 개발한 대규모 언어 모델로, 학습 효율성과 모델 확장성에 중점을 둔 최신 기술입니다.
핵심 기술: Gemma는 모델의 경량화와 확장성을 모두 고려한 설계로, 데이터셋 효율성을 극대화하는 동시에 학습 시간과 자원을 절약하는 구조입니다.
분석 포인트: Gemma의 학습 알고리즘과 데이터셋 구조 분석을 통해, 모델이 빠르고 효율적으로 학습할 수 있는 방법을 연구했습니다.
3. 핵심 역량
LLM 모델 분석: 우리는 GPT, LLaMA와 같은 최신 언어 모델의 구조를 깊이 연구해왔으며, 이를 통해 복잡한 자연어 이해 및 생성 작업을 수행할 수 있는 능력을 보유하고 있습니다.
TensorFlow 기반 모델 구현: 텐서플로우 환경에서 Transformer 모델의 세부 구현 경험을 통해, 성능 최적화와 모델 효율성을 극대화할 수 있는 기술적 역량을 보유하고 있습니다.
학습 알고리즘 최적화: 다양한 학습 알고리즘을 분석하여 여러 작업을 동시에 처리할 수 있는 멀티태스킹 학습 환경을 구축하는 데 능숙합니다.
데이터셋 구조 분석: 우리는 자연어 처리와 관련된 다양한 데이터셋을 분석하여 모델의 성능을 극대화하는 데 필요한 세부적인 구조를 이해하고 이를 개선하는 경험을 보유하고 있습니다.
고유 기술력: LoRA, LLaMA, Gemma와 같은 최신 경량화 모델 분석 경험을 바탕으로, 대규모 언어 모델을 최적화하는 기술을 보유하고 있습니다.
4. 현재의 한계와 해결 방안
PoC(Proof of Concept) 구현 미완료: 현재 자금 부족으로 PoC 결과물은 구현하지 못했지만, 이미 철저한 모델 분석과 연구를 바탕으로 향후 단기간에 결과물을 낼 수 있는 기반을 마련해두었습니다.
상용화 경험 부족: 상용화 경험이 다소 부족하다는 점은 인정하지만, 이를 보완하기 위해 상용화 프로세스를 빠르게 학습하고, 다양한 분야에서 AI 솔루션을 개발하여 테스트하는 계획을 갖고 있습니다.
5. 차별화된 경쟁력
Deep Network는 기존의 대기업이나 학계 출신 전문가들과는 다른 독창적인 접근법을 가지고 있습니다. 우리는 실질적인 연구와 실험을 바탕으로 한 심층적인 기술 분석을 통해, 상용화된 AI 솔루션보다 더욱 유연하고 고도화된 맞춤형 솔루션을 제공할 수 있습니다.
유연성: 대기업과 달리, 우리는 빠르게 변화하는 기술 트렌드에 대응할 수 있는 유연한 구조를 갖추고 있습니다.
독창성: 기존의 상용화된 솔루션이 아닌, 맞춤형 AI 기술을 통해 고객의 특수한 요구에 부합하는 솔루션을 제안할 수 있습니다.
6. 시장 가능성
AI 산업은 매년 기하급수적으로 성장하고 있으며, 특히 자연어 처리 및 생성 분야는 그 중에서도 가장 빠르게 발전하는 분야입니다. Deep Network는 이러한 급성장하는 시장에서 차별화된 기술력을 바탕으로 중요한 역할을 할 수 있습니다.
언어 모델 상용화: 최신 GPT 모델들을 기반으로 한 다양한 상업용 애플리케이션이 시장에서 폭발적인 수요를 일으키고 있습니다. 우리는 이러한 수요에 대응할 준비가 되어 있습니다.
산업 확장성: 금융, 헬스케어, 교육 등 다양한 분야에서 자연어 처리 기술의 수요가 급증하고 있으며, 우리는 이러한 분야에 맞춤형 솔루션을 제공할 수 있는 준비가 되어 있습니다.
7. 향후 계획
PoC 개발: 투자 유치를 통해 단기간 내에 PoC 결과물을 출시할 예정입니다. 이를 통해 우리의 기술적 역량을 검증하고, 상용화를 위한 구체적인 로드맵을 제시할 것입니다.
기술 고도화: LoRA, LLaMA, Gemma와 같은 경량화 모델의 설계 구조를 더 깊이 연구하고, 이를 응용할 수 있는 추가 기술을 개발할 계획입니다.
파트너십 확대: 다양한 산업 분야의 기업들과의 파트너십을 통해, 우리가 보유한 AI 기술을 실제 비즈니스 문제 해결에 적용하는 것을 목표로 하고 있습니다.
상용화 및 수익화: 개발된 솔루션을 상용화하여 수익을 창출할 계획입니다. 특히 금융, 헬스케어, 고객 서비스 자동화 등 고부가가치 산업에 AI 솔루션을 도입하여 가치를 증대시킬 것입니다.
8. 기술 포트폴리오
TensorFlow 기반 AI 모델: TensorFlow에서 직접 구현한 LLM 및 Transformer 모델의 기술력을 보유하고 있습니다.
자연어 처리(NLP): 다양한 자연어 처리 작업에 대한 심도 깊은 연구 및 성능 최적화 경험을 통해 실질적인 AI 솔루션을 제공할 수 있습니다.
멀티태스킹 학습: 하나의 모델이 여러 작업을 처리할 수 있도록 하는 멀티태스킹 학습 기술을 통해 AI 모델의 효율성을 높이고 있습니다.
9. 투자 유치 목적
Deep Network는 기술력을 바탕으로 성장 가능성이 높은 AI 시장에서 경쟁력을 강화하고, 빠르게 상용화할 수 있는 AI 솔루션을 개발하기 위해 투자 유치를 목표로 하고 있습니다. 투자를 통해 다음과 같은 구체적인 계획을 실행할 것입니다:
PoC 구현: 실질적인 PoC 결과물을 출시하여 시장에서 기술력을 입증.
기술 개발 가속화: 최신 연구 동향을 반영한 기술 개발을 가속화.
마케팅 및 고객 확보: 상용화된 AI 솔루션을 빠르게 확산시키기 위한 마케팅 전략을 구축하고 초기 고객을 확보.
10. 결론
Deep Network는 단순한 기술 연구에 그치지 않고, 실제 비즈니스 문제를 해결하는 AI 솔루션을 제공할 수 있는 능력을 갖춘 유망한 스타트업입니다. 우리는 투자자의 신뢰를 바탕으로 한 단계 더 나아가, AI 시장에서 중요한 플레이어로 자리 잡고자 합니다.
AI(인공지능/딥러닝) 일인 스타트업 딥네트워크 장석원 sayhi7@daum.net 010-3350 6509 많은 AI(인공지능/딥러닝) 모델 세부 구조 연구 및 구현 관련 많은 연락 기다리겠읍니다 ...
내가 운영하는 딥네트워크의 Bluetooth 5.1 기술력 소개: 1 : N 무선 통신 기술력 소개
저희 기업은 Bluetooth 5.1 기술을 활용한 1:20 무선 통신 솔루션을 개발하여, 20개 이상의 TX 모듈과 1개의 RX 모듈이 효율적으로 통신하는 시스템을 제공합니다. 이 솔루션은 저전력 설계 및 Nordic Bluetooth 5.1 칩셋을 기반으로, 고성능 센서 네트워크 구축이 가능합니다. TX 모듈에는 온도 센서가 부착되어 있으며, RX 모듈은 다수의 센서 데이터를 통합하여 UART를 통해 디스플레이 모듈로 전송합니다.
기술 개요
목적: RX 모듈이 20개의 TX 모듈로부터 데이터를 실시간으로 수집하고, 저전력 모드에서 효율적인 통신을 유지.
TX 모듈: BLE Advertising을 통해 RX 모듈과 연결, 주기적으로 온도 데이터를 송신.
RX 모듈: Multi-link Central 기능을 통해 최대 20개의 TX 모듈과 동시에 연결 및 데이터 수신, 처리.
주요 절차 및 방법
페어링 및 연결 유지
RX 모듈은 BLE 스캔 기능을 통해 주변의 TX 모듈을 검색합니다.
BLE_GAP_EVT_ADV_REPORT 이벤트가 발생하면, RX 모듈은 광고 패킷에서 TX 모듈의 주소 및 서비스 정보를 확인합니다.
RX 모듈은 sd_ble_gap_connect() API를 사용하여 최대 20개의 TX 모듈과 순차적으로 연결을 시도합니다.
각 연결은 Connection Parameters로 설정된 최소/최대 연결 주기, 슬레이브 지연시간 등을 기반으로 안정적으로 관리됩니다.
다중 연결 관리
Nordic SDK의 Multi-link Central 예제를 기반으로, RX 모듈은 동시에 20개의 TX 모듈과 연결을 유지합니다.
각 연결에 대해 BLE_CONN_HANDLE_INVALID를 통해 연결 핸들을 관리하고, BLE_GAP_EVT_CONNECTED 이벤트로 연결 상태를 모니터링합니다.
연결된 모든 TX 모듈에서 송신되는 Notification 이벤트를 RX 모듈에서 처리하여, 데이터를 연속적으로 수신합니다.
데이터 수집 및 처리
각 TX 모듈은 정기적으로 Notification을 통해 온도 데이터를 RX 모듈로 송신합니다.
RX 모듈은 ble_nus_data_send() API를 통해 수신한 데이터를 UART를 통해 외부 디스플레이 모듈로 전송합니다.
모든 데이터는 FIFO 구조로 처리되어 실시간 데이터 통합이 가능하며, 데이터 수집 간격과 동기화가 최적화됩니다.
저전력 최적화
BLE 5.1의 저전력 특성을 적극 활용하여, 각 TX 모듈은 수십 μA의 전력을 소모하며, RX 모듈도 최적화된 전력 관리 기법을 통해 수백 μA 수준의 전력 소모를 유지합니다.
Connection Interval 및 Slave Latency 설정을 통해 전력 소모를 최소화하면서도 안정적인 데이터 통신을 보장합니다.
전력 소모 측정
저희 솔루션은 BLE 통신 주기와 저전력 모드에 따른 전력 소모량을 실시간으로 모니터링하며, TX 모듈의 전력 소모는 50ms 주기에서 수십 μA에서 수 mA 사이로, RX 모듈은 수백 μA에서 수 mA 수준의 소모를 유지합니다.
전력 측정 도구를 통해 BLE 통신 중 발생하는 전력 소모를 분석하여 배터리 수명 최적화를 지원합니다.
확장성 및 유연성
Nordic SDK 기반의 커스터마이징이 가능하여, 추가적인 센서 모듈 및 통신 모듈을 손쉽게 통합할 수 있습니다.
적용 분야
산업용 센서 네트워크: 다수의 온도, 습도, 가스 센서를 통합한 모니터링 시스템.
헬스케어: 여러 환자의 바이오 데이터를 실시간으로 수집하여 중앙 모니터링 시스템으로 전송.
스마트 홈: 다수의 IoT 장치를 제어하는 통합 스마트 네트워크 구축.
저희 기업은
Bluetooth 5.1 통신 기술을 통해 다수의 장치와의 안정적이고 효율적인 연결을 구현하며, 다양한 산업군에서 활용 가능한 맞춤형 솔루션을 제공합니다.
[STM32H743][중국 WIFI ESP32 적용][LWIP 스택을 적용해 STM32H743 SPI / UART 로 소켓 송수신 구현 세부 노하우 기술자료 판매 합니다]
판매 가격은 협의 가능하고 확실한 기술 노하우 자료를 [STM32H743] [중국 WIFI ESP32 적용] [LWIP 스택을 적용해 SPI / UART 로 소켓 송수신 구현 세부 노하우 기술자료 판매 합니다] LWIP 스택을 적용해 SPI / UART 로 소켓 송수신 구현시 소스의 어느 어느 부분을 어떻게 수정해야 동작되는지 설명한 자료 입니다 ...
딥네트워크 장석원 010-3350 6509 sayhi7@daum.net 으로 세부 문의 주세요
나도 IT 업계에 몸을 담은지 30 년 이다 ... 이해하실지 모르겠지만 저같은 경우도 사업을 하는 최종 목표가 내 회사 솔루션을 가지고 그것으로 매출을 내는 일 일것이다 ... 그동안 제가 최근 10 년간 개인사업자로 개발용역 일을 할때 가장 많은 연락을 받은 부분이 이런 이슈가 안되니 단기간 해결 가능하냐는 연락 입니다 .... 뭐가 안된다라는 연락은 대부분 제품 납품과정 즉 양산 대응 과정에서 해결 안되는 이슈를 해결 가능하냐는 연락 입니다 ... 이런 재품 납품과정 내지 양산 대응 이슈의 경우 운이 좋으면 간단히 해결될수도 있지만 대부분 99 % 는 원천기술을 요구하는 경우 즉 초 고난도로 난해한 기술 이슈가 대부분이다 ... 의뢰업체가 원천기술이 부족해서 이런 기술이슈를 해결해 달라는 말은 쉽게 할수 있어도 이런 원천 기술 이슈는 그냥 호락 호락 해결이 되는 그런 건 들이 아니기에 원천 기술 해결 이슈가 처리하기가 더 난해하고 힘이 많이 든다 ... 이런 연락이 제일 난해한게 뭐냐하면 자기네가 시간도 있는대로 다 까먹고 거기에 개발 자금도 거의 소진 됬을때 연락이 와서 거의 꽁짜로 원천기술을 개발해 달라고 하니 난감하지 않을수 없다 ... 그렇다고 저 같은 소기업이 그런 핵심 이슈 해결이 가능한 원천기술을 다 보유하기도 사실상 불가능한데 저같은 소기업한테 자기네 원천기술 이슈 해결 가능하냐는 연락을 하려면 최소한 어느 정도 합당한 개발 기간 이라도 보장해 주고 해 달라고 해야 하는것 아닌가 싶읍니다 ... 요즘은 경기가 최악이라 일꺼리가 예년에 비해 1/10 혹은 1/20 로 확 줄었다고 합니다 ... 다들 살기 어려운것은 이해 하지만 그래도 서로 도와 가면서 같이 협력해서 일하자가 맞는것 같은데 제가 무리한 생각 인가요 ?
이러한 방식으로 ICP 식각은 고해상도의 정밀한 패턴을 웨이퍼에 형성할 수 있으며, 반도체 제조에서 중요한 역할을 합니다.
EUV (Extreme Ultraviolet) 노광 후 PR (Photoresist) 위에 ALD (Atomic Layer Deposition)로 증착하는 보호층 또는 마스크층이 식각 공정에서 PR을 보호하는 이유와 그 중요성에 대해 다음과 같이 설명할 수 있습니다.
1. PR 패턴 보호의 필요성
1.1. 식각 공정에서의 PR 손상 방지
정밀한 패턴 유지: 식각 공정은 웨이퍼 표면의 PR 패턴을 제거하여 기판에 원하는 회로 구조를 형성하는 과정입니다. PR은 매우 미세한 패턴을 형성하기 위해 사용되며, 이 패턴이 정확하게 유지되어야 합니다. PR이 직접 식각 용액이나 플라즈마에 노출되면, 패턴이 손상되거나 왜곡될 수 있습니다. ALD로 증착된 보호층은 PR을 식각 공정에서의 화학적, 물리적 공격으로부터 보호하여 패턴의 정밀도를 유지합니다.
1.2. 화학적 저항성 제공
식각 용액에 대한 보호: 식각 공정에서 사용되는 용액이나 가스는 매우 강한 화학적 물질을 포함할 수 있습니다. ALD로 증착된 보호층은 이러한 화학물질에 대한 저항성을 제공하여 PR의 패턴이 식각 공정 동안 손상되지 않도록 합니다. 이는 PR의 화학적 손상이나 부식으로부터 보호하는 역할을 합니다.
1.3. 기계적 보호
물리적 손상 방지: 식각 공정 중에는 플라즈마, 용액의 흐름, 또는 기계적 마찰로 인해 PR의 패턴이 물리적으로 손상될 수 있습니다. ALD로 형성된 보호층은 PR 표면을 물리적으로 감싸 보호하여 이러한 손상으로부터 방어합니다.
2. PR 보호의 중요성
2.1. 제조 품질과 신뢰성 유지
정밀한 회로 형성: 반도체 제조 공정에서는 나노미터 단위의 정밀도가 요구됩니다. PR 패턴의 정확한 형성은 회로의 기능성과 성능에 직결됩니다. PR이 손상되면 회로의 전기적 특성이나 기능이 영향을 받을 수 있으며, 이는 전체 디바이스의 신뢰성을 저하시킬 수 있습니다.
2.2. 공정 수율 향상
결함 방지: PR 패턴이 손상되면 제조 공정에서 결함이 발생할 수 있으며, 이는 불량 제품을 초래하고 공정 수율을 낮출 수 있습니다. 보호층이 PR을 잘 보호하면 공정 중 결함 발생 가능성을 줄이고, 전체적인 제조 수율을 향상시킬 수 있습니다.
2.3. 고해상도 패턴 구현
미세 패턴의 유지: 최신 반도체 제조에서는 매우 미세한 패턴이 필요합니다. ALD로 증착된 보호층은 PR의 미세한 패턴을 정확히 유지하여, 고해상도 패턴을 구현할 수 있도록 지원합니다. 이는 특히 3나노미터와 같은 초미세 공정에서 더욱 중요합니다.
3. ALD로 보호층을 증착하는 설계와 원리
3.1. ALD 공정 원리
원자 단위 증착: ALD는 원자 단위로 박막을 증착하는 기술로, 매우 얇고 균일한 층을 형성할 수 있습니다. 각 사이클마다 전구체가 웨이퍼의 표면과 반응하여 원자 단위의 박막을 형성하고, 잔여물을 제거하여 정밀한 두께 조절이 가능합니다.
정밀 제어: ALD 공정은 두 가지 전구체를 교대로 주입하여 표면에 정밀하게 증착하며, 각 사이클 후 세척 과정을 거쳐 박막의 품질을 유지합니다.
3.2. ALD 장비의 설계 구조
챔버 디자인: ALD 챔버는 높은 진공 상태를 유지하며, 기체 전구체의 균일한 주입과 분포를 보장합니다. 일반적으로 웨이퍼는 회전 장치와 같은 구조로 균일하게 증착됩니다.
기체 공급 시스템: 기체 전구체는 정밀하게 주입되며, 유량과 농도가 조절됩니다. 플라즈마를 사용하여 반응성을 높이거나, 증착 속도를 조절할 수 있습니다.
3.3. ALD로 형성된 보호층의 기능
화학적 방어: ALD로 형성된 보호층은 높은 화학적 저항성을 제공하여 식각 공정 중 PR을 보호합니다.
물리적 보호: 균일하게 증착된 보호층은 PR 표면을 기계적 손상으로부터 보호하며, 식각 공정의 정확성을 높입니다.
결론
EUV 노광 후 PR 위에 ALD로 증착하는 보호층은 식각 공정에서 PR을 보호하는 데 필수적입니다. 이는 PR의 패턴이 손상되지 않도록 하여, 제조 공정의 정밀도와 신뢰성을 유지하고 공정 수율을 향상시키며 고해상도의 패턴을 구현할 수 있게 합니다. ALD의 원자 단위 증착 기술을 통해 매우 정밀한 보호층을 형성하여, PR 패턴을 효과적으로 보호하는 것이 중요합니다.
ALD (Atomic Layer Deposition)로 증착된 보호층이 포토마스크에 적용되는 과정과, 이 보호층이 식각 공정에서 3 나노미터의 미세 회로 패턴을 어떻게 유지하는지 설명하겠습니다. 이 과정은 크게 증착 공정과 식각 공정으로 나눌 수 있습니다.
1. 포토마스크의 역할
1.1. 포토마스크의 정의와 기능
포토마스크: 포토마스크는 반도체 제조 공정에서 패턴을 웨이퍼에 전사하는 역할을 하는 장치입니다. 포토마스크의 표면에는 반도체 회로의 패턴이 형성되어 있으며, 이 패턴은 광학적으로 웨이퍼에 전사됩니다.
패턴 전사: 포토마스크는 노광 공정에서 EUV(Extreme Ultraviolet) 또는 DUV(Deep Ultraviolet) 광선을 이용해 웨이퍼의 포토레지스트(PR)에 패턴을 전사합니다. 이 과정에서 포토마스크는 패턴의 물리적인 형상에 따라 빛을 통과시키거나 차단하여 웨이퍼에 원하는 패턴을 형성합니다.
2. 포토마스크의 한계
2.1. 포토마스크의 물리적 성질
비활성 물질: 포토마스크는 일반적으로 유리나 석영으로 만들어지며, 그 표면에는 금속 또는 크롬 등의 물질로 패턴이 형성되어 있습니다. 이러한 재료는 반도체 소자의 전기적 특성이나 동작을 위한 전도성 물질이 아닙니다.
회로 동작 없음: 포토마스크는 전기적 특성을 가지지 않으며, 전류를 흐르거나 반도체 소자의 기능을 수행하지 않습니다. 따라서 포토마스크는 회로를 실제로 동작시키는 데 필요한 전자적 기능을 갖추고 있지 않습니다.
2.2. 에칭과 포토마스크
에칭 공정: 포토마스크는 식각(etching) 공정을 통해 패턴을 제거하거나 변경하지 않습니다. 에칭 공정은 주로 웨이퍼에서 포토레지스트 또는 보호층을 제거하거나 회로를 형성하기 위해 사용됩니다.
포토마스크의 소모: 포토마스크는 일반적으로 소모되지 않으며, 여러 번 재사용될 수 있습니다. 에칭 공정 후에도 포토마스크는 물리적 손상 없이 원래의 패턴을 유지하며, 같은 공정을 반복할 수 있습니다.
3. 포토마스크와 반도체 회로
3.1. 웨이퍼의 역할
회로 형성: 포토마스크에서 전사된 패턴은 웨이퍼의 포토레지스트에 의해 인식되고, 이후 식각 공정이나 기타 공정을 통해 웨이퍼에 실제 반도체 회로가 형성됩니다.
반도체 소자: 반도체 소자는 웨이퍼의 실질적인 회로 부분에 해당하며, 전기적 동작을 통해 신호를 처리하거나 저장하는 기능을 수행합니다.
결론
포토마스크는 반도체 제조 공정에서 패턴을 전사하는 중요한 역할을 하지만, 자체적으로 반도체 회로로 동작하지 않습니다. 포토마스크는 회로의 패턴을 웨이퍼에 전사하는 역할만 하며, 실제 회로 동작은 웨이퍼에서 이루어집니다. 포토마스크는 물리적인 패턴 형성을 위한 도구로서 사용되며, 전기적 동작과는 무관합니다.
딥네트워크 장석원 010-3350 6509 sayhi7@daum.net 많은 문의 부탁드립니다 ...
요즘 IT 정보통신 인공지능 업계 세상살이를 이야기해 보려 합니다 ... 저도 그동안 한 5 년간 인공지능 분야 / 위성통신 분야 / 휴머노이드 로봇 분야 등등의 세부 노하우 파악을 위해 각각의 분야별로 최소 1 년에서 5 년까지 인터넷상의 수백가지 세부 기술정보 분석을 했었읍니다 ... 이렇게 제가 노력을 해보면서 깨닭은 점은 세부 기술들을 85 점 정도까지는 인터넷 상의 세부 기술정보 분석으로 파악이 가능한데 문제는 나머지 15 점 모자르는것은 어떻게 채워야 하느냐 입니다 ... 가장 좋은 방법은 자금 확보에 성공하면 나름 해결방안 마련이 용이해 집니다 ... 15 점 모자르는것은 결국 돈 이 준비가 안되 있으면 해결이 어렵다는것 입니다 ... 이 돈 이라는게 15 점 모자르는것을 메꿔 넣으려면 내 기업에서 시간과 자금 과 인력을 투입해서 시행착오를 겪지 않으면 15 점 모자르는것은 채우는게 사실상 불가능하다는것 입니다 ... 그러면 15 점 채우는게 가능하려면 ... 강남의 학부모들이 다들 자기 자녀 SKY 대 입학시키려고 하지 않읍니까 ? 15 점 모자르는것 채우는게 결국 돈 인데 한국이든 미국이든 내가 힘 있는 IT 업계 기득권 세력이 되야 돈도 투자 받을수 있다는것 이구요 ... 그래서 SKY 대 인맥 형성도 필요하고 IVY 리그 대학 인맥도 그래서 필요하다는것 이지요 ... 내가 힘 있는 IT 기득권 세력이 되면 15 점 모자르는것 채우는것도 훨씬 여러가지 방안 마련이 가능해 진다는거구요 ... 그런데 꼭 IT 기득권이 아니어도 15 점 모자르는것을 채울수는 있읍니다 ... 기득권 세력들은 1 년 걸린다면 나는 5 배 정도의 노력 즉 한 5 년 정도는 노력을 해야 이의 해결이 가능하다는거구요 ... 이렇게 애기하니 뭐 기득권 세력도 이런것들이 쉽게 된다는것은 아니지만 그래도 유리하다는것은 다들 인정 하실겁니다 ... 이제까지 애기한 15 점 모자른다는게 결국은 원천기술 확보 거든요 ... 원천기술 확보도 결국 자금력 있는 사람은 기술력 있는기업을 M & A 하면 되거든요 ... 그래서 제가 돈 돈 돈 하는거구요 ... 돈이 없으면 시행착오를 해야 하는데 이 시행착오도 결국 돈이 있어야 가능하구요 ... 저도 올해 나이 60 이지 않읍니까 ? IT 분야 일 경험을 거의 30 년 했거든요 ... 제가 겪어보니 그렇더군요 ... 대기업 이건 중소기업 이건 자기네가 크던 작던 어떤 솔루션 개발시 몇가지 이슈가 해결안되면 당연히 저 같으면 기본적으로 드는 생각이 자금과 시간을 충분히 투입 가능하게 준비하는게 기본 아니겠읍니까 ? 제가 최근에도 대기업 이건 중소기업이건 이런 이슈 해결 문제를 해결해줄 해결사를 구해서 해결하자로 결론이 나구요 ... 니가 이런 이슈 경험이 있으면 몇 억들어야 할것을 단기간에 해결 못 한다고 하면 니가 능력이 없는것 아니냐가 그들의 입장 이더라구요 ... 이건 대기업 이건 중소기업 이건 똑 같더라구요 ... 요즘 나라 경제도 최악인데 다들 돈 안들이고 코 플 생각만 하니 저같은 소기업은 어디 기댈때가 전혀 없거든요 ... 제가 요즘 어려운 것도 이 15 점 모자르는것 즉 원천 기술확보가 부족해서 이렇게 돈벌이가 힘들거든요 ... 당장 자금 확보가 어려우니 원천 기술 확보도 그리 쉬운게 아니고 진짜 앞이 안 보이거든요 ... 자금 확보가 어려 우니 자본주의 사회에서 뭔가 이루기가 그리 만만치 않거든요 ... 그래서 자금확보는 어렵더라도 우선 저 혼자힘으로 좀 더 파고들어 원천 기술 확보를 위해 시간투자하는것 말고 제가 할수 있는것은 거의 없읍니다 ... 하 참 쉬운게 하나도 없네요 ... 다들 이렇게 하시나요 ?
스마트폰의 자동 초점 (Auto Focus) 및 OIS (Optical Image Stabilization) 제어 알고리즘 분석 전문 딥네트워크 입니다 ...
ON Semiconductor의 LC898123AXD는 자동 초점(Auto Focus) 및 광학 이미지 안정화(OIS)를 모두 지원하는 드라이버 IC입니다. 이 칩셋의 제어 알고리즘 원리와 설계 구조를 상세히 설명하면 다음과 같습니다:
자동 초점 (Auto Focus)
자동 초점 기능은 이미지 센서에서 얻은 데이터를 기반으로 렌즈의 위치를 조정하여 최적의 초점을 맞추는 기술입니다. LC898123AXD는 다음과 같은 원리로 작동합니다:
위상 검출: 이미지 센서에서 위상 검출(PDAF, Phase Detection Auto Focus) 기술을 사용하여 초점을 맞추기 위한 위치 정보를 얻습니다.
센서 데이터 처리: 이미지 센서에서 수집된 데이터를 실시간으로 처리하여 현재 초점 상태를 분석합니다.
모터 구동 제어: LC898123AXD는 렌즈 모터(일반적으로 보이스 코일 모터, VCM)를 제어하여 렌즈의 위치를 미세하게 조정합니다. 이를 위해 피드백 루프를 사용하여 정확한 위치 제어를 수행합니다.
최적 초점 결정: 이미지의 명확성과 선명도를 분석하여 최적의 초점 위치를 결정하고, 모터를 구동하여 그 위치로 렌즈를 이동시킵니다.
광학 이미지 안정화 (Optical Image Stabilization)
광학 이미지 안정화 기능은 카메라가 흔들릴 때 이미지 센서와 렌즈의 움직임을 보정하여 이미지의 흔들림을 최소화하는 기술입니다. LC898123AXD의 OIS 기능은 다음과 같은 원리로 작동합니다:
자이로 센서 데이터 수집: 카메라 모듈에 내장된 자이로 센서에서 각속도 데이터를 수집합니다. 이 데이터는 카메라의 회전 및 움직임을 실시간으로 측정합니다.
제어 알고리즘: 수집된 자이로 센서 데이터를 바탕으로, 카메라의 움직임을 예측하고 보정하기 위한 제어 알고리즘이 실행됩니다. 이 알고리즘은 일반적으로 PID(비례-적분-미분) 제어를 포함한 다양한 제어 기법을 사용합니다.
보상 신호 생성: 제어 알고리즘은 렌즈나 이미지 센서를 보정하기 위한 보상 신호를 생성합니다.
모터 구동 제어: LC898123AXD는 OIS 보상 신호를 기반으로 렌즈 또는 이미지 센서의 위치를 조정합니다. 이를 위해 액추에이터(일반적으로 VCM 또는 MEMS 기반)를 제어하여 흔들림을 보정합니다.
실시간 피드백: 피드백 루프를 통해 실시간으로 보정 효과를 모니터링하고, 필요한 경우 추가 보정을 수행합니다.
설계 구조
LC898123AXD는 다음과 같은 주요 블록들로 구성되어 있습니다:
MCU (Microcontroller Unit): 내부에 마이크로컨트롤러를 포함하여 제어 알고리즘을 실행합니다.
모터 드라이버: VCM 또는 MEMS 액추에이터를 제어하는 드라이버 회로를 포함합니다.
센서 인터페이스: 이미지 센서 및 자이로 센서와의 인터페이스를 제공하여 데이터를 수집하고 처리합니다.
전력 관리: 효율적인 전력 소모를 위해 전력 관리 기능을 포함합니다.
LC898123AXD는 PDAF를 통한 자동 초점 및 자이로 센서를 통한 OIS를 지원하며, 각각의 기능을 위해 정교한 제어 알고리즘과 피드백 루프를 사용합니다. 이를 통해 고품질의 이미지 촬영을 가능하게 합니다.
위상 검출 자동 초점(PDAF, Phase Detection Auto Focus)은 이미지 센서에서 특정 패턴을 감지하고 이를 통해 렌즈의 초점을 맞추기 위한 정보를 얻는 기술입니다. LC898123AXD와 같은 드라이버 IC는 이러한 정보를 처리하여 렌즈 위치를 제어합니다. PDAF의 알고리즘 원리와 설계 구조를 설명하면 다음과 같습니다:
PDAF의 원리
위상 검출 자동 초점은 이미지 센서의 픽셀 중 일부를 위상 검출 픽셀(Phase Detection Pixels)로 활용하여 초점을 맞추는 방법입니다. 이 픽셀들은 센서의 특정 위치에 배치되어 있습니다.
위상 검출 픽셀의 역할: PDAF 픽셀은 렌즈의 특정 부분을 통해 들어오는 빛을 두 개의 이미지로 분리합니다. 이 두 이미지는 초점이 맞았을 때 완벽하게 일치합니다. 하지만 초점이 맞지 않으면 두 이미지가 서로 어긋나게 됩니다.
위상 차이 계산: 센서는 이 두 이미지 간의 위상 차이를 측정합니다. 이 위상 차이는 렌즈의 현재 위치와 초점이 맞는 위치 간의 차이를 나타냅니다. 위상 차이는 픽셀 단위로 측정되며, 이를 통해 렌즈를 얼마나 이동시켜야 하는지 계산할 수 있습니다.
초점 이동 결정: 위상 차이를 바탕으로 렌즈가 어느 방향으로 얼마나 이동해야 하는지 결정합니다. 이 과정은 매우 빠르게 이루어져야 하며, 일반적으로 여러 단계의 계산을 통해 정확한 위치를 찾습니다.
알고리즘 원리
PDAF 알고리즘은 다음과 같은 단계를 거쳐 초점을 맞춥니다:
데이터 수집: 위상 검출 픽셀에서 얻은 두 개의 이미지를 센서로부터 읽어들입니다.
위상 차이 계산: 두 이미지 간의 위상 차이를 계산합니다. 이는 주로 상관 함수(correlation function)를 사용하여 두 이미지 간의 이동량을 찾는 방식으로 이루어집니다.
위상 차이 분석: 위상 차이를 분석하여 현재 초점 상태를 평가합니다. 예를 들어, 위상 차이가 클수록 초점이 많이 어긋나 있는 상태를 나타냅니다.
렌즈 이동 명령 생성: 위상 차이 정보를 바탕으로 렌즈를 어느 방향으로 얼마나 이동시킬지 결정합니다. 이를 위해 제어 알고리즘이 사용됩니다. 일반적으로 PID(비례-적분-미분) 제어 알고리즘이 적용됩니다.
렌즈 위치 조정: LC898123AXD는 결정된 이동 명령에 따라 렌즈의 위치를 조정합니다. 이 과정에서 피드백 루프를 사용하여 정확한 위치 제어를 합니다.
설계 구조
PDAF를 지원하는 이미지 센서와 LC898123AXD의 설계 구조는 다음과 같습니다:
위상 검출 픽셀 배열: 이미지 센서에는 일반 픽셀과 함께 위상 검출 픽셀이 배열되어 있습니다. 이 픽셀들은 주로 센서의 중앙 또는 일정 간격으로 배치됩니다.
센서 인터페이스: LC898123AXD는 이미지 센서와 인터페이스하여 위상 검출 픽셀에서 데이터를 수집합니다. 이 인터페이스는 고속으로 데이터를 전송할 수 있어야 합니다.
데이터 처리 유닛: 수집된 데이터를 실시간으로 처리하여 위상 차이를 계산하는 유닛이 포함됩니다. 이는 내장된 MCU 또는 DSP를 통해 이루어집니다.
제어 알고리즘 실행: 위상 차이를 기반으로 렌즈 이동 명령을 생성하는 제어 알고리즘이 실행됩니다. 이 알고리즘은 정확한 렌즈 위치 제어를 위해 다양한 제어 기법을 사용합니다.
모터 드라이버: 렌즈를 이동시키기 위한 모터 드라이버가 내장되어 있습니다. 이 드라이버는 VCM 또는 MEMS 액추에이터를 제어하여 렌즈를 정확한 위치로 이동시킵니다.
PDAF 기술은 위상 검출 픽셀을 사용하여 렌즈의 초점 상태를 실시간으로 평가하고, 이를 바탕으로 렌즈를 이동시켜 초점을 맞추는 방식으로 작동합니다. LC898123AXD는 이러한 과정을 고속으로 처리하여 정확하고 신속한 자동 초점 기능을 제공합니다. 이를 위해 데이터 수집, 위상 차이 계산, 제어 알고리즘 실행, 모터 제어 등의 단계가 유기적으로 결합된 설계 구조를 가지고 있습니다.
PDAF(위상 검출 자동 초점) 알고리즘에서 두 이미지 간의 위상 차이를 계산하고, 상관 함수(correlation function)를 사용하여 이동량을 찾는 방식은 다음과 같은 관련성을 가지며, 이러한 설계 구조와 원리가 사용되는 이유를 설명하면 다음과 같습니다:
두 이미지 간의 위상 차이 계산
두 이미지 간의 위상 차이를 계산하는 과정은 이미지 센서의 위상 검출 픽셀(Phase Detection Pixels)이 생성하는 두 이미지를 비교하여 이루어집니다. 위상 차이는 다음과 같은 방식으로 계산됩니다:
이미지 획득: 이미지 센서의 위상 검출 픽셀은 렌즈를 통해 들어오는 빛을 두 개의 서로 다른 이미지로 분리합니다. 예를 들어, 하나는 왼쪽 이미지, 다른 하나는 오른쪽 이미지로 분리됩니다.
초기 상태: 초점이 맞지 않은 상태에서는 이 두 이미지가 서로 어긋나 있습니다. 초점이 맞을수록 두 이미지가 정렬됩니다.
위상 차이 계산: 두 이미지가 얼마나 어긋나 있는지를 계산합니다. 이는 두 이미지의 각 픽셀 값의 차이를 비교하여 계산할 수 있습니다. 이를 통해 현재 초점이 맞지 않는 정도를 수치적으로 표현할 수 있습니다.
관련성과 설계 구조의 이유
정확한 초점 결정: 상관 함수는 두 이미지 간의 유사성을 최대화하는 방향으로 이동량을 결정하므로, 초점을 매우 정확하게 맞출 수 있습니다. 이는 매우 작은 차이도 감지할 수 있어 고해상도의 초점을 제공합니다.
빠른 계산: 상관 함수는 수학적으로 효율적인 방법으로 두 이미지 간의 이동량을 계산할 수 있어, 실시간으로 빠르게 초점을 맞출 수 있습니다. 이는 PDAF의 장점 중 하나인 빠른 초점 맞추기를 가능하게 합니다.
강인성: 상관 함수를 사용하는 방식은 노이즈에 강하고, 다양한 조명 조건에서도 안정적으로 작동할 수 있습니다. 이는 실제 촬영 환경에서 안정적인 초점 맞추기를 보장합니다.
결론
PDAF 알고리즘에서 두 이미지 간의 위상 차이를 상관 함수를 사용하여 계산하는 것은, 정확하고 빠른 초점 맞추기를 위한 핵심 원리입니다. 상관 함수는 두 이미지 간의 유사성을 측정하여 최적의 이동량을 결정하고, 이를 통해 렌즈를 적절하게 조정하여 초점을 맞춥니다. 이러한 설계 구조와 원리는 PDAF가 고속의 정확한 자동 초점 기능을 제공할 수 있게 합니다.
딥네트워크 장석원 010-3350 6509 sayhi7@daum.net 개발협력 관련 많은 문의 부탁드립니다 ....
X-ray 입사: X-ray 소스에서 발생한 X-ray가 대상에 투사되고, 대상에서 X-ray가 CsI(Tl) scintillator로 전달됩니다.
Scintillator에서의 변환: CsI(Tl) scintillator는 X-ray를 가시광선으로 변환합니다. CsI(Tl) scintillator의 구조적 특성 덕분에 X-ray는 높은 효율로 가시광선으로 변환됩니다.
광선 감지: Xineos-2329의 CMOS 센서가 CsI(Tl) scintillator에서 방출된 가시광선을 감지합니다. 각 픽셀은 이 가시광선을 전기 신호로 변환합니다.
신호 처리: CMOS 센서에서 생성된 전기 신호는 ADC(Analog-to-Digital Converter)를 통해 디지털 신호로 변환됩니다. 이 디지털 신호는 이미지 데이터로 처리됩니다.
이미지 재구성: 디지털 데이터는 최종적으로 이미지 처리 유닛에서 재구성되어, 고해상도의 X-ray 이미지로 출력됩니다.
Scintillator 는 X-ray, 감마선, 입자선 등 고에너지 방사선을 감지하고, 이를 가시광선 또는 다른 낮은 에너지 형태의 빛으로 변환하는 물질입니다. Scintillator는 다음과 같은 특징과 용도로 사용됩니다:
주요 역할과 기능
방사선 감지:
Scintillator는 방사선을 흡수하고 그 에너지를 가시광선으로 변환합니다. 이 가시광선은 이후 광전자 증배관(PMT)이나 CMOS 센서 등 다른 장치에 의해 감지됩니다.
에너지 변환:
Scintillator는 고에너지 방사선(예: X-ray, 감마선)을 저에너지 빛으로 변환합니다. 이 과정은 방사선 이미징, 검출 및 측정에서 중요한 역할을 합니다.
고속 응답:
Scintillator는 매우 빠르게 응답하며, 높은 방사선 감도와 낮은 후광 시간(빛을 방출한 후 남아있는 시간)을 제공합니다. 이는 빠르게 변화하는 방사선 신호를 정확히 감지하는 데 도움을 줍니다.
구성 및 소재
구성 물질: Scintillator는 특정한 화학 물질이나 결정을 포함합니다. 이러한 물질에는 다양한 유형이 있으며, 각기 다른 방사선 감도와 응답 특성을 가지고 있습니다. 예를 들어, CsI(Tl) (Thallium-doped Cesium Iodide), NaI(Tl) (Thallium-doped Sodium Iodide), BGO (Bismuth Germanate) 등이 있습니다.
기능 원리: Scintillator 내의 원자는 고에너지 방사선이 들어오면 전자들이 들뜨게 되어 가시광선 형태로 에너지를 방출합니다. 이 가시광선은 다른 감지 장치로 전달되어 측정됩니다.
용도
의료 이미징:
X-ray 디지털 검출기: Scintillator는 X-ray를 가시광선으로 변환하여 디지털 이미지 센서가 이를 감지하고 처리할 수 있도록 합니다.
비파괴 검사: Scintillator는 산업에서 금속, 용접 부위, 구조물 등을 검사하는 데 사용됩니다.
물리 실험:
입자 물리학: Scintillator는 고에너지 입자를 감지하는 데 사용됩니다.
예시
CsI(Tl): Thallium-doped Cesium Iodide, 주로 X-ray 디지털 검출기에서 사용됩니다.
NaI(Tl): Thallium-doped Sodium Iodide, 방사선 측정 및 의료 이미징에서 널리 사용됩니다.
BGO: Bismuth Germanate, 주로 고에너지 물리학 실험에서 사용됩니다.
요약: Scintillator는 고에너지 방사선을 감지하여 이를 가시광선으로 변환하는 물질로, 다양한 분야에서 방사선 감지 및 이미징에 사용됩니다.
Teledyne DALSA의 Xineos-2329 검출기와 Saint-Gobain의 CsI(Tl) scintillator는 함께 작동하여 X-ray 이미징을 수행합니다. 검출기 내부의 CMOS 센서와 CsI(Tl) scintillator의 상호작용은 다음과 같은 구조와 과정을 통해 이루어집니다.
Xineos-2329 검출기와 CsI(Tl) Scintillator의 연동 동작
1. CsI(Tl) Scintillator의 역할
X-ray 변환: CsI(Tl) scintillator는 X-ray를 가시광선으로 변환하는 역할을 합니다. CsI(Tl)에서 X-ray가 입사하면, CsI(Tl) 물질 내에서 X-ray 포톤이 가시광선 포톤으로 변환됩니다. CsI(Tl)의 columnar 구조는 X-ray의 광선을 최소한으로 산란시키며 높은 해상도를 제공합니다.
물질의 특성: CsI(Tl)은 높은 X-ray 감도와 낮은 후광 시간으로 알려져 있어, 빠르고 정밀한 X-ray 이미징에 적합합니다.
전기 신호 변환: CMOS 센서에서 감지된 가시광선은 각 픽셀의 전기 신호로 변환됩니다. 이 신호는 이미지의 밝기와 색상 정보를 포함합니다.
3. 통합된 동작 구조
X-ray 입사: X-ray 소스에서 발생한 X-ray가 대상에 투사되고, 대상에서 X-ray가 CsI(Tl) scintillator로 전달됩니다.
Scintillator에서의 변환: CsI(Tl) scintillator는 X-ray를 가시광선으로 변환합니다. CsI(Tl) scintillator의 구조적 특성 덕분에 X-ray는 높은 효율로 가시광선으로 변환됩니다.
광선 감지: Xineos-2329의 CMOS 센서가 CsI(Tl) scintillator에서 방출된 가시광선을 감지합니다. 각 픽셀은 이 가시광선을 전기 신호로 변환합니다.
신호 처리: CMOS 센서에서 생성된 전기 신호는 ADC(Analog-to-Digital Converter)를 통해 디지털 신호로 변환됩니다. 이 디지털 신호는 이미지 데이터로 처리됩니다.
이미지 재구성: 디지털 데이터는 최종적으로 이미지 처리 유닛에서 재구성되어, 고해상도의 X-ray 이미지로 출력됩니다.
구체적인 연동 방식
Scintillator의 장착: CsI(Tl) scintillator는 Xineos-2329 검출기의 상단에 장착됩니다. 검출기 설계에 따라, CsI(Tl)은 검출기의 광학 창과 정확히 맞물려야 하며, 이를 통해 방출된 가시광선이 CMOS 센서로 잘 전달될 수 있도록 합니다.
광선 전달: CsI(Tl) scintillator에서 방출된 가시광선은 검출기 내의 광학 설계에 의해 CMOS 센서의 표면으로 전달됩니다. 이 과정에서 가시광선이 센서의 픽셀 배열에 고르게 분포되도록 보장합니다.
센서 감도 조정: CMOS 센서의 감도와 후광 시간은 CsI(Tl) scintillator의 특성과 맞물려 조정됩니다. 이 조정은 X-ray 이미징의 정확성과 해상도를 보장하는 데 중요합니다.
종합
Teledyne DALSA의 Xineos-2329 검출기와 Saint-Gobain의 CsI(Tl) scintillator는 서로 밀접하게 연동되어 X-ray 이미지를 생성합니다. CsI(Tl) scintillator가 X-ray를 가시광선으로 변환하고, Xineos-2329의 CMOS 센서가 이 가시광선을 감지하여 디지털 이미지로 변환하는 구조로 작동합니다. 이 통합된 시스템은 고해상도의 정확한 X-ray 이미지를 제공하며, 의료 및 산업 분야에서 정밀한 검사와 진단을 가능하게 합니다.
딥네트워크 장석원 010-3350 6509 sayhi7@daum.net 개발협력 관련 많은 문의 부탁드립니다 ....
제가 운영하는 딥네트워크가 보유한 원자력 발전소등 방사선 검출 시스템 구현 노하우를 소개드립니다 ...
실리콘 광전자 증배관(SiPM)은 고체 상태의 장치로, 매우 작은 크기와 높은 감도를 가지며, 섬광 물질과 결합하여 방사선을 검출할 수 있습니다. 주로 사용되는 섬광 물질은 나트륨 요오드화물(NaI(Tl)), BGO (비스무트 게르마늄 산화물), LYSO (루테튬 이트륨 실리케이트) 등이 있습니다. 이 물질들은 방사선을 흡수하여 빛(광자)을 방출합니다. SiPM은 방출된 광자를 감지하여 전기 신호로 변환하는 역할을 합니다. 이를 위해 섬광 물질과 SiPM을 최대한 가까이 배치하여 효율적으로 광자를 감지할 수 있도록 합니다. 섬광 물질과 SiPM 사이에 광결합을 최적화하기 위해 광학 접착제나 광학 젤을 사용합니다. 이는 광자의 손실을 최소화하고, 최대한 많은 광자가 SiPM에 도달하도록 돕습니다. 감마 방사선 검출 시스템에서 에너지 스펙트럼 분석은 방사성 동위원소 식별과 방사선 강도 측정에 필수적입니다. FFT는 신호 처리의 효율성을 높이고, 노이즈를 제거하며, 주파수 성분을 분석하여 정확한 에너지 스펙트럼을 제공할 수 있습니다.
콤프턴 에지는 콤프턴 산란 스펙트럼에서 관찰되는 중요한 특징으로, 감마선 광자가 전자와 산란될 때 최대 에너지를 가진 산란된 광자가 나타나는 지점입니다. 이 지점은 감마선의 에너지가 전자와의 상호작용에서 거의 모두 소모되었을 때 발생하며, 에너지 스펙트럼에서 급격한 감소로 나타납니다.
FFT(빠른 푸리에 변환)를 사용하여 스펙트럼 데이터를 분석할 때, 다음과 같은 사항을 고려할 수 있습니다:
주파수 스펙트럼의 변화: FFT를 통해 변환된 스펙트럼에서 특정 주파수 성분이 뚜렷하게 나타날 수 있습니다. 콤프턴 에지는 에너지 스펙트럼에서 급격한 감소를 보이는 지점으로, 이는 FFT 결과의 주파수 스펙트럼에서 일정 부분의 에너지가 급격하게 감소하는 지점으로 해석될 수 있습니다. 이 주파수 성분은 콤프턴 에지가 나타나는 에너지에 대응할 수 있습니다.
에너지 스펙트럼의 특성: 콤프턴 에지는 에너지 스펙트럼에서 급격한 감소를 보이므로, FFT를 통해 얻은 주파수 성분에서 이런 급격한 변화를 관찰할 수 있습니다. FFT 결과의 스펙트럼에서 특정 주파수에서의 에너지 강도가 급격히 감소하는 부분이 콤프턴 에지와 연관될 수 있습니다.
스펙트럼 분석: FFT를 통해 얻은 스펙트럼 데이터에서 에너지 스펙트럼의 주요 특징, 즉 급격한 감소를 나타내는 주파수 성분을 식별하고 분석하는 것이 중요합니다. 이를 통해 콤프턴 에지가 발생하는 에너지 범위를 확인할 수 있습니다.
결론적으로, FFT를 사용한 스펙트럼 데이터 분석에서 콤프턴 에지는 에너지 스펙트럼의 급격한 감소와 관련된 주파수 성분의 변화로 나타날 수 있으며, 이를 통해 콤프턴 에지가 나타나는 에너지 범위를 파악할 수 있습니다.
딥네트워크 장석원 010-3350 6509 sayhi7@daum.net 으로 많은 개발협력 문의 부탁드립니다 ....
나도 올해 나이 60 입니다 ... 일인기업을 운영하고 있는데 최근 너무 경기가 안 좋아 IT 분야 개발 및 자문 관련 문의 자체가 아예 없읍니다 ... 상황이 이렇다 보니 사업자로 일감 수주 자체가 아예 안되는 상황 이다 보니 할수없이 구직을 해서라도 벌이를 하려고 이력서를 꽤 많이 넣었구요 ... 물론 중소기업 대표분들도 저같이 사업 운영이 쉽지 않으니 요즘 위기중 위기 상황인것은 이해 합니다 ... 저 같은 경우 저도 일인기업을 10 년 넘게 운영하다 보니 중소기업 대표분들이나 중역분들과 상당히 많은 개발이슈 협의도 그동안 많이 진행했었구요 ... 저도 구직을 하게 된것도 경제가 워낙 어려우니 도대체가 개발 협의 문의가 없다 보니 이력서를 넣어 취직 이라도 해보려 하는것 이거든요 ... 최근에도 몇군데 면접을 봤었는데 ... 중소기업 대표나 경영진은 이력서를 접수하면 이력서를 세세히 보기는 하는지 궁금해 집니다 ... 제출한 이력서 내용으로 구인 회사측 경영진이 검토시 현재 구인 회사의 이슈 해결이 가능할지 충분히 판단이 가능하다고 저는 보는데 ... 같이 할 여지가 없을것 같으면 면접 연락을 안하면 서로가 좋을것 같읍니다 ... 괜히 면접때 불러 놓고 이게 안맞고 저게 안맞고 따지는 식으로 또는 구인회사측의 무리한 요구를 협의하자는 면접진행보다는 구인회사와 부합하는 이력서 해당자를 불러 서로 협조적으로 면접진행이 더 합리적 진행 아니겠읍니까 ? 구직자의 이력서가 구인회사와 부합하지 않으면 아예 부르지 않는게 예의라고 저는 판단하거든요 ... 서로 경기가 바닥이라 최악의 상황인데 면접을 나는 갑 이니 내 식 대로 면접 진행하면 되지 뭐가 문제냐 하는식의 진행 방식은 구직자를 너무 괴롭히는 그런 면접 진행인것 같읍니다 ... 좀 더 부연 설명드리자면 요즘 중소기업들 그동안 몇달간 일 진행하다가 뭔가가 문제가 있어서 해결 가능한 사람을 찾으려고 구인공고를 내고 면접을 보지 않읍니까 ? 그러면 구인 회사도 자기네가 그동안 몇달간 이슈해결이 안되면 당연히 다른 방안으로 해결이 가능한가를 검토해야 하는데 ... 그동안 몇달간 이 방식으로 처리했으니 구인회사측에서 자기네 방식이 맞다고 면접시 고집을 하니 진짜 문제 해결을 원하는건지 면접자 불러서 화풀이를 하는건지 헤깔립니다 ... 만약 제가 대표라면 그동안 이슈 해결이 잘 안됬다면 당연히 다른 방안이 있는지 부터 협의를 할것 같읍니다 ... 자기네 일이 잘 안된다고 구직자에게 화풀이 할것이 아니라 구직자가 어떤 해결방안이 있을지도 모르니 좀 더 타협적으로 잘 안풀리는 이슈를 협의하는게 맞는게 아닌가 십습니다 .... 경기가 어려우니 다들 남에 대한 배려는 눈꼽 만큼도 안하는 시대인것 같아 너무 씁쓸 합니다 ...
제가 그 동안 약 1 년간 분석작업을 진행해 온 GNSS Driver 의 경우 GNSS Manager로부터 요청받은 작업(위성 신호 수신, 위상 추정, 데이터 처리 등)을 수행하고 그 결과를 반환하기 위해서는 일반적으로 다음과 같은 동작 구조로 설계됩니다:
위성 신호 수신:
하드웨어 제어: GNSS Driver는 하드웨어와의 저수준 통신을 통해 실제 GNSS 신호를 수신합니다. 이 과정에서는 안테나와 연결된 전자적 신호를 해석하고 디지털화하여 GNSS 수신기로 전송합니다.
시간 동기화: GNSS Driver는 수신된 신호의 시간 정보를 정밀하게 동기화하여 정확한 시간 기준 하에서 신호를 처리합니다. 이는 GNSS 시스템의 시간 체계와 Android 시스템의 시간 체계를 동기화하는 것을 포함할 수 있습니다.
위상 추정:
디지털 신호 처리: GNSS Driver는 수신된 신호를 디지털 신호 처리 기법을 사용하여 분석합니다. 이 과정에서는 위상 측정, 신호 세기 측정 등의 처리가 수행됩니다.
위상 추정 알고리즘: 다양한 알고리즘을 사용하여 신호의 위상을 추정합니다. 예를 들어, FFT(고속 푸리에 변환)를 이용한 위상 추정이나, PLL(위상 잠금 루프)을 이용한 위상 추정 등이 있습니다.
데이터 처리:
위상 및 데이터 분석: 추정된 위상과 다른 관련 데이터(예: 도착 시간, PRN 코드 등)를 분석하여 위치 계산에 필요한 정보를 생성합니다.
위성 신호 해독: PRN 코드를 해독하고, 다중 경로 간섭(Multipath Interference) 처리 등의 추가적인 데이터 처리를 수행합니다.
결과 반환:
정확성 보장: GNSS Driver는 GNSS Manager에게 정확하고 신속하게 처리된 데이터를 반환하여, 위치 서비스에 필요한 정확한 위치 정보를 제공합니다.
상태 보고: 필요에 따라 GNSS 수신기의 상태를 보고하여, 시스템 내에서 GNSS 기능의 안정성을 유지하고 문제를 식별하는 데 도움을 줍니다.
이러한 동작 구조를 통해 GNSS Driver는 GNSS Manager가 요청하는 작업을 효율적으로 수행하고, 안정적이고 정확한 위치 측정 서비스를 Android 시스템에 제공할 수 있습니다. GNSS Driver의 설계는 하드웨어의 특성과 GNSS 신호 처리의 복잡성을 고려하여 최적화되어야 합니다. 관련해서 세부 노하우 분석이 되 있으니 협의후 개발 진행 및 자문 진행이 가능 합니다 ...
딥네트워크 장석원 010-3350 6509 sayhi7@daum.net 으로 개발 및 자문 문의 부탁드립니다 ....
로라통신 디바이스단 / 게이트웨이단 프로토타입 펌웨어 개발 Semtech SX1276 으로 가능 합니다 ... 귀사 요구에 맞춰 최대한 시간을 맞춰서 프로토타입 개발 진행이 가능 합니다 ... Semtech 회사 사이트에서 SX1276 에서 다운로드 받은 펌웨어 세부 분석이 되있어서 최대한 빠른 기간내 펌웨어 개발 진행이 가능 합니다 ... 저는 지역이 수원 이고 맡겨 주시면 확실하게 결과물 내는것이 가능합니다 ...
LoRA (Long Range)는 저전력 광역 네트워크 (LPWAN) 기술로, 장거리 통신과 저전력 소비를 가능하게 하는 무선통신 방식입니다. LoRA 시스템은 크게 네 부분으로 나뉩니다: 디바이스단, 게이트웨이단, 네트웍 서버단, 그리고 어플리케이션 서버단. 각 부분의 구현 기술에 대해 상세히 설명드리겠습니다.
LoRa Gateway Uplink: radio packets 는 gateway 에 의해 수신된다 , 그리고 Gateway 에 의해 메터데이터가 더해지고 여기에 Gateway Status 정보가 더해져서 Network Server 로 forward 처리된다. LoRa Gateway Downlink: Network Server 에 의해 패킷이 생성되고 , 부가적인 메터데이터를 포함될수 있고, 또한 Gateway 의 Configuration Data 도 포함되서 Gateway 의 Radio Channel 로 Transmit 된다
SemTech 사가 공개하는 디바이스단의 펌웨어 소스는 ClassA/B/C end-device 구현시 Periodically uplinks a frame 은 the Cayenne LPP protocol 을 사용한다. Cayenne Low Power Payload (LPP) 은 편리하고 쉬운 방안을 제공해서 LoRaWAN 같은 LPWAN networks 로 데이터를 Send 를 구현한다 ... Cayenne LPP 는 payload size restriction 이 있다 11 bytes 보다 적은 수 만 한번에 센서 데이터들을 LoRa 디바이스가 Send 하는것을 허용한다.
로라통신의 보안 메커니즘에서, MAC( Message Authentication Code )은 메시지의 위변조를 확인하기 위해 쓰이는 보안 기술 입니다. CMAC은 알고리즘과 모드 에 따라 AES CBC-MAC 메커니즘이 있구요 ... CMAC 도 마찬가지로 주된 기능은 사용자 인증(authentication)과 데이터 무결성(data integerity) 처리를 위한것 입니다 ... MAC 은 MAC 을 만들때 Block 함수를 사용하면 CMAC( Cipher-based Message Authentication Code )가 됩니다 ...
SX1301 칩셋을 사용하여 LoRa 게이트웨이에서의 주요 기능을 구현하는 방법을 이해하기 위해, 각 기능과 관련된 레지스터 설정을 상세히 설명하겠습니다. SX1301은 LoRaWAN 네트워크의 핵심 구성 요소로서, 디바이스와 네트워크 서버 간의 통신을 관리합니다.
LoRa 게이트웨이의 핵심 역할과 SX1301의 레지스터 설정
신호 수신 및 송신
역할: LoRa 디바이스로부터 신호를 수신하고, 네트워크 서버로 데이터를 송신합니다.
제어 레지스터: REG_OP_MODE, REG_PACONFIG, REG_RFLR_PADAC, REG_HOP_PERIOD
수신 모드 설정: REG_OP_MODE 레지스터에서 수신 모드를 설정합니다. 이 레지스터의 값에 따라 칩셋이 수신 모드로 작동하도록 설정할 수 있습니다.
송신 모드 설정: REG_OP_MODE 레지스터의 설정을 통해 송신 모드로 전환합니다.
주파수 설정: REG_FRF_MSB, REG_FRF_MID, REG_FRF_LSB 레지스터를 통해 주파수를 설정합니다. 이 레지스터들에 대해 원하는 주파수 값을 설정하여, 송신 및 수신 주파수를 조정합니다.
출력 전력 설정: REG_PACONFIG, REG_RFLR_PADAC 레지스터를 사용하여 송신 전력을 설정합니다.
프레임 복조 및 디코딩
역할: 수신된 LoRa 프레임을 복조하고 디코딩하여 네트워크 서버에 전달할 수 있는 데이터로 변환합니다.
제어 레지스터: REG_MODEM_CONFIG1, REG_MODEM_CONFIG2, REG_DETECTION_OPTIMIZE, REG_DETECTION_THRESHOLD
복조 방식 설정: REG_MODEM_CONFIG1 및 REG_MODEM_CONFIG2 레지스터를 통해 모듈레이션 방식, 대역폭, 코드율 등을 설정합니다.
프레임 검출 설정: REG_DETECTION_OPTIMIZE, REG_DETECTION_THRESHOLD 레지스터를 사용하여 패킷의 신호 검출 임계값을 조정합니다.
네트워크 서버와의 통신
역할: 수신한 데이터를 네트워크 서버에 전송하고, 네트워크 서버의 명령을 디바이스에 전달합니다.
제어 레지스터: REG_FIFO, REG_FIFO_ADDR_PTR, REG_FIFO_TX_BASE_ADDR
패킷 전송: REG_FIFO 레지스터를 통해 송신할 데이터 패킷을 FIFO에 쓰고, 송신 작업을 시작합니다.
패킷 수신: REG_FIFO 레지스터를 통해 수신된 패킷을 읽어들입니다. REG_FIFO_ADDR_PTR 레지스터를 사용하여 읽을 데이터의 위치를 지정합니다.
패킷 처리 및 필터링
역할: 수신된 패킷을 필터링하고, 오류가 있거나 불필요한 패킷을 제거합니다.
제어 레지스터: REG_PKT_SNR_VALUE, REG_PKT_RSSI_VALUE, REG_RX_NB_BYTES
패킷 필터링: REG_PKT_SNR_VALUE와 REG_PKT_RSSI_VALUE 레지스터를 통해 패킷의 신호 대 잡음비(SNR)와 수신 신호 세기(RSSI)를 모니터링하여 유효한 패킷을 필터링합니다.
패킷 길이 설정: REG_RX_NB_BYTES 레지스터를 통해 수신할 패킷의 길이를 설정합니다.
주파수 동기화 및 시간 동기화
역할: LoRa 디바이스와의 주파수 및 시간 동기화를 통해 정확한 데이터 전송 및 수신을 보장합니다.
제어 레지스터: REG_SYNC_WORD, REG_HOP_PERIOD
동기화 단어 설정: REG_SYNC_WORD 레지스터를 사용하여 동기화 단어를 설정합니다. 이 단어는 디바이스와의 통신에서 동기화를 보장합니다.
주파수 홉 설정: REG_HOP_PERIOD 레지스터를 통해 주파수 홉 주기를 설정하여 동기화의 정확성을 높입니다.
결론
SX1301 칩셋의 각 레지스터는 LoRa 게이트웨이의 핵심 기능을 구현하는 데 중요한 역할을 합니다. 신호 수신 및 송신, 프레임 복조 및 디코딩, 네트워크 서버와의 통신, 패킷 처리 및 필터링, 주파수 및 시간 동기화는 모두 이러한 레지스터 설정을 통해 효과적으로 수행됩니다. 이들 레지스터를 적절히 제어함으로써, 게이트웨이는 LoRaWAN 네트워크의 원활한 운영을 지원합니다.
LoRa 게이트웨이는 LoRa 패킷을 IP 패킷으로 변환하여 네트워크 서버로 전송하고, 네트워크 서버에서 받은 IP 패킷을 LoRa 패킷으로 변환하여 LoRa 디바이스로 전송합니다. 이 과정은 게이트웨이의 소프트웨어와 네트워크 구조에 의해 관리됩니다. 상세한 송수신 구조와 방식을 설명하겠습니다.
1. LoRa 패킷을 IP 패킷으로 변환하여 네트워크 서버로 전송하는 과정
구조와 방식
LoRa 패킷 수신
SX1301 역할: LoRa 디바이스에서 수신된 무선 신호를 디지털 데이터로 복조합니다.
레지스터: REG_FIFO, REG_FIFO_ADDR_PTR를 통해 수신된 패킷 데이터를 읽습니다.
패킷 처리
게이트웨이 애플리케이션 프로세서:
수신 데이터의 디코딩: SX1301에서 받은 데이터를 애플리케이션 프로세서가 해석합니다. 데이터는 LoRaWAN 프로토콜에 따라 포맷이 지정되어 있습니다.
LoRaWAN 데이터의 IP 패킷화: 디코딩된 LoRaWAN 데이터와 메타데이터를 IP 패킷으로 변환합니다. 이 과정에서는 LoRaWAN 프로토콜에서 IP 패킷 포맷으로 데이터를 변환하는 작업이 필요합니다. 일반적으로 MQTT, HTTP, UDP 등 IP 프로토콜을 사용하여 네트워크 서버와 통신합니다.
네트워크 서버로 전송
전송 프로토콜:
MQTT: LoRaWAN 게이트웨이는 MQTT 프로토콜을 사용하여 IP 패킷을 네트워크 서버로 전송합니다. MQTT는 메시지 브로커를 통해 IP 패킷을 전송하는 방식입니다.
HTTP/HTTPS: HTTP API를 통해 IP 패킷을 POST 요청으로 전송합니다.
UDP: UDP 패킷을 통해 IP 패킷을 전송합니다.
2. 네트워크 서버에서 받은 IP 패킷을 LoRa 패킷으로 변환하여 디바이스로 전송하는 과정
구조와 방식
IP 패킷 수신
네트워크 서버 역할: IP 네트워크를 통해 LoRa 게이트웨이로 IP 패킷을 전달합니다.
IP 패킷 처리
네트워크 서버 소프트웨어:
IP 패킷 디코딩: 네트워크 서버는 IP 패킷에서 LoRaWAN 데이터와 메타데이터를 추출합니다. 이 데이터는 특정 디바이스로 전송될 메시지와 명령을 포함하고 있습니다.
LoRa 패킷 변환
게이트웨이 소프트웨어:
LoRaWAN 데이터 포맷: IP 패킷의 데이터를 LoRaWAN 프레임으로 변환합니다. 여기서는 LoRaWAN 프로토콜에 맞게 데이터 포맷을 재구성합니다.
패킷 송신: REG_FIFO, REG_FIFO_ADDR_PTR, REG_FIFO_TX_BASE_ADDR 레지스터를 사용하여 LoRa 패킷을 FIFO 버퍼에 작성합니다. 이후, REG_OP_MODE 레지스터를 통해 송신 모드를 활성화하여 패킷을 송신합니다.
무선 송신: SX1301은 설정된 주파수와 송신 전력으로 패킷을 무선으로 전송합니다.
요약
LoRa 패킷 → IP 패킷:
SX1301: LoRa 신호를 디지털 데이터로 변환.
게이트웨이 애플리케이션 프로세서: 데이터 디코딩 및 IP 패킷화.
게이트웨이 소프트웨어: IP 패킷 전송 (MQTT, HTTP, UDP).
IP 패킷 → LoRa 패킷:
네트워크 서버: IP 패킷을 디코딩.
게이트웨이 소프트웨어: LoRaWAN 데이터 포맷으로 변환.
SX1301: LoRa 패킷 송신.
이와 같은 구조와 방식으로, LoRa 게이트웨이는 LoRa 디바이스와 네트워크 서버 간의 데이터 송수신을 원활하게 처리합니다.
로라통신은 스마트팜 구현분야에 적용 가능하고 각종 데이터 송수신시 이 데이터들의 보안처리가 중요한 이슈이기에 로라통신에는 AES-CMAC 보안 알고리즘으로 동작하게 규격문서가 그렇게 설계되 있구요 ... 저는 로라통신에 적용되는 암호화/복호화 알고리즘 설계 기술을 확실하게 확보 성공했읍니다 ... 이 부분 감안해서 장거리 저전력 무선통신 로라통신 펌웨어 개발이 가능 합니다 ...
딥네트워크 장석원 010 3350 6509 sayhi7@daum.net 으로 로라통신 펌웨어 개발 문의 부탁드립니다
- 위상배열안테나 어레이 와 Phase Shifter 를 적용해 위상배열안테나로 송출시 각각의 Phase Shifter 의 위상을 제어해서 위상배열안테나 어레이 전체의 조향각 제어 알고리즘 수식 확보 성공 ...
- 위상배열안테나 어레이 와 Phase Shifter 를 적용해 위상배열안테나로 송출시 위상배열안테나 어레이 각각의 제어이득 조절을 돌프 체비세프 위도우를 적용해 Main Lobe 와 Side Lobe 의 감쇄 이득 조절을 위한 제어 알고리즘 수식 확보 성공
- 송신 측에서 8 GHz 주파수 대역을 사용하여 16QAM으로 변조한 신호는 수신 측에서 IF 주파수로 변환되더라도, 변조된 정보(데이터)는 변하지 않습니다. 변환된 IF 신호는 8 GHz에서 변조된 신호와 동일한 데이터를 포함하고 있으며, 이를 이용해 수신 측에서 변복조 과정을 수행하여 원래의 데이터를 복원하는 노하우 확보 성공.
- 위성 데이터 송수신을 위해 16QAM 변조 및 복조 알고리즘이 필요한데 이것의 동작 알고리즘 수식 확보 성공 ....
- 위성데이터 송수신시 송수신 데이터가 오류가 있을때 오류가 난 데이터를 보정해주는 FEC 에러 보정 알고리즘 수식 확보 성공
16QAM(16 Quadrature Amplitude Modulation) 변조 신호가 수신 측에서 IF(Intermediate Frequency) 주파수로 변환되더라도 변조된 정보가 왜 변하지 않는지 이해하기 위해서는 주파수 변환의 기본 원리와 16QAM 변조 방식을 자세히 살펴볼 필요가 있습니다. 또한 RF 하드웨어 설계와 펌웨어 구현 방법을 각각 5가지 핵심 사항으로 상세히 설명하겠습니다.
1. 16QAM 변조 신호의 정보 보존
주파수 변환의 원리
변조 신호: 16QAM은 디지털 데이터를 16개의 서로 다른 심볼로 변조합니다. 각 심볼은 I(인페이즈)와 Q(쿼드라처) 성분의 조합으로 표현됩니다. 변조된 신호는 고주파수 대역(예: 8 GHz)에서 전송됩니다.
주파수 변환: RF 신호를 IF 주파수로 변환할 때, 주파수 변환 과정은 신호의 정보 자체를 변경하지 않습니다. 단지 신호의 주파수 대역을 이동시키는 과정입니다. RF 신호와 로컬 오실레이터(LO) 신호를 믹서에서 혼합하여 IF 신호를 생성합니다.
변조된 정보의 유지
신호의 일관성: 16QAM 신호에서 정보는 I/Q 평면상의 심볼 패턴에 의해 정의됩니다. 주파수 변환은 신호의 이러한 심볼 패턴을 변형하지 않고, 단순히 신호의 주파수 대역을 이동시킵니다.
정보 전송: 변환된 IF 신호는 원래의 변조 정보와 동일한 I/Q 평면상의 패턴을 유지하므로, 원래의 데이터는 IF 신호에서 변하지 않고 그대로 유지됩니다.
Wilkinson Power Divider를 이용한 8x8 위상배열안테나 어레이 설계와 구현 - 딥네트워크는 안테나 어레이 설계시 RF 전력 급전 회로망 설계 부분도 다음과 같이 검토가 됬읍니다 ...
위상 배열 안테나 시스템에서 Wilkinson Power Divider를 사용하여 병렬 및 직렬 급전 회로망을 설계하는 방법을 설명합니다.
1. Wilkinson Power Divider의 역할
Wilkinson Power Divider는 신호를 여러 경로로 균등하게 분배하고, 각 경로 간의 전기적 고립을 보장하는 데 사용됩니다. 이는 위상 배열 안테나에서 신호 분배에 필수적입니다.
2. 8x8 위상 배열 안테나 개요
8x8 위상 배열 안테나는 64개의 개별 안테나 요소로 구성되며, 각각의 요소는 특정 위상과 전력을 가지도록 조절됩니다. 이를 통해 빔의 방향과 형태를 제어할 수 있습니다.
병렬 급전 회로망 설계
병렬 급전 회로망은 모든 안테나 요소에 동일한 전력과 위상으로 신호를 분배하는 방식입니다. 다음은 병렬 급전 회로망의 설계와 구현 단계입니다:
1단계: Wilkinson Power Divider 사용
첫 번째 Wilkinson Power Divider는 입력 신호를 두 개의 경로로 나눕니다.
각 경로는 다시 Wilkinson Power Divider에 연결되어 4개의 출력으로 나뉩니다.
이 과정은 8x8 배열을 위해 총 6단계 반복됩니다 (64 = 2^6).
2단계: 안테나 배열 연결
마지막 단계의 각 출력은 개별 안테나 요소에 연결됩니다.
각 안테나 요소는 동일한 전력을 받고, 고립을 보장하여 신호 간섭을 방지합니다.
3단계: 신호 일치 및 제어
모든 안테나 요소에 동일한 위상의 신호가 도달하도록 조절됩니다.
이를 통해 특정 방향으로 신호가 집속되며, 빔의 방향을 제어할 수 있습니다.
직렬 급전 회로망 설계
직렬 급전 회로망은 신호를 순차적으로 각 안테나 요소에 전달하여 점진적으로 전력을 감소시키는 방식입니다. 다음은 직렬 급전 회로망의 설계와 구현 단계입니다:
1단계: Wilkinson Power Divider 사용
첫 번째 Wilkinson Power Divider는 신호를 두 개의 경로로 나눕니다.
각 경로는 순차적으로 각 안테나 요소에 연결됩니다.
각 요소에서 사용된 신호는 다음 요소로 전달되며, 점진적으로 전력이 감소합니다.
2단계: 위상 조정
각 요소 사이에 위상 이동기를 삽입하여 신호의 위상을 조정합니다.
이를 통해 특정 방향으로 신호가 집속되도록 제어합니다.
3단계: 신호 일치 및 제어
첫 번째 요소는 최대 전력을 받고, 각 요소를 지나면서 전력이 감소하도록 설계됩니다.
위상 이동을 통해 빔의 방향을 조절할 수 있습니다.
구현 세부사항
안테나 요소 배치
8x8 배열의 각 안테나 요소는 동일한 간격으로 배치됩니다.
요소 간의 간격은 일반적으로 λ/2 (파장의 절반)로 설정됩니다.
전력 분배 네트워크
Wilkinson Power Divider는 마이크로스트립 라인으로 구현됩니다.
각 분배기는 3 dB의 삽입 손실과 높은 고립을 가집니다.
위상 이동기
위상 이동기는 전자식 또는 기계식으로 구현될 수 있습니다.
전자식 위상 이동기는 빠른 속도와 정밀한 제어가 가능합니다.
딥네트워크와 위의 기술관련해서 저와 관련 방산 대기업 관계자분의 공동연구(기술협력)이 가능하시면 연락 부탁드립니다 ...
- 위상배열안테나 어레이 와 Phase Shifter 를 적용해 위상배열안테나로 송출시 각각의 Phase Shifter 의 위상을 제어해서 위상배열안테나 어레이 전체의 조향각 제어 알고리즘 수식 확보 성공 ...
- 위상배열안테나 어레이 와 Phase Shifter 를 적용해 위상배열안테나로 송출시 위상배열안테나 어레이 각각의 제어이득 조절을 돌프 체비세프 위도우를 적용해 Main Lobe 와 Side Lobe 의 감쇄 이득 조절을 위한 제어 알고리즘 수식 확보 성공
- 송신 측에서 8 GHz 주파수 대역을 사용하여 16QAM으로 변조한 신호는 수신 측에서 IF 주파수로 변환되더라도, 변조된 정보(데이터)는 변하지 않습니다. 변환된 IF 신호는 8 GHz에서 변조된 신호와 동일한 데이터를 포함하고 있으며, 이를 이용해 수신 측에서 변복조 과정을 수행하여 원래의 데이터를 복원하는 노하우 확보 성공.
- 위성 데이터 송수신을 위해 16QAM 변조 및 복조 알고리즘이 필요한데 이것의 동작 알고리즘 수식 확보 성공 ....
- 위성데이터 송수신시 송수신 데이터가 오류가 있을때 오류가 난 데이터를 보정해주는 FEC 에러 보정 알고리즘 수식 확보 성공
16QAM(16 Quadrature Amplitude Modulation) 변조 신호가 수신 측에서 IF(Intermediate Frequency) 주파수로 변환되더라도 변조된 정보가 왜 변하지 않는지 이해하기 위해서는 주파수 변환의 기본 원리와 16QAM 변조 방식을 자세히 살펴볼 필요가 있습니다. 또한 RF 하드웨어 설계와 펌웨어 구현 방법을 각각 5가지 핵심 사항으로 상세히 설명하겠습니다.
1. 16QAM 변조 신호의 정보 보존
주파수 변환의 원리
변조 신호:16QAM은 디지털 데이터를 16개의 서로 다른 심볼로 변조합니다. 각 심볼은 I(인페이즈)와 Q(쿼드라처) 성분의 조합으로 표현됩니다. 변조된 신호는 고주파수 대역(예: 8 GHz)에서 전송됩니다.
주파수 변환:RF 신호를 IF 주파수로 변환할 때, 주파수 변환 과정은 신호의 정보 자체를 변경하지 않습니다. 단지 신호의 주파수 대역을 이동시키는 과정입니다. RF 신호와 로컬 오실레이터(LO) 신호를 믹서에서 혼합하여 IF 신호를 생성합니다.
변조된 정보의 유지
신호의 일관성:16QAM 신호에서 정보는 I/Q 평면상의 심볼 패턴에 의해 정의됩니다. 주파수 변환은 신호의 이러한 심볼 패턴을 변형하지 않고, 단순히 신호의 주파수 대역을 이동시킵니다.
정보 전송:변환된 IF 신호는 원래의 변조 정보와 동일한 I/Q 평면상의 패턴을 유지하므로, 원래의 데이터는 IF 신호에서 변하지 않고 그대로 유지됩니다.
Wilkinson Power Divider를 이용한 8x8 위상배열안테나 어레이 설계와 구현 - 딥네트워크는 안테나 어레이 설계시 RF 전력 급전 회로망 설계 부분도 다음과 같이 검토가 됬읍니다 ...
위상 배열 안테나 시스템에서 Wilkinson Power Divider를 사용하여 병렬 및 직렬 급전 회로망을 설계하는 방법을 설명합니다.
1. Wilkinson Power Divider의 역할
Wilkinson Power Divider는 신호를 여러 경로로 균등하게 분배하고, 각 경로 간의 전기적 고립을 보장하는 데 사용됩니다. 이는 위상 배열 안테나에서 신호 분배에 필수적입니다.
2. 8x8 위상 배열 안테나 개요
8x8 위상 배열 안테나는 64개의 개별 안테나 요소로 구성되며, 각각의 요소는 특정 위상과 전력을 가지도록 조절됩니다. 이를 통해 빔의 방향과 형태를 제어할 수 있습니다.
병렬 급전 회로망 설계
병렬 급전 회로망은 모든 안테나 요소에 동일한 전력과 위상으로 신호를 분배하는 방식입니다. 다음은 병렬 급전 회로망의 설계와 구현 단계입니다:
1단계: Wilkinson Power Divider 사용
첫 번째 Wilkinson Power Divider는 입력 신호를 두 개의 경로로 나눕니다.
각 경로는 다시 Wilkinson Power Divider에 연결되어 4개의 출력으로 나뉩니다.
이 과정은 8x8 배열을 위해 총 6단계 반복됩니다 (64 = 2^6).
2단계: 안테나 배열 연결
마지막 단계의 각 출력은 개별 안테나 요소에 연결됩니다.
각 안테나 요소는 동일한 전력을 받고, 고립을 보장하여 신호 간섭을 방지합니다.
3단계: 신호 일치 및 제어
모든 안테나 요소에 동일한 위상의 신호가 도달하도록 조절됩니다.
이를 통해 특정 방향으로 신호가 집속되며, 빔의 방향을 제어할 수 있습니다.
직렬 급전 회로망 설계
직렬 급전 회로망은 신호를 순차적으로 각 안테나 요소에 전달하여 점진적으로 전력을 감소시키는 방식입니다. 다음은 직렬 급전 회로망의 설계와 구현 단계입니다:
1단계: Wilkinson Power Divider 사용
첫 번째 Wilkinson Power Divider는 신호를 두 개의 경로로 나눕니다.
각 경로는 순차적으로 각 안테나 요소에 연결됩니다.
각 요소에서 사용된 신호는 다음 요소로 전달되며, 점진적으로 전력이 감소합니다.
2단계: 위상 조정
각 요소 사이에 위상 이동기를 삽입하여 신호의 위상을 조정합니다.
이를 통해 특정 방향으로 신호가 집속되도록 제어합니다.
3단계: 신호 일치 및 제어
첫 번째 요소는 최대 전력을 받고, 각 요소를 지나면서 전력이 감소하도록 설계됩니다.
위상 이동을 통해 빔의 방향을 조절할 수 있습니다.
구현 세부사항
안테나 요소 배치
8x8 배열의 각 안테나 요소는 동일한 간격으로 배치됩니다.
요소 간의 간격은 일반적으로 λ/2 (파장의 절반)로 설정됩니다.
전력 분배 네트워크
Wilkinson Power Divider는 마이크로스트립 라인으로 구현됩니다.
각 분배기는 3 dB의 삽입 손실과 높은 고립을 가집니다.
위상 이동기
위상 이동기는 전자식 또는 기계식으로 구현될 수 있습니다.
전자식 위상 이동기는 빠른 속도와 정밀한 제어가 가능합니다.
딥네트워크와 위의 기술관련해서 저와 관련 방산 대기업 관계자분의 공동연구(기술협력)이 가능하시면 연락 부탁드립니다 ...
제가 운영하는 일인기업 딥네트워크는 AESA Radar 의 위상배열안테나 어레이를 적용해 Beamforming 기술 구현 노하우를 98 % 보유하고 있읍니다 ...
관심있는 방산 기업들의 기술협력 문의 부탁드립니다 ....
1. 위상 배열 안테나 어레이
위상 배열 안테나 어레이는 다수의 개별 안테나 요소로 구성되며, 각각의 요소가 독립적으로 제어됩니다. 이 안테나 어레이는 전파의 위상을 조절함으로써 빔의 방향을 전자적으로 제어할 수 있습니다.
2. 빔포밍 원리
빔포밍은 여러 안테나 요소에서 방사된 전파가 특정 방향으로 결합되도록 위상을 조절하는 기술입니다. 이를 통해 신호의 이득을 높이고, 특정 방향으로 전파를 집중시킬 수 있습니다.
3. 빔포밍 구현 단계
1) 신호 생성 및 위상 제어
각 안테나 요소에 공급되는 신호의 위상을 조절하기 위해 위상 변이기(Phase Shifter)를 사용합니다. 이는 전파의 합성 방향을 바꾸는 데 필수적입니다.
2) T/R 모듈
각 안테나 요소에는 송수신 모듈(T/R Module)이 포함되어 있습니다. 이 모듈은 신호의 증폭, 위상 조절, 송수신 전환 등을 수행합니다.
3) 신호 처리
디지털 신호 프로세서(DSP) 또는 FPGA를 사용하여 각 안테나 요소에서 수신된 신호를 디지털로 변환하고, 필요한 신호 처리를 수행합니다. 이를 통해 고해상도의 이미지나 데이터를 얻을 수 있습니다.
4) 전자적 빔 스캐닝
빔의 방향을 바꾸기 위해 물리적으로 안테나를 움직일 필요 없이 전자적으로 위상을 조절하여 빔을 스캔합니다. 이는 매우 빠르게 여러 방향을 탐색하고, 목표를 추적하는 데 유리합니다.
4. 이점
신속한 방향 전환: 물리적 움직임 없이 전자적으로 빔 방향을 변경할 수 있어, 매우 빠르게 여러 목표를 탐지하고 추적할 수 있습니다.
높은 해상도: 각 안테나 요소의 신호를 종합하여 고해상도의 이미지를 얻을 수 있습니다.
내구성 및 신뢰성: 기계적 부품이 적어 내구성이 높고 신뢰성이 우수합니다.
5. 응용 분야
AESA 레이더는 항공기, 군함, 지상 레이더 시스템 등 다양한 분야에 적용되며, 주로 군사 및 방위 목적으로 사용됩니다. 최근에는 민간 항공기와 기상 관측 시스템 등에서도 그 활용이 확대되고 있습니다.
이 기술은 고도의 정밀성과 빠른 반응 속도를 요구하는 현대 전자전과 방어 시스템에서 필수적인 역할을 합니다.
딥네트워크 빔포밍(Beamforming) 관련 보유기술 소개 ...
- 위상배열안테나 어레이 와 Phase Shifter 를 적용해 위상배열안테나로 송출시 각각의 Phase Shifter 의 위상을 제어해서 위상배열안테나 어레이 전체의 조향각 제어 알고리즘 수식 확보 성공 ...
- 위상배열안테나 어레이 와 Phase Shifter 를 적용해 위상배열안테나로 송출시 위상배열안테나 어레이 각각의 제어이득 조절을 돌프 체비세프 위도우를 적용해 Main Lobe 와 Side Lobe 의 감쇄 이득 조절을 위한 제어 알고리즘 수식 확보 성공
- 송신 측에서 8 GHz 주파수 대역을 사용하여 16QAM으로 변조한 신호는 수신 측에서 IF 주파수로 변환되더라도, 변조된 정보(데이터)는 변하지 않습니다. 변환된 IF 신호는 8 GHz에서 변조된 신호와 동일한 데이터를 포함하고 있으며, 이를 이용해 수신 측에서 변복조 과정을 수행하여 원래의 데이터를 복원하는 노하우 확보 성공.
- 위성 데이터 송수신을 위해 16QAM 변조 및 복조 알고리즘이 필요한데 이것의 동작 알고리즘 수식 확보 성공 ....
- 위성데이터 송수신시 송수신 데이터가 오류가 있을때 오류가 난 데이터를 보정해주는 FEC 에러 보정 알고리즘 수식 확보 성공
16QAM(16 Quadrature Amplitude Modulation) 변조 신호가 수신 측에서 IF(Intermediate Frequency) 주파수로 변환되더라도 변조된 정보가 왜 변하지 않는지 이해하기 위해서는 주파수 변환의 기본 원리와 16QAM 변조 방식을 자세히 살펴볼 필요가 있습니다. 또한 RF 하드웨어 설계와 펌웨어 구현 방법을 각각 5가지 핵심 사항으로 상세히 설명하겠습니다.
1. 16QAM 변조 신호의 정보 보존
주파수 변환의 원리
변조 신호: 16QAM은 디지털 데이터를 16개의 서로 다른 심볼로 변조합니다. 각 심볼은 I(인페이즈)와 Q(쿼드라처) 성분의 조합으로 표현됩니다. 변조된 신호는 고주파수 대역(예: 8 GHz)에서 전송됩니다.
주파수 변환: RF 신호를 IF 주파수로 변환할 때, 주파수 변환 과정은 신호의 정보 자체를 변경하지 않습니다. 단지 신호의 주파수 대역을 이동시키는 과정입니다. RF 신호와 로컬 오실레이터(LO) 신호를 믹서에서 혼합하여 IF 신호를 생성합니다.
변조된 정보의 유지
신호의 일관성: 16QAM 신호에서 정보는 I/Q 평면상의 심볼 패턴에 의해 정의됩니다. 주파수 변환은 신호의 이러한 심볼 패턴을 변형하지 않고, 단순히 신호의 주파수 대역을 이동시킵니다.
정보 전송: 변환된 IF 신호는 원래의 변조 정보와 동일한 I/Q 평면상의 패턴을 유지하므로, 원래의 데이터는 IF 신호에서 변하지 않고 그대로 유지됩니다.
Wilkinson Power Divider를 이용한 8x8 위상배열안테나 어레이 설계와 구현 - 딥네트워크는 안테나 어레이 설계시 RF 전력 급전 회로망 설계 부분도 다음과 같이 검토가 됬읍니다 ...
위상 배열 안테나 시스템에서 Wilkinson Power Divider를 사용하여 병렬 및 직렬 급전 회로망을 설계하는 방법을 설명합니다.
1. Wilkinson Power Divider의 역할
Wilkinson Power Divider는 신호를 여러 경로로 균등하게 분배하고, 각 경로 간의 전기적 고립을 보장하는 데 사용됩니다. 이는 위상 배열 안테나에서 신호 분배에 필수적입니다.
2. 8x8 위상 배열 안테나 개요
8x8 위상 배열 안테나는 64개의 개별 안테나 요소로 구성되며, 각각의 요소는 특정 위상과 전력을 가지도록 조절됩니다. 이를 통해 빔의 방향과 형태를 제어할 수 있습니다.
병렬 급전 회로망 설계
병렬 급전 회로망은 모든 안테나 요소에 동일한 전력과 위상으로 신호를 분배하는 방식입니다. 다음은 병렬 급전 회로망의 설계와 구현 단계입니다:
1단계: Wilkinson Power Divider 사용
첫 번째 Wilkinson Power Divider는 입력 신호를 두 개의 경로로 나눕니다.
각 경로는 다시 Wilkinson Power Divider에 연결되어 4개의 출력으로 나뉩니다.
이 과정은 8x8 배열을 위해 총 6단계 반복됩니다 (64 = 2^6).
2단계: 안테나 배열 연결
마지막 단계의 각 출력은 개별 안테나 요소에 연결됩니다.
각 안테나 요소는 동일한 전력을 받고, 고립을 보장하여 신호 간섭을 방지합니다.
3단계: 신호 일치 및 제어
모든 안테나 요소에 동일한 위상의 신호가 도달하도록 조절됩니다.
이를 통해 특정 방향으로 신호가 집속되며, 빔의 방향을 제어할 수 있습니다.
직렬 급전 회로망 설계
직렬 급전 회로망은 신호를 순차적으로 각 안테나 요소에 전달하여 점진적으로 전력을 감소시키는 방식입니다. 다음은 직렬 급전 회로망의 설계와 구현 단계입니다:
1단계: Wilkinson Power Divider 사용
첫 번째 Wilkinson Power Divider는 신호를 두 개의 경로로 나눕니다.
각 경로는 순차적으로 각 안테나 요소에 연결됩니다.
각 요소에서 사용된 신호는 다음 요소로 전달되며, 점진적으로 전력이 감소합니다.
2단계: 위상 조정
각 요소 사이에 위상 이동기를 삽입하여 신호의 위상을 조정합니다.
이를 통해 특정 방향으로 신호가 집속되도록 제어합니다.
3단계: 신호 일치 및 제어
첫 번째 요소는 최대 전력을 받고, 각 요소를 지나면서 전력이 감소하도록 설계됩니다.
위상 이동을 통해 빔의 방향을 조절할 수 있습니다.
구현 세부사항
안테나 요소 배치
8x8 배열의 각 안테나 요소는 동일한 간격으로 배치됩니다.
요소 간의 간격은 일반적으로 λ/2 (파장의 절반)로 설정됩니다.
전력 분배 네트워크
Wilkinson Power Divider는 마이크로스트립 라인으로 구현됩니다.
각 분배기는 3 dB의 삽입 손실과 높은 고립을 가집니다.
위상 이동기
위상 이동기는 전자식 또는 기계식으로 구현될 수 있습니다.
전자식 위상 이동기는 빠른 속도와 정밀한 제어가 가능합니다.
딥네트워크와 위의 기술관련해서 저와 관련 방산 대기업 관계자분의 공동연구(기술협력)이 가능하시면 연락 부탁드립니다 ...
LLM 도 개발하려면 물론 소스코딩도 중요한데요 ... 저는 딥러닝 소스코딩 실력은 약간 모자르는것 인정 하구요 ... 딥러닝 LLM 을 대기업에서 개발시에 물론 소스 코딩 능력도 당연 중요한데 저는 이것보다 더 중요한게 현재 ChatGPT 유사 개발 진행시 가장 큰 이슈로 제가 생각하는것은 ChatGPT 에게 질문을 했을때 도대체 어떻게 ChatGPT 의 학습 알고리즘의 동작원리를 구성(설계/구현)해야 좀 더 정확한 답변이 가능할지 이런것들이 더 중요하다고 저는 판단하거든요 ... 이렇게 원천적인 ChatGPT 의 근본적인 동작 원리의 이슈 한두가지를 대기업에 제안해서 같이 고민해 보자고 제안했더니 핵심 이슈는 자기네 내부적으로 처리한다는 답변을 받았읍니다 ... 혹시 이런 부분의 협력을 조그만 부분부터 단계적으로 저희 딥네트워크와 함께 진행하실 기업이 있으실까요 ? 있으시면 아래의 이메일 주소로 연락 부탁드립니다 ...
또 한가지 저의 고민 분야는 로봇 설계 분야 입니다 ... 저는 로봇 설계의 핵심은 대략 2 가지로 보는데 그 한가지가 정밀모터제어쪽이고 또 하나는 로봇의 정밀 자세제어 부분 이라 생각 합니다 ... 정밀모터 제어를 PMSM Motor 로 FOC 제어를 처리하는 세부 알고리즘 구현 기법을 이해하고 있고 또 로봇의 정밀 자세제어를 위해 칼만필터를 적용해 로봇의 정밀 자세제어가 가능하게 칼만필터의 세부 구현 알고리즘 또한 깊이있게 이해하고 있읍니다 ... 저는 이 두가지 이슈에 대해 전문 지식이 있다는것 입니다 ... 이것도 대기업에 제안서를 넣어 놓고 결과를 기다리면서 제가 소기업이라 대기업이 이런것을 어떻게 검토해줄지 그런게 약간 아니 많이 걱정됩니다 ... 로봇 제어도 얼마전 중견기업에도 간략히 제안했었는데 자기네 이미 상용 기술 있다고 아예 검토의견도 없더라구요 ... 로봇 설계 기술 전체 다 는 아니어도 몇가지 이슈에 대한 전문 노하우를 확보하고 있는데 상대방에게 어떤식으로 제안해야 저희 로봇 기술력을 인정 받아 단계적으로 공동 협력이 가능할지 이런거 제안서 넣을때 부터 제안을 뭘 어떻게 해야 할지 이런거 다 고민이 태산 입니다 ... 로봇도 이렇게 핵심 이슈 두가지 확실한 기술력 확보가 되도 큰기업과 협력 방안 마련이 참 쉽지 않은게 상대방도 저를 잘 모르니 제가 상대방에게 어떻게 제안 해야 할지 고민이 너무 많읍니다 ...
정밀 CAN 통신 디버깅 툴로는 Vector사의 CANoe와 PCAN Explorer가 대표적입니다. 이 외에도 CANlink와 고급 오실로스코프 같은 고가의 도구가 반드시 필요합니다
CANopen에서 NTM (Network Management)와 관련된 OD (Object Dictionary) 엔트리에 대한 접근 방식은 CAN FD 프레임을 사용하여 구현될 수 있습니다. CAN FD는 CANopen의 기본적인 CAN 프레임을 확장하여 더 큰 데이터를 빠르게 전송할 수 있는 방법입니다. CAN FD 프레임은 더 큰 데이터 트랜스포콜과 더 큰 데이터 크기를 지원하여, CANopen에서의 SDO (Service Data Object) 사용에 유용합니다.
CANopen 네트워크에서 PDO (Process Data Object)와 SDO (Service Data Object)는 데이터를 전송하는 두 가지 주요 메커니즘입니다. 각각의 프로토콜은 특정한 목적과 사용 사례에 맞게 설계되었습니다.
PDO (Process Data Object)
PDO는 실시간 데이터 전송에 최적화되어 있습니다. 이 프로토콜은 다음과 같은 특징을 가집니다:
고속 전송: PDO는 주로 실시간 제어 작업에 사용되며, 낮은 지연 시간과 빠른 데이터 전송이 필요한 경우에 적합합니다.
단일 프레임: 일반적으로 PDO는 하나의 CAN 프레임에 최대 8바이트의 데이터를 담아 전송합니다.
브로드캐스트 가능: PDO는 네트워크 상의 여러 노드에게 동시에 데이터를 전송할 수 있어, 여러 장치가 동일한 데이터를 거의 동시에 받을 수 있습니다.
사이클링 전송: PDO는 주기적으로 또는 특정 이벤트가 발생했을 때 자동으로 전송될 수 있습니다.
SDO (Service Data Object)
SDO는 더 복잡한 데이터 전송과 디바이스 구성에 사용됩니다. SDO의 특징은 다음과 같습니다
상세한 데이터 전송: SDO는 오브젝트 딕셔너리 내의 특정 항목에 대한 접근을 제공하며, 복잡한 데이터 구조나 대량의 데이터를 전송할 때 사용됩니다.
요청/응답 메커니즘: SDO 통신은 요청과 응답의 형태로 이루어집니다. 한 노드가 데이터를 요청하면, 다른 노드가 해당 데이터를 응답으로 보냅니다.
블록 전송: SDO는 블록 전송 모드를 지원하여, 한 번에 많은 양의 데이터를 전송할 수 있습니다.
비동기 통신: SDO는 주기적인 데이터 전송보다는 필요할 때마다 데이터를 전송하는 비동기 통신에 적합합니다.
예시
예를 들어, 모터 제어 시스템에서 토크 제어와 위치 제어를 위한 데이터를 전송해야 한다고 가정해 보겠습니다.
토크 제어: 실시간으로 모터의 토크를 조절해야 하므로, PDO를 사용하여 모터 드라이버에게 토크 값을 빠르게 전송할 수 있습니다.
위치 제어: 모터의 위치 설정 값이나 구성 파라미터와 같은 상세한 정보가 필요할 때는 SDO를 사용하여 필요한 데이터를 전송합니다.
이러한 방식으로, CANopen 네트워크는 다양한 제어 요구 사항과 데이터 전송 요구 사항을 효율적으로 처리할 수 있습니다.
CANopen에서의 NTM (Network Management) 동작원리와 설계 구조는 다음과 같습니다:
Transformer 모델의 디코더는 인코딩된 벡터를 사용하여 요약문을 생성하는 복잡한 과정을 거칩니다. 학습과 추론 과정에서 디코더의 동작은 다음과 같이 다릅니다:
학습 과정에서: 디코더는 인코더로부터 전달된 인코딩된 벡터와 함께, 이전에 생성된 토큰들을 입력으로 받습니다. 이러한 입력은 디코더의 각 레이어를 통과하면서, 셀프 어텐션 메커니즘을 사용하여 토큰 간의 관계를 학습합니다. 셀프 어텐션은 각 토큰이 다른 모든 토큰과 어떻게 상호작용하는지를 결정하며, 이는 문맥을 이해하는 데 중요합니다. 학습 과정에서는 교사 강요(Teacher Forcing) 방식을 사용하여, 실제 정답 토큰을 다음 입력으로 제공함으로써 모델이 올바른 출력을 생성하도록 유도합니다. 손실 함수(예: 크로스 엔트로피 손실)를 통해 예측된 출력과 실제 정답 사이의 오차를 계산하고, 이를 최소화하기 위해 모델의 가중치를 업데이트합니다.
추론 과정에서: 학습된 모델을 사용하여 새로운 데이터에 대한 요약문을 생성할 때, 디코더는 이전에 생성된 토큰들을 입력으로 받아 다음 토큰을 예측합니다. 이 과정에서는 실제 정답이 없기 때문에, 모델은 이전에 생성된 자신의 출력을 다음 입력으로 사용합니다. 이를 자기 회귀적(Autoregressive) 방식이라고 합니다. 각 단계에서 모델은 확률이 가장 높은 토큰을 선택하거나, 빔 서치(Beam Search)와 같은 전략을 사용하여 더 나은 결과를 얻을 수 있습니다.
인코더와 디코더의 각 레이어는 멀티-헤드 어텐션과 포지션-와이즈 피드포워드 네트워크를 포함합니다. 이 구성 요소들은 모델이 입력 문장의 문맥을 이해하고, 적절한 요약문을 생성하는 데 필수적입니다. 학습과 추론 과정 모두에서, 포지셔널 인코딩은 각 토큰의 순서 정보를 모델에 제공하여, 문장의 시퀀스 정보를 유지합니다.
Transformer 모델은 문서 요약, 기계 번역, 자연어 이해 등 다양한 자연어 처리 작업에 효과적으로 사용됩니다. 각 작업의 특성에 맞게 모델의 구조와 하이퍼파라미터를 조정하여 최적의 성능을 달성할 수 있습니다.
NLP 평가 분야에서 BLEU 및 ROUGE 점수는 각각 기계 생성 번역 및 요약의 품질을 평가하는 데 일반적으로 사용되는 지표입니다. BLEU 점수는 주로 기계 번역 작업에 사용되지만 ROUGE 점수는 텍스트 요약 작업에 사용됩니다. 두 지표 모두 n-gram 중첩에 의존하여 기계 생성 출력과 참조 번역 또는 요약 간의 유사성을 측정합니다. NLP 모델을 평가하는 간단하고 효과적인 방법을 제공하지만 출력의 전반적인 의미, 유창성 및 일관성을 캡처하는 데 한계가 있습니다. NLP 평가에 사용하는 동안 작업의 특정 요구 사항과 이러한 메트릭의 제한 사항을 고려하는 것이 중요합니다.
결론적으로 BLEU 및 ROUGE 점수는 각각 기계 번역 및 텍스트 요약 작업에서 NLP 모델의 성능을 평가하는 데 유용한 도구입니다. 기계에서 생성된 출력과 참조 번역 또는 요약 간의 유사성을 정량적으로 측정하여 연구자와 실무자가 모델의 품질을 객관적으로 평가할 수 있도록 합니다.
RAG 모델은 두 개의 트랜스포머 모델을 사용하여 두 단계로 작동합니다. 이 두 단계는 각각 검색 단계와 프롬프트 템플릿 생성 단계입니다. 각 단계는 서로 다른 목적을 가지고 있으며, 각각의 트랜스포머 모델은 해당 단계에서 필요한 기능을 수행하기 위해 특별히 학습됩니다.
검색 단계: 첫 번째 트랜스포머 모델은 사용자의 질문을 분석하여 핵심 요소와 의미를 파악합니다. 이 모델은 UD 데이터셋을 통해 학습된 문장 구조와 의존 관계를 활용하여, 질문에서 중요한 ‘subject’, ‘object’ 등의 레이블을 식별합니다. 그런 다음, 이 정보를 사용하여 데이터베이스에서 관련 문서를 검색합니다.
프롬프트 템플릿 생성 단계: 두 번째 트랜스포머 모델은 검색된 문서와 사용자 질문 사이의 관계를 분석합니다. 이 모델은 ‘self-attention’ 메커니즘을 사용하여 문서 내의 각 단어와 질문 내의 각 단어 사이의 관련성을 평가하고, 가장 관련성 높은 정보를 추출합니다. 이 정보는 사용자 질문과 결합되어 새로운 프롬프트 템플릿을 형성합니다.
이 두 단계는 서로 연결되어 있으며, 각각의 트랜스포머 모델은 자신의 역할에 맞게 최적화되어 학습됩니다. 검색 단계에서 얻은 문서들은 프롬프트 템플릿 생성 단계로 전달되어, 최종적인 응답을 생성하는 데 사용됩니다. 이러한 방식으로 RAG 모델은 사용자 질문에 대한 정확하고 관련성 높은 응답을 생성할 수 있습니다.
LLM 분석 및 개발 자문관련 여러기업의 개발 및 자문 문의 아래의 이메일 주소로 많은 문의 부탁드립니다 ...
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang