그동안 2 년 가까이 BLDC/PMSM 모터제어로 전류를 정밀하게 제어하는 방법을 찾으려고 관련 논문을 수백편 뒤져서 최근에 모터의 정밀 전류제어 구현 기법을 99 % 터득에 성공했다 ... 저는 그동안 모터제어만 판것은 아니고 카메라 이미지센서의 화질 보정 알고리즘을 터득하려고 논문과 특허를 수도 없이 뒤져서 결국 터득에 성공했다 ... 밥벌이를 하려고 이것만 한것은 아니다 ... 딥러닝 NeRF 논문과 StyleGAN 논문의 핵심 딥러닝 모델 설계 구조를 파악하느라 고생 좀 했다 ... 또한 구글 Transformer Model 기반으로 음성인식 구현을 위한 딥러닝 모델 세부 설계구조 분석도 결코 쉽지 않았다 ... 이것으로 밥벌이를 하려 99% 준비해 놨는데 경기가 죽어서 일꺼리 얻기가 하늘에 별따기라 너무 힘들다 ... 이렇게 힘들어도 나는 자신있다 왜냐하면 위에서 언급한 99 점 짜리 기술이 몇가지가 있으니 언젠가 반드시 기회가 오리라 나는 확신하기 때문이다 ...
임베디드 리눅스 드라이버 와 어플 설계도 카메라 분야와 네트웍 통신 분야 귀사 요구에 대응이 가능햔 노하우가 있구요 STM32 CPU 로 카메라 분야 네트웍 통신분야 귀사 요구에 대응 가능한 노하우가 있읍니다 제가 운영하는 딥네트워크는 이런 건들의 개발 밎 자문 처리가 가능합니다 저는 직원으로 일하든 제가 개발용역을 진행하던 둘 다 가능하다는 말씀 올립니다
또한 BLDC / PMSM / 스테핑 모터 전류제어 속도제어 등등의 정밀제어로 결과내는것 자신 있읍니다
STM32 CPU 카메라 펌웨어 개발 - CubeMX 개발 툴로 DCMI 제어 개발 가능 합니다 ...
프로토타입 개발 예상 소요기간 : 2 개월 (이미지센서의 눈 틔우는 정도 선능의 성능의 개발이 가능 합니다)
STM32 CPU TFT-LCD GUI 개발 - CubeMX 개발 툴로 TouchGFX 개발환경을 적용해서 개발 가능 합니다 ...
프로토타입 개발 예상 소요기간 : 2 개월 ( 유럽 스위스 STMicro 사의 TouchGFX 개발환경을 적용해서 개발이 가능 합니다 ) - TFT-LCD GUI 동작 시나리오를 준비해 주셔야 합니다 ...
프로토타입 개발후 기본 동작이 가능하면 안정화(양산 대응) 개발기간이 추가로 필요합니다 ...
LCD Display System based on MIPI DSI 혹은 TFT LCD LTDC 로 LCD Display System 개발 가능 합니다 ... ( MIPI DSI LCD 판넬 제조사에서 기술정보를 받으려면 MIPI DSI LCD 판넬의 MOQ 구매가 필요할수 있음 )
프로토타입개발 예상 소요기간 : 2 개월 ( MIPI DSI LCD 판넬 기술정보를 글로벌업체에서 받으려면 시간이 필요합니다 )
STM32 CPU 의 TouchScreen 드라이버 단 어플 단 펌웨어 개발 가능 합니다 (TouchScreen 제조사에서 기술정보를 받으려면 TouchScreen 의 MOQ 구매가 필요할수 있음 )
프로토타입개발 예상 소요기간 : 2 개월 ( TouchScreen 판넬 기술정보를 글로벌업체에서 받으려면 시간이 필요합니다)
STM32 CPU CubeMX 개발 툴로 USB Device 단 USB CDC 통신 펌웨어 개발 가능 합니다 ...
프로토타입개발 예상 소요기간 : 1 개월
STM32 MCU 로 개발보드 커스토마이징시 SDRAM / Quad-SPI Flash / NOR Flash 등 Memory 장치의 Configuration 개발기간이 필요합니다 ... ---- STM32 CPU 개발시 공통으로 적용되는 사항 입니다 ...
프로토타입 개발 예상 소요기간 : 1 개월 ( 메모리 칩셋 기술정보를 글로벌업체에서 받으려면 시간이 필요합니다 )
개발기간은 위의 세부 개발 아이템들의 개발을 여러개 조합할 경우 고객사의 전체 아이템의 개발기간을 어느정도 네고가 가능 합니다 ... 위의 개발을 진행하려면 각종 디바이스 칩셋을 MOQ 구매가 필요할수 있읍니다 ...
위의 각각의 개발 아이템별로 안정화(양산 대응) 개발 기간이 추가로 필요할수 있읍니다
각각 HW 개발 비용은 제가 별도로 외주 개발업체와 협의해서 외주 개발업체에 의뢰 예정 입니다 ...
HW 개발 비용은 외주업체와 협의되는것으로 확정 합니다.
반도체 공급망 위기로 인해 STM32 CPU 등등 부품 납기가 최소 6 개월에서 1 년까지가 기본인 점 양해 부탁드립니다 ... ( 저는 해당 칩셋 재고를 가지고 있지 않읍니다 )
====================================================================== 노르딕 BLE 칩셋 SDK 커스토마이징 및 퀄컴 ADK 커스토마이징 프로토타입 개발관련 ...
- 노르딕사 칩셋 nRF51 / nRF52 SDK 를 사용해서 Central / Peripheral 데이터 송수신 개발 노하우 확보. nRF5 SDK 를 사용해서 1 : N 통신 세부 구현 노하우 확보 nRF5 IOT SDK 를 사용해서 소켓 통신 세부 구현 노하우 확보
HOST CPU 와 HOST BLE Chipsets Controller 가 어떻게 동작하는지 세부 구조를 파악했고, HOST BLE Chipsets Controller 의 Link Layer 에서 블루투스 패킷( PDU 패킷 )이 어떠한 동작 구조로 동작하는지도 파악이 되었읍니다. HOST CPU 와 HOST BLE Chipsets Controller 가 명령 패킷 / 데이터 패킷 / 이벤트 패킷 으로 HCI 가 동작하는 기본 동작 구조이다.
nRF52840 모듈의 블루투스 송수신 동작 참조소스도 분석됬고, nRF52840 Dongle 모듈의 MULTILINK + BLE UART CENTRAL + USBD CDC ACM 을 적용한 멀티링크 다중 통신의 개발 실적이 최근에 있읍니다.
nRF52840 동글 모듈 송수신과 nRF52840 DK 모듈의 블루투스 송수신을 1 : N 다중접속시 송수신 처리 세부 구현 방법을 nRF52 SDK 소스에서 어떤 구조로 설계되 있는지 개발을 그동안 진행했는데 세부 구현 노하우 확보에 성공했다 ... - 퀄컴(CSR) 사 CSR8645/CSR8670/CSR8675 블루투스 오디오 세부 구현 기술력 보유
========================================================================= 원격검침 시스템에 적용되는 LoRa 통신 구현관련 ...
SX1276 LoRa Chipset 을 적용해서 ST CPU 를 사용해 LoRa 센서단의 클래스 A 통신 구현 기술력을 가지고 있읍니다 ... LoRa Gateway Uplink: radio packets 는 gateway 에 의해 수신된다 , 그리고 Gateway 에 의해 메터데이터가 더해지고 여기에 Gateway Status 정보가 더해져서 Network Server 로forward 처리된다. LoRa GatewayDownlink: Network Server 에 의해 패킷이 생성되고 , 부가적인 메터데이터를 포함될수 있고, 또한 Gateway 의 Configuration Data 도 포함되서 Gateway 의 Radio Channel 로 Transmit 된다
SemTech 사가 공개하는 디바이스단의 펌웨어 소스는 ClassA/B/C end-device 구현시 Periodically uplinks a frame 은 the Cayenne LPP protocol 을 사용한다.Cayenne Low Power Payload (LPP) 은 편리하고 쉬운 방안을 제공해서LoRaWAN 같은 LPWAN networks 로 데이터를 Send 를 구현한다 ... Cayenne LPP 는 payload size restriction 이 있다 11 bytes 보다 적은 수 만 한번에 센서 데이터들을 LoRa 디바이스가 Send 하는것을 허용한다.
로라통신의 보안 메커니즘에서, MAC( Message Authentication Code )은 메시지의 위변조를 확인하기 위해 쓰이는 보안 기술 입니다. CMAC은 알고리즘과 모드 에 따라 AES CBC-MAC 메커니즘이 있구요 ... CMAC 도 마찬가지로 주된 기능은 사용자 인증(authentication)과 데이터 무결성(data integerity) 처리를 위한것 입니다 ... MAC 은 MAC 을 만들때 Block 함수를 사용하면 CMAC( Cipher-based Message Authentication Code )가 됩니다 ...
========================================================================== 스마트워치 / 스마트밴드 개발 기술력 소개 ... Invensense ICM20948 칩셋으로 칼만필터를 적용해서 보정 설계하는것 세부 노하우 분석 성공 ... Invensense ICM20948 칩셋으로 DMP 기술을 적용해서 보정 설계하는것 프로토타입 개발기간은 보통 2 달반 정도 소요됨 ...
IMU 9 축 센서 Invensense ICM20948 데이터 읽기 기술력 확보 .... - STM32F4 CPU 에서 MPU9250 센서값 읽기 기술력 확보 ... IMU 9 축 센서 Invensense ICM20948 을 DMP 기술을 적용해서 보정된 9 축센서 데이터 개발기술 노하우 확보
- AHRS 라는 모듈이 IMU + CPU 모듈이라는데 ... 이 센서데이터값 각각을 정밀 보정하는 세부 알고리즘까지 모두 구현되 있어서 UART 등 인터페이스로 그 보정 데이터를 제공한다고 한다.
모션 디텍트 개발의 경우 한가지 제스쳐 동작 검출하는것 프로토타입 개발에 약 3 달반 소요 (보통 정확도는 70 프로 정도) Invensense ICM20948 칩셋으로 상보필터와 칼만필터를 적용해서 보정 설계하는것 펌웨어 설계를 초당 200 - 300 번 센서데이터 획득시 상보필터나 칼만필터로 보정작업을 처리함 ... =========================================================================
리눅스커널 드라이버 및 Station Mode 제어용 WPA Supplicant SW 수정개발
리눅스 커널의 WIFI Network Stack 구현중 어플단에서 libnl 라이브러리를 적용해서 Netlink socket 구성으로 WIFI Station 모드 제어를 위해 wpa_cli 부를 리눅스커널단의 nl80211 부와 연동해서 제어하는 부분 세부 구현 경험 있음
또한 AP Mode 제어를 위해 hostapd_cli 부를 어플단에서 libnl 라이브러리를 적용해서 Netlink socket 구성으로 리눅스커널단의 nl80211 부와 연동해서 제어하는 부분 세부 구현 경험 있음
Ø Linux Kernel Camera Sensor Device Driver 수정개발 및 화질 튜닝 관련
리눅스커널의 카메라 프레임워크 구현 소스가 어떤 방식으로 동작하는지
세부 노하우 확보.
Exynos8895 CPU - S5K4E6_C2 / S5K4EC / SR352 / SR030
기존DNN-HMM 기반음향모델에서는phone 단위의 alignment 된 정답 label 이 요구되었음
•CTC 는 발성 script 를 정답 label 로 사용함 으로써, 정답 label 이 없는 학습자료를 실시간으로 사용하여 학습가능
기존 DNN-HMM 기반 음향모델에서는 HMM 의 각 state 에 대한 observation probability 를 얻기위해, GMM-HMM 모델에 대한 학습을 먼저 진행했음
•CTC 는 HMM 의 각 state 에 대한 observation probability 를 사용하지 않기 때문에, GMM-HMM 모델에 대한 학습을 진행하지 않아 DNN-HMM 모델과 비교하여 학습을 위한 과정이 단축됨
STM32 CPU 카메라 펌웨어 개발 - CubeMX 개발 툴로 DCMI 제어 개발 가능 합니다 ...
프로토타입 개발 예상 소요기간 : 3 개월 (이미지센서의 눈 틔우는 정도 선능의 성능의 개발이 가능 합니다)
LCD Display System based on MIPI DSI 혹은 TFT LCD LTDC 로 LCD Display System 개발 가능 합니다 ... (MIPI DSI LCD 판넬 제조사에서 기술정보를 받으려면 MIPI DSI LCD 판넬의 MOQ 구매가 필요할수 있음 )
프로토타입개발 예상 소요기간 : 3 개월 (MIPI DSI LCD 판넬 기술정보를 글로벌업체에서 받으려면 시간이 필요합니다)
STM32 CPU 의 TouchScreen 드라이버 단 어플 단 펌웨어 개발 가능 합니다 (TouchScreen 제조사에서 기술정보를 받으려면TouchScreen의 MOQ 구매가 필요할수 있음 )
프로토타입개발 예상 소요기간 : 3 개월 (TouchScreen 판넬 기술정보를 글로벌업체에서 받으려면 시간이 필요합니다)
STM32 CPU CubeMX 개발 툴로 USB Device 단 USB CDC 통신 펌웨어 개발 가능 합니다 ...
프로토타입개발 예상 소요기간 : 2 개월
STM32 MCU 로 개발보드 커스토마이징시 SDRAM / Quad-SPI Flash / NOR Flash 등 Memory 장치의 Configuration 개발기간이 필요합니다 ... ---- STM32 CPU 개발시 공통으로 적용되는 사항 입니다 ...
프로토타입 개발 예상 소요기간 : 1 개월 ( 메모리 칩셋 기술정보를 글로벌업체에서 받으려면 시간이 필요합니다 )
개발기간은 위의 세부 개발 아이템들의 개발을 여러개 조합할 경우 고객사의 전체 아이템의 개발기간을 어느정도 네고가 가능 합니다 ... 위의 개발을 진행하려면 각종 디바이스 칩셋을 MOQ 구매가 필요할수 있읍니다 ...
위의 각각의 개발 아이템별로 안정화(양산 대응) 개발 기간이 추가로 필요할수 있읍니다
각각 HW 개발 비용은 제가 별도로 외주 개발업체와 협의해서 외주 개발업체에 의뢰 예정 입니다 ...
HW 개발 비용은 외주업체와 협의되는것으로 확정 합니다.
반도체 공급망 위기로 인해 STM32 CPU 등등 부품 납기가 최소 6 개월에서 1 년까지가 기본인 점 양해 부탁드립니다 ... ( 저는 해당 칩셋 재고를 가지고 있지 않읍니다 )
Galaxy-S2 Smartphone 의 H.264 HW Codec 으로 스마트폰의 영상을 압축해서 스트리밍 전송하는 부분을 구현.
PC 의 화면을 오픈소스 코덱 소스인 X264 를 사용해서 원격지의 PC 로 화면을 스트리밍 전송하는 부분을 구현.
㈜브라이센코리아 2020.8 – 2021.1 4 차 혁명시대 사업화 안 등을 제안. (기술고문으로 근무했음)
스마트 팩토리 사업화 안 중 BLDC Motor 전류제어 PI 제어기 구현 안 제안
대용량 모터 제어의 경우위에서 말씀드린 MATLAB 으로 특정 리졸버 등 특정 센싱장치들을 적용해서 제어되는 모터제어 펌웨어를 자동생성해서 기본 동작을 구현하고 ...대용량 모터 파라미터의 모델링한 부분과 모터의 전류제어 루프 및 속도제어 루프를 제어하는 PI 제어 부분 설계관련 제가 파악한 세부노하우를 점수를 매기면 그 점수가 대략 80 점은 되는것 같읍니다 ...제가 나이가 59 세라도 대용량 모터제어 알고리즘 이해 점수가 80 점은 되구요 ...대용량 모터제어 개발이 저도 100 % 완벽하지는 못 합니다 ... PI 변수값도 각각의 상황(입력에대한 모터응답률등)에 맟추어 튜닝 작업을 처리합니다.튜닝시 PI 값은 실험에 따른 전류맵에얼마나 빠르게 응답할지를 대전력 모터 테스트 시설을 갖춘 시설에서 시행착오를 거쳐서 안정적인모터응답률이 나오도록테스트를 진행하구요 .... PI 튜닝은 변동량만 계산해서 적정량에 맞는 값을 찾도록 도와주는 역할을 하는 것입니다MATLAB으로모터제어시전류제어PI전달함수부분과모터모델링전달함수를MATLAB에서펌웨어를다생성해주므로전기차모터제어시토크응답특성최적화구현도사실큰문제는없다고봅니다커스토마이징은필요하지만기본설계가다제공되니큰문제가없다고제안했습니다 …
WebRTC 기술을 적용한 오픈소스 미디어 서버 Janus 서버로 대용량 화상회의 구현 안 제안
RabbitMQ 클라우드 서비스를 적용한 수만명 정도의 대상으로 실시간으로 대규모 미디어 데이터 송수신 기술개발 및 기술자문 가능 합니다 ...RabbitMQ 클라우드 서비스의 API 함수를 적용해서 어떻게 1 : N (수만명)의 송수신이 실시간에 가깝게 가능하게 구현 설계가 가능한지 파악에 성공했읍니다 ...이것을 분석하는것을 일년반전에 시작한 동기가 이탈리아 개발 회사 Meetecho 가 설계한 오픈소스인 Janus Gateway 오픈소스를 거의 일년 이상 소스를 세부적으로 검토분석하다가Janus Gateway 오픈소스가 RabbitMQ 서비스로 미디어데이터를 송수신하는 기능을 이 오픈소스에 포함된것을 파악하면서 본격적으로1 : N (수만명)의 미디어 데이터의 네트웍 통신 송수신이 실시간에 가깝게 가능하게 구현 설계를 한 일년 빡시게 분석해서 파악 성공했읍니다 ...이를 적용해서 상용화를 위해서는 저 또한 추가의 검토분석은 필요합니다 ...저의 경우 1 : N (수만명)의 미디어 데이터의 네트웍 통신 송수신의 프로토타입 구현 설계가 가능한 기술력을 현재 보유하고 있어서 이렇게 글을 올리게 됬읍니다 ...
㈜대한 인스트루먼트 2021.2 – 2021. 10 LoRa 통신 디바이스단 및 게이트웨이단 기술 컨설팅. (기술고문으로 근무했음)
LoRa Gateway Uplink: radio packets 는 gateway 에 의해 수신된다 , 그리고 Gateway 에 의해 메터데이터가 더해지고 여기에 Gateway Status 정보가 더해져서 Network Server 로 forward 처리된다. LoRa Gateway Downlink: Network Server 에 의해 패킷이 생성되고 , 부가적인 메터데이터를 포함될수 있고, 또한 Gateway 의 Configuration Data 도 포함되서 Gateway 의 Radio Channel 로 Transmit 된다
SemTech 사가 공개하는 디바이스단의 펌웨어 소스는 ClassA/B/C end-device 구현시 Periodically uplinks a frame 은 the Cayenne LPP protocol 을 사용한다. Cayenne Low Power Payload (LPP) 은 편리하고 쉬운 방안을 제공해서 LoRaWAN 같은 LPWAN networks 로 데이터를 Send 를 구현한다 ... Cayenne LPP 는 payload size restriction 이 있다 11 bytes 보다 적은 수 만 한번에 센서 데이터들을 LoRa 디바이스가 Send 하는것을 허용한다.
자 기 소 개 서
DMBTEC 을 13 년간 운영하다 페업하고 다시 창업한 일인기업 딥 네트워크를 운영하는 59 세 장석원 입니다 ...
그동안 2 년 가까이 BLDC/PMSM 모터제어로 전류를 정밀하게 제어하는 방법을 찾으려고 관련 논문을 수백편 뒤져서 최근에 모터의 정밀 전류제어 구현 기법을 99 % 터득에 성공했다 ... 저는 그동안 모터제어만 판것은 아니고 카메라 이미지센서의 화질 보정 알고리즘을 터득하려고 논문과 특허를 수도 없이 뒤져서 결국 터득에 성공했다 ... 밥벌이를 하려고 이것만 한것은 아니다 ... 딥러닝 NeRF 논문과 StyleGAN 논문의 핵심 딥러닝 모델 설계 구조를 파악하느라 고생 좀 했다 ... 또한 구글 Transformer Model 기반으로 음성인식 구현을 위한 딥러닝 모델 세부 설계구조 분석도 결코 쉽지 않았다 ... 이것으로 밥벌이를 하려 99% 준비해 놨는데 경기가 죽어서 일꺼리 얻기가 하늘에 별따기라 너무 힘들다 ... 이렇게 힘들어도 나는 자신있다 왜냐하면 위에서 언급한 99 점 짜리 기술이 몇가지가 있으니 언젠가 반드시 기회가 오리라 나는 확신하기 때문이다 ...
임베디드 리눅스 드라이버 와 어플 설계도 카메라 분야와 네트웍 통신 분야 귀사 요구에 대응이 가능햔 노하우가 있구요 STM32 CPU 로 카메라 분야 네트웍 통신분야 귀사 요구에 대응 가능한 노하우가 있읍니다 제가 운영하는 딥네트워크는 이런 건들의 개발 밎 자문 처리가 가능합니다 저는 직원으로 일하든 제가 개발용역을 진행하던 둘 다 가능하다는 말씀 올립니다
또한 BLDC / PMSM / 스테핑 모터 전류제어 속도제어 등등의 정밀제어로 결과내는것 자신 있읍니다
저는 임베디드리눅스 커널의 카메라(이미지센서와 Camera ISP) 디바이스 드라이버와 어플 설계 경험이 있구요 … 임베디드리눅스 커널의 네트웍 드라이버와 프로토콜 스택이 리눅스커널내에 소스가 설계되 있고요 네트워크 스위치 (Switch)나 라우터 (Router)에서 제어평면 (Control Plane)과 전송평면 (Data Plane)을 분리하는 SW 설계 부분의 세부 구현 소스를 분석한 경험이 있습니다 … 네트워크 스위치 (Switch)나 라우터 (Router)에서 제어평면 (Control Plane)과 전송평면 (Data Plane)을 분리하는 SW 설계가 리눅스커널내에 네트워크 프로토콜 스택 구현부에 소스를 브로드컴이 칩을 출시할 때 커스토마이징해서 소스를 제공하는데 보통 브로드컴이 칩을 처음 출시하면 2 – 3 년이 지나야 네트워크 스위치 (Switch)나 라우터 (Router)에서 제어평면 (Control Plane)과 전송평면 (Data Plane)을 분리하는 SW 커스토마이징 구현이 안정적으로 구현 가능하게 브로드컴에서 유료로 기술지원을 해줍니다
네트워크 장비인 L3 스위치 장비의 설계 원리를 현재 정확히 이해하고 있다 ... 이 정도 파악하는 수준이면 네트워크 SW 설계도 거의 전문가급이라고 나는 판단한다 ... 네트워크 장비인 L3 스위치 장비 개발을 직접 경험해 보지 않았어도 L3 스위치 장비의 구현 원리를 파악할수 있었다 ... 나는 네트워크 장비인 L3 스위치 장비의 네트웍 프로토콜 스택 설계 전문가가 아니라 L3 스위치 장비를 응용해서 네트웍 SW 를 설계하는 전문가라함이 정확할것 같다 ...
방탄소년단 공연 실황을 해외에 방송 서비스로 중계방송을 한다고 하면 네트워크 장비인 L3 스위치 장비의 세부 설계 구조를 이해하지 못하면 대규모 방송 서비스를 설계하는것이 사실상 어렵기 때문 입니다 ...
제가 운영하는 딥 네트워크는 다음과 같은 프로토타입 구현 기술들을 보유하고 있습니다. RabbitMQ Service는 AMQP 프로토콜을 구현한 메시지 브로커 시스템입니다. RabbitMQ Service의 Exchange는 메시지를 받아서 Binding 규칙에 따라 연결된 Queue로 전달하는 역할을 합니다. RabbitMQ Service 의 Exchange는 다음과 같은 메시지 전달 방식을 가질 수 있습니다. Direct Exchange: 메시지에 포함된 routing key를 기반으로 Queue에 메시지를 전달합니다. routing key가 일치하는 Queue로만 전달됩니다. Fanout Exchange: routing key 관계없이 연결된 모든 Queue에 동일한 메시지를 전달합니다. publish/subscribe 패턴에 적합합니다. Topic Exchange: routing key 전체가 일치 하거나 일부 패턴과 일치하는 모든 Queue로 메시지가 전달됩니다. 와일드 카드(*)와 해시(#)를 이용해 routing key를 표현할 수 있습니다. Headers Exchange: 메시지 헤더를 통해 binding key만을 사용하는 것보다 더 다양한 속성을 사용할 수 있습니다. Header exchange를 사용하면 binding key는 무시되고, 헤더 값이 바인딩 시 지정된 값과 같은 경우에만 일치하는 것으로 간주합니다. RabbitMQ Service 의 Exchange와 Queue를 바인딩하는 설계 방법은 다음과 같습니다. Exchange와 Queue를 생성합니다. Queue는 반드시 미리 정의해야 사용할 수 있습니다. Binding을 추가합니다. Binding은 Exchange와 Queue를 Link하는 것입니다. Binding 시에 목적지 Queue 이름만으로도 추가할 수 있고, 일부 Exchange type에 따라 routing key를 지정해서 메시지를 필터링 한 후 지정한 Queue로 보내도록 정의할 수 있습니다. Producer가 메시지를 특정 Exchange & Queue에 전달하면, RabbitMQ는 해당 메시지를 적절한 Consumer가 소비(Consume)할 수 있도록 해당 메시지를 전달하는 역할을 수행합니다. RabbitMQ Service 의 Queue에서 메시지를 받는 방법은 다음과 같습니다. Consumer 어플리케이션은 Queue를 통해 메시지를 가져갑니다. Consumer 어플리케이션에서 Broker로 많은 연결을 맺는 것은 바람직하지 않으므로, 하나의 연결을 공유하는 Channels을 사용합니다. Consumer 어플리케이션은 Channel을 통해 Queue에 접근하고, subscribe 또는 pull 방식으로 메시지를 받아갑니다. subscribe 방식은 Queue에서 새로운 메시지가 도착하면 자동으로 Consumer에게 알려주는 방식이고, pull 방식은 Consumer가 직접 Queue에서 메시지를 가져오는 방식입니다. Consumer 어플리케이션은 받은 메시지를 처리하고, Broker에게 수신 확인(acknowledgement)을 보냅니다. 이때 Broker는 Queue에서 해당 메시지를 삭제합니다. 수신 확인 모델은 명시적으로 Broker에게 통지하는 방식과 Broker가 메시지를 전달하면 자동으로 삭제하는 방식이 있습니다.
클라우드 서비스 RabbitMQ를 사용한 메시지 큐 통신 방식으로 Publish/Subscribe 구현 기술 : 이 기술은 클라우드 서비스인 RabbitMQ를 이용하여 메시지를 발행하고 구독하는 방식으로 통신하는 기술입니다. 이를 통해 다수의 클라이언트와 서버 간에 실시간으로 데이터를 교환할 수 있습니다. 이 기술의 장점은 메시지의 안정성과 확장성을 보장하고, 네트워크 부하를 분산시킬 수 있다는 것입니다. 이 기술은 대규모 방송 서비스에서 다양한 콘텐츠를 전달하고 수신하는 데 적합합니다. 네트웍 장비 L3 / L4 장비의 네트웍 라우팅 정보 제어 기술 : 이 기술은 네트워크 장비인 L3 스위치와 L4 로드밸런서의 라우팅 정보를 제어하는 기술입니다. 이를 통해 네트워크 트래픽을 효율적으로 분배하고, 장애 복구와 보안을 강화할 수 있습니다. 이 기술의 장점은 네트워크 성능과 안정성을 향상시키고, 다양한 프로토콜과 애플리케이션을 지원한다는 것입니다. 이 기술은 대규모 방송 서비스에서 고속의 데이터 전송과 접속자 관리에 필요합니다. 대규모 방송 서비스 구현을 위한 프로토타입 설계 기술 : 이 기술은 위에서 언급한 두 가지 기술을 결합하여 대규모 방송 서비스를 구현하기 위한 프로토타입을 설계하는 기술입니다. 이를 통해 실제 서비스 환경에서의 성능과 안정성을 검증하고, 개선점을 도출할 수 있습니다. 이 기술의 장점은 실제 서비스에 적용하기 전에 문제점을 발견하고 해결할 수 있고, 최적의 서비스 구조와 아키텍처를 설계할 수 있다는 것입니다. 이 기술은 대규모 방송 서비스의 개발과 운영에 필수적입니다.
저는 이러한 기술들을 바탕으로 대규모 방송 서비스의 프로토타입을 구현하고, 사업화 개발 및 자문을 진행하고 있습니다. 저의 사이트에서 저의 포트폴리오와 경력을 확인하실 수 있습니다. 저와 함께라면 더욱 효율적이고 창의적인 대규모 방송 서비스를 만들 수 있습니다.
NeRF 논문은 Neural Radiance Fields라는 새로운 방식으로 3D 장면을 표현하고, 다양한 시점에서의 합성 이미지를 생성하는 방법을 제안했습니다. NeRF는 다음과 같은 알고리즘으로 구현됩니다.
NeRF 논문은 Neural Radiance Fields라는 새로운 방식으로 3D 장면을 표현하고, 다양한 시점에서의 합성 이미지를 생성하는 방법을 제안했습니다. NeRF는 다음과 같은 알고리즘으로 구현됩니다.
Positional Encoding : 3차원 좌표 x와 View Direction d를 고차원 벡터로 변환하는 과정입니다. 이때, 고주파 성분을 보존하기 위해 삼각함수를 이용한 인코딩 방식을 사용합니다. 즉, x와 d에 각각 다른 주파수와 위상을 가진 사인과 코사인 함수를 적용하여 특징 벡터를 생성합니다. 이렇게 하면 x와 d의 작은 변화에도 민감하게 반응할 수 있습니다. Multi-Layer Perceptron (MLP) : Positional Encoding된 특징 벡터를 입력으로 받아 해당 위치에서 바라 본 Color와 Density를 출력하는 네트워크입니다. MLP는 여러 개의 Fully Connected Layer로 구성되며, 각 레이어에서는 ReLU 활성화 함수와 Skip Connection을 사용합니다. MLP의 마지막 레이어에서는 Color는 RGB 값으로, Density는 스칼라 값으로 출력됩니다. Classical Volume Rendering : MLP에서 출력된 Color와 Density를 이용하여 합성 이미지를 생성하는 과정입니다. 이때, 카메라에서부터 장면까지의 광선을 따라서 여러 개의 샘플 포인트를 추출하고, 각 포인트에서의 Color와 Density를 MLP에 입력하여 계산합니다. 그리고, 샘플 포인트들의 Color와 Density를 가중 평균하여 최종적인 픽셀 값을 결정합니다. 이때, 가중치는 광선의 방향과 거리에 따라 달라지며, Density가 높을수록 더 많은 빛을 흡수하고 반사한다고 가정합니다.
NeRF 논문은 NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis라는 제목으로 2020년 ECCV에 발표된 논문입니다. 이 논문은 몇 개의 2D 이미지만으로도 이미지 내 물체를 3D로 렌더링하는 새로운 방법을 제안하였습니다.
NeRF 논문의 주요 설계 구조는 다음과 같습니다:
Positional Encoding: NeRF는 3D 공간의 좌표와 방향을 입력으로 받아서, 각 위치에서의 색상과 밀도를 출력하는 신경망입니다. 하지만 신경망은 고차원의 주기적인 함수를 잘 근사하지 못하기 때문에, 입력을 그대로 사용하면 고해상도의 장면을 표현하기 어렵습니다. 따라서 NeRF는 입력을 Positional Encoding이라는 방법으로 변환하여 사용합니다. Positional Encoding은 각 차원의 값을 사인과 코사인 함수에 넣어서 여러 개의 주파수를 가진 값들로 확장하는 과정입니다. 이렇게 하면 신경망이 공간적인 변화에 더 잘 반응할 수 있습니다.
Multi-Layer Perceptron (MLP): NeRF는 Positional Encoding된 좌표와 방향을 입력으로 받아서, Multi-Layer Perceptron (MLP)라고 부르는 완전 연결 신경망에 통과시킵니다. MLP는 여러 개의 은닉층과 활성화 함수로 구성되어 있으며, 각 층에서는 선형 변환과 비선형 변환을 수행합니다. MLP의 마지막 층에서는 각 위치에서의 색상과 밀도를 출력합니다. 색상은 RGB 값으로 표현되며, 밀도는 투명도와 반대되는 개념으로 표현됩니다.
Volume Rendering: NeRF는 MLP를 통해 얻은 색상과 밀도를 이용하여, 장면을 합성하는 과정을 Volume Rendering이라고 부릅니다. Volume Rendering은 카메라와 장면 사이에 가상의 광선을 생성하고, 광선 위의 여러 점들에서 MLP를 평가하여 색상과 밀도를 얻습니다. 그리고 이들을 합성하여 광선이 카메라에 도달할 때의 최종 색상을 계산합니다. Volume Rendering은 광선 위의 점들이 서로 영향을 주고 받는 것을 모델링할 수 있기 때문에, 복잡한 광학적 현상을 재현할 수 있습니다.
NeRF 논문의 학습 원리는 다음과 같습니다:
NeRF는 주어진 2D 이미지들로부터 3D 장면을 학습하는 것이 목적입니다. 따라서 학습 데이터는 2D 이미지와 해당 이미지가 찍힌 카메라의 위치와 방향으로 구성됩니다. NeRF는 학습 데이터의 2D 이미지와 동일한 위치와 방향에서 광선을 생성하고, Volume Rendering을 통해 재현한 이미지를 생성합니다. 그리고 이 재현한 이미지와 학습 데이터의 2D 이미지와의 차이를 측정하여, 손실 함수를 정의합니다. NeRF는 손실 함수를 최소화하는 방향으로 MLP의 가중치를 업데이트합니다. 이렇게 하면 MLP는 주어진 위치와 방향에서 실제 장면과 유사한 색상과 밀도를 출력하도록 학습됩니다. NeRF는 학습 데이터에 없는 새로운 위치와 방향에서도 장면을 합성할 수 있습니다. 이는 MLP가 장면의 연속적인 표현을 학습하기 때문입니다.
위와 같은 알고리즘을 적용하면, NeRF는 적은 수의 2D 이미지만으로도 3D 장면을 재구성하고, 다양한 시점에서의 합성 이미지를 생성할 수 있습니다
저희 기업과 함께하시면 NeRF 모델을 활용하여 2D 이미지로부터 3D Scene 을 재구성하고, 다양한 응용 분야에 적용할 수 있습니다. 저희 기업의 NeRF 모델 핵심기술에 대해 더 알고 싶으시다면, 아래의 연락처로 자세히 문의해 주세요.
저희 기업과 함께하시면 NeRF 모델을 활용하여 2D 이미지로부터 3D Scene 을 재구성하고, 다양한 응용 분야에 적용할 수 있습니다. 저희 기업의 NeRF 모델 핵심기술에 대해 더 알고 싶으시다면, 아래의 연락처로 자세히 문의해 주세요.
StyleGAN V2 논문은 StyleGAN의 개선된 버전으로, Style Transfer 알고리즘을 이용하여 가상인간 아바타의 얼굴 Style Transfer를 구현 가능합니다. Style Transfer 알고리즘은 다음과 같은 과정으로 이루어집니다. StyleGAN V1 논문에서는 다음과 같은 기법들을 사용했습니다. Mapping Network : 잠재 벡터 z를 중간 잠재 공간 W로 매핑하는 네트워크입니다. W는 z보다 더 disentangled하고 smooth한 특성을 가지며, 각 스케일에 해당하는 스타일 벡터 w를 생성합니다. Synthesis Network : 스타일 벡터 w를 입력으로 받아 이미지를 생성하는 네트워크입니다. 각 레이어에서는 w와 노이즈 벡터를 결합하여 Adaptive Instance Normalization (AdaIN)을 수행합니다. AdaIN은 특징 맵의 평균과 분산을 w의 스타일 파라미터로 대체하는 방식으로, 스타일과 콘텐츠를 분리하고 조합할 수 있게 해줍니다. Style Mixing : 서로 다른 잠재 벡터 z1과 z2를 Mapping Network에 통과시켜 얻은 스타일 벡터 w1과 w2를 Synthesis Network의 일부 레이어에 적용하는 방식입니다. 이렇게 하면 다양한 스타일이 혼합된 이미지를 생성할 수 있으며, 학습 시에는 정규화 효과도 있습니다. StyleGAN V2 논문에서는 StyleGAN의 몇 가지 문제점을 개선하기 위해 다음과 같은 기법들을 추가했습니다. Weight Demodulation : Synthesis Network의 컨볼루션 레이어에서 가중치의 크기에 따라 특징 맵의 분산이 달라지는 문제를 해결하기 위해, 가중치를 정규화하는 방식입니다. 이렇게 하면 이미지의 품질이 향상되고, 스타일이 더 잘 전달됩니다. Path Length Regularization : 잠재 공간에서 작은 변화가 이미지에 큰 영향을 미치는 문제를 해결하기 위해, 잠재 벡터와 생성된 이미지 사이의 경로 길이를 측정하고 최소화하는 방식입니다. 이렇게 하면 잠재 공간이 더 smooth하고 disentangled해지며, 스타일 변화가 더 자연스럽게 이루어집니다. Skip Connections and Residual Connections : Synthesis Network의 깊이가 깊어짐에 따라 정보 손실과 그래디언트 소실 문제를 해결하기 위해, 입력과 출력 사이에 직접 연결하는 방식입니다. 이렇게 하면 이미지의 세부 사항이 더 잘 보존되고, 학습 속도가 빨라집니다.
StyleGAN V2 논문은 StyleGAN의 개선된 버전으로, Style Transfer 알고리즘을 이용하여 가상인간 아바타의 얼굴 Style Transfer를 구현 가능합니다. Style Transfer 알고리즘은 다음과 같은 과정으로 이루어집니다. AdaIN과 Weight Demodulation은 모두 StyleGAN에서 이미지의 스타일을 제어하기 위한 방법입니다. 그러나 두 방법은 다음과 같은 차이점을 가지고 있습니다. AdaIN은 특징 맵의 평균과 분산을 정규화하는 방법입니다. AdaIN은 각 레이어에서 잠재 벡터 w로부터 계산된 스타일 파라미터를 이용하여 특징 맵의 평균과 분산을 정규화합니다. AdaIN은 스타일 전달(style transfer)에서 영감을 받았으며, 이미지의 스타일과 콘텐츠를 분리하는 데 도움이 됩니다. Weight Demodulation은 합성곱 가중치의 크기를 정규화하는 방법입니다. Weight Demodulation은 AdaIN 대신 합성곱 가중치를 정규화하여 특징 맵의 크기에 영향을 주는 스타일 정보를 제거합니다. Weight Demodulation은 StyleGAN2에서 도입된 개선된 방법으로, AdaIN의 한계점인 물방울 모양의 아티팩트(artifacts)를 줄이기 위한 것입니다. 즉, AdaIN은 특징 맵 자체를 정규화하고, Weight Demodulation은 합성곱 가중치를 정규화한다는 점이 가장 큰 차이점입니다. 또한, AdaIN은 StyleGAN에서 사용되고, Weight Demodulation은 StyleGAN2에서 사용된다는 점도 차이점입니다.
Weight Demodulation의 합성곱 가중치 크기 정규화 관련 설계원리 및 구조는 다음과 같습니다. Weight Demodulation은 합성곱 가중치에 Weight Modulation과 Demodulation 두 가지 과정을 적용합니다. Weight Modulation은 스타일 벡터를 합성곱 가중치에 곱하는 것이고, Demodulation은 합성곱 가중치의 크기를 정규화하는 것입니다. Weight Demodulation은 StyleGAN에서 발생하는 artifact라는 결함을 해결하기 위해 도입되었습니다. Artifact란 합성된 이미지에 일부 영역이 주변과 불일치하는 현상을 말합니다. 이는 합성곱 가중치의 크기가 너무 커서 입력 데이터의 세부 정보를 잃어버리기 때문에 발생한다고 추정됩니다. Weight Demodulation은 합성곱 가중치의 크기를 정규화함으로써, 입력 데이터의 세부 정보를 보존하고, artifact를 제거하며, 이미지 품질을 향상시킵니다. 또한, Weight Demodulation은 스타일 벡터와 합성곱 가중치 사이의 상호작용을 강화하고, 스타일 변화에 민감하게 반응하도록 합니다
Weight Modulation과 Demodulation의 목적과 이유에 대해 간단히 설명하겠습니다. Weight Modulation의 목적은 스타일 벡터를 합성곱 가중치에 반영하여, 이미지의 스타일을 제어하는 것입니다. Weight Modulation의 이유는 스타일 벡터와 합성곱 가중치 사이의 상호작용을 강화하고, 스타일 변화에 민감하게 반응하도록 하기 위해서입니다 . Weight Modulation은 스타일 벡터를 합성곱 가중치에 곱하는 것으로, 합성곱 가중치를 스타일 벡터에 따라 동적으로 변화시킵니다. Demodulation의 목적은 합성곱 가중치의 크기를 정규화하여, 이미지의 품질을 향상시키는 것입니다. Demodulation의 이유는 합성곱 가중치의 크기가 너무 커지거나 작아지면, 입력 데이터의 세부 정보를 잃어버리거나, 이미지에 결함을 유발할 수 있기 때문입니다 . Demodulation은 합성곱 가중치의 크기를 L2 norm으로 나누는 것으로, 합성곱 가중치의 크기를 1 에 가깝게 만듭니다.
제가 운영하는 딥 네트워크는 딥러닝 모델분석 전문가로서 기술컨설팅이 가능합니다. 저희는 고객의 요구와 목적에 맞게 최적의 딥 네트워크 설계와 구현을 도와드립니다. 저희는 고객의 데이터와 문제에 적합한 핵심 학습 알고리즘을 선택하고 적용합니다. 저희는 고객의 딥 네트워크의 성능과 안정성을 향상시키고 최적화합니다. 저희 회사와 함께라면 귀사의 딥러닝 모델의 핵심 알고리즘을 분석하는데 어떤 어려움도 없을 것입니다.
카메라 화질튜닝은 카메라가 촬영한 이미지를 보정하고 개선하는 과정입니다. 카메라 화질튜닝에는 여러 가지 요소가 있지만, 여기서는 감마 보정, 컬러 보정, 화이트밸런스 보정, 렌즈쉐이드 보정에 대해 알아보겠습니다. 감마 보정은 이미지의 명암 대비를 조절하는 과정입니다. 감마 값이 낮으면 이미지가 밝아지고, 높으면 어두워집니다. 감마 보정을 통해 이미지의 선명도와 색감을 향상시킬 수 있습니다. 컬러 보정은 이미지의 색상을 조절하는 과정입니다. 컬러 보정을 통해 이미지의 색온도, 채도, 색조 등을 변경할 수 있습니다. 컬러 보정은 이미지의 분위기와 표현력을 높일 수 있습니다. 화이트밸런스 보정은 이미지의 색상 균형을 조절하는 과정입니다. 화이트밸런스 보정을 통해 이미지의 색상이 자연스럽고 정확하게 나타날 수 있습니다. 화이트밸런스 보정은 이미지의 실제성과 명료성을 높일 수 있습니다. 렌즈쉐이드 보정은 이미지의 밝기 균형을 조절하는 과정입니다. 렌즈쉐이드 보정을 통해 이미지의 가장자리 부분이 어두워지는 현상을 줄일 수 있습니다. 렌즈쉐이드 보정은 이미지의 균일성과 왜곡을 줄일 수 있습니다. 카메라 화질튜닝시에는 위의 4가지 요소를 순서대로 진행하는 것이 좋습니다. 감마 보정부터 시작하여 컬러 보정, 화이트밸런스 보정, 렌즈쉐이드 보정 순으로 진행하면 이미지의 품질을 최적화할 수 있습니다. 카메라 화질튜닝의 최종 결과물을 얻으려면 앞에서 언급한 4가지를 어떻게 최적화하느냐에 따라 달라집니다. 최적화 방법은 카메라의 종류와 성능, 촬영 환경과 목적, 개인의 취향 등에 따라 다르므로 정답은 없습니다. 하지만 일반적으로 다음과 같은 원칙을 따르면 좋습니다. 딥 네트워크의 카메라 화질튜닝 솔루션 : 감마 값은 2.2 정도로 설정하면 대부분의 모니터에서 자연스럽게 보일 수 있습니다. 컬러 값은 RGB 채널별로 균형있게 조절하고, 색온도는 5000K~6500K 사이로 설정하면 중립적인 색감을 얻을 수 있습니다. 화이트밸런스 값은 촬영된 장면의 주광원에 맞추어 조절하면 자연스러운 색상 균형을 얻을 수 있습니다. 렌즈쉐이드 값은 이미지의 가장자리 부분의 밝기가 중앙 부분과 비슷하게 조절하면 균일한 밝기 균형을 얻을 수 있습니다. 카메라 화질 튜닝이란 카메라로 촬영한 영상의 화질을 개선하는 과정입니다. 카메라 화질 튜닝에는 다양한 알고리즘들이 사용됩니다. 예를 들어, 광원의 색온도 측정은 영상의 색상을 균일하고 자연스럽게 만들기 위해 광원의 색온도를 측정하고 보정하는 알고리즘입니다. 광원의 색온도는 영상의 화이트 밸런스에 영향을 줍니다. 감마 보정은 영상의 명암 대비를 조절하기 위해 감마 곡선을 적용하는 알고리즘입니다. 감마 보정은 영상의 밝기와 선명도에 영향을 줍니다. 컬러 보정은 영상의 색상을 조절하기 위해 컬러 매트릭스나 컬러 룩업 테이블을 사용하는 알고리즘입니다. 컬러 보정은 영상의 색감과 분위기에 영향을 줍니다. 화이트밸런싱 보정은 영상의 색온도를 조절하기 위해 화이트 밸런스 게인을 사용하는 알고리즘입니다. 화이트밸런싱 보정은 영상의 색온도와 색조에 영향을 줍니다. 노출시간 제어는 영상의 밝기를 조절하기 위해 노출시간을 제어하는 알고리즘입니다. 노출시간 제어는 영상의 밝기와 잡음에 영향을 줍니다. 렌즈 쉐이딩 보정은 렌즈로 인해 발생하는 영상의 밝기와 색상의 변화를 보정하는 알고리즘입니다. 렌즈 쉐이딩 보정은 영상의 균일성과 왜곡에 영향을 줍니다.
제가 운영하는 딥 네트워크는 카메라 화질튜닝 전문 기업으로서, 저희는 다음과 같은 기술들의 대표적인 화질튜닝 설계 알고리즘을 보유하고 있습니다. 제가 운영하는 딥 네트워크는 카메라 화질튜닝 전문 기업으로서, 저희는 다음과 같은 기술들의 대표적인 화질튜닝 설계 알고리즘을 보유하고 있습니다. 화이트밸런스 제어 기술 촬영 장면의 색온도에 따라 색상을 균형있게 조절합니다. 자연스러운 색감을 재현하고, 색상의 변화에 민감하게 반응합니다. 이 기술의 핵심은 색온도 센서를 통해 장면의 색온도를 측정하고, 적절한 화이트밸런스 알고리즘을 적용하여 영상의 RGB 값을 보정하는 것입니다. 화이트밸런스 제어 설계 알고리즘 파악에 성공해서 구현 가능 합니다. 렌즈 쉐이드 보정 기술 렌즈의 왜곡이나 결함으로 인한 영상의 불균형을 보정합니다. 깔끔하고 고르게 조명된 영상을 얻고, 영상의 품질을 향상시킵니다. 이 기술의 핵심은 렌즈의 광학적 특성을 분석하고, 영상의 각 픽셀에 대해 렌즈 쉐이드 보정 테이블을 참조하여 영상의 밝기와 색상을 보정하는 것입니다. 렌즈 쉐이드 보정 기술 설계 알고리즘 파악에 성공해서 구현 가능 합니다. 감마 보정 기술 영상의 명암비를 인간의 눈에 맞게 조절합니다. 세부적인 표현력과 대비감을 높이고, 영상의 밝기와 명도를 최적화합니다. 이 기술의 핵심은 영상의 감마 값을 설정하고, 감마 보정 테이블을 생성하여 영상의 각 픽셀에 대해 감마 보정 값을 적용하는 것입니다. 감마 보정 기술 설계 알고리즘 파악에 성공해서 구현 가능 합니다. 노출시간 제어 기술 영상의 밝기를 조절합니다. 너무 밝거나 어두운 장면을 적절하게 촬영하고, 영상의 선명도와 잡음을 줄입니다. 이 기술의 핵심은 영상의 평균 밝기를 측정하고, 노출시간 제어 알고리즘을 적용하여 카메라 센서가 받는 빛의 양을 조절하는 것입니다. 노출시간 제어 기술 설계 알고리즘 파악에 성공해서 구현 가능 합니다. 줌 렌즈 제어 기술 당신의 카메라는 단순히 확대와 축소만 하는 줌 렌즈가 아닙니다. 우리의 카메라 줌 제어 기술은 영상의 공간적 축소방법을 이용하여 콘트라스트 향상을 위한 누적 분포함수의 계산량을 감소시키고 하드웨어의 복잡성을 줄입니다. 또한 각 픽셀의 콘트라스트를 비교하여 가장 큰 값을 선택하고 이에 맞춰 줌 렌즈를 제어하여 선명한 화면을 얻습니다. 우리의 카메라 줌 제어 기업은 영상의 콘트라스트 향상과 선명도 향상을 동시에 실현하는 차별화된 알고리즘을 보유하고 있습니다. 멀리서도 선명하게 당신의 순간을 담아보세요 줌 렌즈 제어 기술 알고리즘 파악에 성공해서 구현 가능 합니다.
제가 최근에 한 2 년여 기간동안 전기차 모터제어 개발을 위한 국내외 논문분석 작업과 모터제어 칩셋을 개발 맟 양산하는 글로벌 대기업의 모터제어 기술자료를 같이 보면서 분석작업을 아래와 같이 진행했었읍니다 ...
리졸버를 사용한 모터 전류제어 알고리즘 구조는 dq 변환, 전류 제어기, dq 전향보상기로 구성되어 있습니다. 이들은 다음과 같이 연동되어 있습니다.
dq 변환은 리졸버의 출력 신호를 R/D 컨버터를 통해 디지털로 변환하고, 회전자의 각도 정보를 이용하여 3상 AC 전류를 dq 좌표계로 변환합니다. 이렇게 하면 모터의 자속과 토크를 분리하여 제어할 수 있습니다. 전류 제어기는 dq 좌표계에서 d축 전류와 q축 전류를 PI 제어기로 제어합니다. d축 전류는 자속을 생성하고, q축 전류는 토크를 생성합니다. PI 제어기는 오차에 비례하는 항과 오차의 적분에 비례하는 항으로 구성되며, 오차를 줄이고 정상 상태에서 제어값을 유지하는 역할을 합니다. PI 제어기의 출력 값은 dq 좌표계에서 3상 AC 전압으로 변환하기 위해 dq 전향보상기로 전달됩니다. dq 전향보상기는 회전자의 각속도 정보를 이용하여 PI 제어기의 출력 값을 3상 AC 전압으로 역변환합니다. 이때 회전자의 각속도에 따라 위상이 변화하므로, 이를 보상하기 위해 회전자의 각속도 정보가 필요합니다. 이 정보는 R/D 컨버터에서 얻을 수 있습니다. dq 전향보상기는 PI 제어기의 출력 값을 3상 AC 전압으로 변환하고, 이를 모터에 인가하여 모터의 속도와 토크를 제어합니다.
리졸버를 사용한 모터 전류제어 알고리즘 구조는 dq 변환, 전류 제어기, dq 전향보상기로 구성되어 있습니다. 이들은 다음과 같이 설계됩니다. dq 변환은 다음과 같이 설계됩니다. 리졸버의 출력 신호를 R/D 컨버터를 통해 디지털로 변환합니다. R/D 컨버터는 리졸버의 출력 신호를 샘플링하고, 각도 정보를 디지털 값으로 출력합니다. 회전자의 각도 정보를 이용하여 3상 AC 전류를 dq 좌표계로 변환합니다. dq 좌표계는 회전자의 각도에 따라 변하는 좌표계로, d축은 자속의 방향을 따르고, q축은 d축에 수직인 방향을 따릅니다. dq 변환을 통해 3상 AC 전류를 DC 전류로 간주할 수 있으며, 제어가 용이해집니다. 전류 제어기는 다음과 같이 설계됩니다. dq 좌표계에서 d축 전류와 q축 전류를 PI 제어기로 제어합니다. d축 전류는 자속을 생성하고, q축 전류는 토크를 생성합니다. PI 제어기는 오차에 비례하는 항과 오차의 적분에 비례하는 항으로 구성되며, 오차를 줄이고 정상 상태에서 제어값을 유지하는 역할을 합니다. PI 제어기의 출력 값은 dq 좌표계에서 3상 AC 전압으로 변환하기 위해 dq 전향보상기로 전달됩니다. dq 전향보상기는 다음과 같이 설계됩니다. 회전자의 각속도 정보를 이용하여 PI 제어기의 출력 값을 3상 AC 전압으로 역변환합니다. 이때 회전자의 각속도에 따라 위상이 변화하므로, 이를 보상하기 위해 회전자의 각속도 정보가 필요합니다. 이 정보는 R/D 컨버터에서 얻을 수 있습니다. PI 제어기의 출력 값을 3상 AC 전압으로 변환하고, 이를 모터에 인가하여 모터의 속도와 토크를 제어합니다.
전향보상기란 BLDC 모터의 회전자가 합성자속에 정확하게 정렬되지 않고, 항상 앞서거나 뒤지는 현상을 보상하는 장치입니다. 전향보상기는 리졸버 R/D 컨버터에서 받은 각도 정보를 사용하여 회전자의 전향각을 추정하고, 이를 정현파 참조 신호의 위상에 반영하여 U, V, W 상의 전류 명령값을 보정합니다. 예를 들어, 회전자가 합성자속보다 10도 앞서면, 정현파 참조 신호의 위상을 10도 뒤로 늦추어 전류 명령값을 계산합니다. 반대로, 회전자가 합성자속보다 10도 뒤지면, 정현파 참조 신호의 위상을 10도 앞으로 당겨서 전류 명령값을 계산합니다. 이렇게 보정된U, V, W 상의 전류 명령값으로 어떻게 전향보상기 전류제어가 모터제어 샘플링 주기단위로 제어되는지 논하기 위해서는다음과 같은 내용을 포함해야 합니다. 전향보상기 전류제어란 인버터 회로를 통해 코일에 인가되는 전압과 전류를 제어하여 원하는 전류 명령값을 따르게 하고, 동시에 회전자와 합성자속의 정렬 오차를 최소화하는 과정입니다. 전향보상기 전류제어는 일반적으로 PWM 방식을 사용하여 인버터 회로에 입력되는 신호를 조절합니다. PWM 방식은 스위치의 ON/OFF 시간의 길이를 조정하여 전압과 전류의 크기를 변화시키는 방법입니다. 전향보상기 전류제어는 모터제어 샘플링 주기단위로 수행됩니다. 모터제어 샘플링 주기란 제어기가 리졸버 R/D 컨버터에서 각도 정보를 받고, 이를 사용하여 회전자의 전향각을 추정하고, 이를 정현파 참조 신호의 위상에 반영하여 U, V, W 상의 보정된 전류 명령값을 계산하고, 코일에서 측정한 전류 피드백값과 비교하여 오차를 줄이는 PID 제어 알고리즘을 수행하고, PID 제어 결과값을 PWM 신호로 변환하여 인버터 회로에 입력하는 과정을 반복하는 시간 간격입니다. 모터제어 샘플링 주기는 일반적으로 정현파 참조 신호의 주기보다 훨씬 짧아야 합니다. 예를 들어, 정현파 참조 신호의 주기가 20ms라면, 모터제어 샘플링 주기는 0.1ms ~ 1ms 정도로 설정할 수 있습니다.
dq 전향보상기란 무엇인가 ? 역기전력 성분이란 무엇이고 왜 보상해야 하는가 ? 모터제어 알고리즘 구조는 어떻게 되는가 ?
dq 전향보상기란 PMSM(영구자석 동기 모터)의 전압 방정식 모델에서 역기전력에 의한 성분을 제거하고 전류 제어기의 성능을 향상시키기 위해 사용하는 제어 기법입니다. 역기전력이란 모터가 회전할 때 자석과 코일 사이에 발생하는 전압으로, 전류와 반대 방향으로 작용하여 전류를 방해하는 효과를 가집니다. 역기전력 성분을 보상하지 않으면 전류 제어 오차가 커지고 모터의 토크가 불안정해질 수 있습니다. 모터제어 알고리즘 구조는 dq 변환, 전류 제어기, dq 전향보상기로 나누어서 설명할 수 있습니다. dq 변환은 3상 전류를 회전 좌표계로 변환하여 벡터 제어를 가능하게 합니다. 전류 제어기는 PI 제어기와 모터의 RL 회로로 구성되며, dq 지령과 센싱된 dq 전류를 비교하여 dq 전류 출력을 발생시킵니다. dq 전향보상기는 역기전력에 의한 성분을 계산하여 인가전압에 더해주어 역기전력을 보상합니다.
저희 딥 네트워크는 BLDC Motor 의 dq 전향보상기 개발 노하우와 전류제어 메커니즘의 구현 노하우를 보유하고 있읍니다 ...
BLDC Motor 펌웨어의 프로토타입 개발기간 이후 양산대응을 위한 안정화 개발기간이 필요합니다 ... BLDC Motor 펌웨어의 프로토타입 개발에 필요한 상세 개발규격을 메일로 전달 부탁드립니다 ...
임베디드 펌웨어 개발 30 년차 입니다 ... BLDC Motor 전류제어 / PI 제어 / 속도제어 개발 가능 합니다 ...
개발 및 자문 문의주시면 세부 개발사양 검토후 검토의견 드리겠읍니다 ...
제가 운영하는 일인기업 딥 네트워크 장석원
제가 어떤것들을 그동안 검토분석을 했는지를 소개하는 저의 일인기업 기업블로그 사이트 입니다 ...
제가 사업화를 준비했던 기술들 몇가지에 대해 사업화 준비 내용을 소개하는 기업블로그 입니다 ...
그동안 2 년 가까이 BLDC/PMSM 모터제어로 전류를 정밀하게 제어하는 방법을 찾으려고 관련 논문을 수백편 뒤져서 최근에 모터의 정밀 전류제어 구현 기법을 99 % 터득에 성공했다 ...
저는 그동안 모터제어만 판것은 아니고 카메라 이미지센서의 화질 보정 알고리즘을 터득하려고 논문과 특허를 수도 없이 뒤져서 결국 터득에 성공했다 ...
밥벌이를 하려고 이것만 한것은 아니다 ...
딥러닝 NeRF 논문과 StyleGAN 논문의 핵심 딥러닝 모델 설계 구조를 파악하느라 고생 좀 했다 ...
또한 구글 Transformer Model 기반으로 음성인식 구현을 위한 딥러닝 모델 세부 설계구조 분석도 결코 쉽지 않았다 ...
이것으로 밥벌이를 하려 99% 준비해 놨는데 경기가 죽어서 일꺼리 얻기가 하늘에 별따기라 너무 힘들다 ...
이렇게 힘들어도 나는 자신있다 왜냐하면 위에서 언급한 99 점 짜리 기술이 몇가지가 있으니 언젠가 반드시 기회가 오리라 나는 확신하기 때문이다 ...
제가 운영하는 딥 네트워크는 다음과 같은 프로토타입 구현 기술들을 보유하고 있습니다.
RabbitMQ Service는 AMQP 프로토콜을 구현한 메시지 브로커 시스템입니다. RabbitMQ Service의 Exchange는 메시지를 받아서 Binding 규칙에 따라 연결된 Queue로 전달하는 역할을 합니다.
RabbitMQ Service 의 Exchange는 다음과 같은 메시지 전달 방식을 가질 수 있습니다. Direct Exchange: 메시지에 포함된 routing key를 기반으로 Queue에 메시지를 전달합니다. routing key가 일치하는 Queue로만 전달됩니다. Fanout Exchange: routing key 관계없이 연결된 모든 Queue에 동일한 메시지를 전달합니다. publish/subscribe 패턴에 적합합니다. Topic Exchange: routing key 전체가 일치 하거나 일부 패턴과 일치하는 모든 Queue로 메시지가 전달됩니다. 와일드 카드(*)와 해시(#)를 이용해 routing key를 표현할 수 있습니다. Headers Exchange: 메시지 헤더를 통해 binding key만을 사용하는 것보다 더 다양한 속성을 사용할 수 있습니다. Header exchange를 사용하면 binding key는 무시되고, 헤더 값이 바인딩 시 지정된 값과 같은 경우에만 일치하는 것으로 간주합니다.
RabbitMQ Service 의Exchange와 Queue를 바인딩하는 설계 방법은 다음과 같습니다. Exchange와 Queue를 생성합니다. Queue는 반드시 미리 정의해야 사용할 수 있습니다. Binding을 추가합니다. Binding은 Exchange와 Queue를 Link하는 것입니다. Binding 시에 목적지 Queue 이름만으로도 추가할 수 있고, 일부 Exchange type에 따라 routing key를 지정해서 메시지를 필터링 한 후 지정한 Queue로 보내도록 정의할 수 있습니다. Producer가 메시지를 특정 Exchange & Queue에 전달하면, RabbitMQ는 해당 메시지를 적절한 Consumer가 소비(Consume)할 수 있도록 해당 메시지를 전달하는 역할을 수행합니다.
RabbitMQ Service 의Queue에서 메시지를 받는 방법은 다음과 같습니다. Consumer 어플리케이션은 Queue를 통해 메시지를 가져갑니다. Consumer 어플리케이션에서 Broker로 많은 연결을 맺는 것은 바람직하지 않으므로, 하나의 연결을 공유하는 Channels을 사용합니다. Consumer 어플리케이션은 Channel을 통해 Queue에 접근하고, subscribe 또는 pull 방식으로 메시지를 받아갑니다. subscribe 방식은 Queue에서 새로운 메시지가 도착하면 자동으로 Consumer에게 알려주는 방식이고, pull 방식은 Consumer가 직접 Queue에서 메시지를 가져오는 방식입니다. Consumer 어플리케이션은 받은 메시지를 처리하고, Broker에게 수신 확인(acknowledgement)을 보냅니다. 이때 Broker는 Queue에서 해당 메시지를 삭제합니다. 수신 확인 모델은 명시적으로 Broker에게 통지하는 방식과 Broker가 메시지를 전달하면 자동으로 삭제하는 방식이 있습니다.
클라우드 서비스 RabbitMQ를 사용한 메시지 큐 통신 방식으로 Publish/Subscribe 구현 기술 : 이 기술은 클라우드 서비스인 RabbitMQ를 이용하여 메시지를 발행하고 구독하는 방식으로 통신하는 기술입니다. 이를 통해 다수의 클라이언트와 서버 간에 실시간으로 데이터를 교환할 수 있습니다. 이 기술의 장점은 메시지의 안정성과 확장성을 보장하고, 네트워크 부하를 분산시킬 수 있다는 것입니다. 이 기술은 대규모 방송 서비스에서 다양한 콘텐츠를 전달하고 수신하는 데 적합합니다.
네트웍 장비 L3 / L4 장비의 네트웍 라우팅 정보 제어 기술 : 이 기술은 네트워크 장비인 L3 스위치와 L4 로드밸런서의 라우팅 정보를 제어하는 기술입니다. 이를 통해 네트워크 트래픽을 효율적으로 분배하고, 장애 복구와 보안을 강화할 수 있습니다. 이 기술의 장점은 네트워크 성능과 안정성을 향상시키고, 다양한 프로토콜과 애플리케이션을 지원한다는 것입니다. 이 기술은 대규모 방송 서비스에서 고속의 데이터 전송과 접속자 관리에 필요합니다.
대규모 방송 서비스 구현을 위한 프로토타입 설계 기술 : 이 기술은 위에서 언급한 두 가지 기술을 결합하여 대규모 방송 서비스를 구현하기 위한 프로토타입을 설계하는 기술입니다. 이를 통해 실제 서비스 환경에서의 성능과 안정성을 검증하고, 개선점을 도출할 수 있습니다. 이 기술의 장점은 실제 서비스에 적용하기 전에 문제점을 발견하고 해결할 수 있고, 최적의 서비스 구조와 아키텍처를 설계할 수 있다는 것입니다. 이 기술은 대규모 방송 서비스의 개발과 운영에 필수적입니다.
저는 이러한 기술들을 바탕으로 대규모 방송 서비스의 프로토타입을 구현하고, 사업화 개발 및 자문을 진행하고 있습니다. 저의 사이트에서 저의 포트폴리오와 경력을 확인하실 수 있습니다. 저와 함께라면 더욱 효율적이고 창의적인 대규모 방송 서비스를 만들 수 있습니다.
딥네트워크는 PMSM 모터를 제어하는 획기적인 솔루션을 제공하는 일인기업입니다. 딥네트워크는 TI의 모터제어 개발 보드를 사용하여 FOC 알고리즘과 TI의 InstaSPIN-FOC 소프트웨어 라이브러리를 기반으로 한 펌웨어 설계 세부 검토 분석을 수행하였습니다.
저는 모터제어시 TI 사의FOC 알고리즘을 다음과 같이 적용합니다 ....
FOC 알고리즘은 Field Oriented Control의 약자로, 모터의 자기장의 크기와 방향을 정밀하게 제어하여 토크를 안정적이고 효율적으로 제어하는 기법입니다. FOC 알고리즘 관련 제가 확보한 기술을 소개드리겠읍니다 ... 엔코더 기반 FOC 모터제어 펌웨어 구현 세부 노하우를 보유하고 있읍니다 ...
센서리스 FOC와 엔코더 기반 FOC는 모두 고성능 모터 제어를 위한 기술이지만, 각각의 특성과 장단점이 있습니다.
엔코더 기반 FOC 모터제어 펌웨어 구현 세부 노하우를 보유하고 있으며 전기차 모터제어 전문 딥네트워크는 펌웨어를 커스토마이징 가능 합니다. DQ 벡터제어 PMSM 모터의 펌웨어 설계 알고리즘의 세부 동작원리 파악에 성공했기에 위에서 제가 설명드린 TI PMSM Motor Controller Chipset 을 적용해서 TI 의InstaSPIN-FOC 소프트웨어 라이브러리를 적용해서 구현하는 노하우를 보유하고 있읍니다 ...
제가 모터제어 구현시 다음과 같이 전기차 PMSM 모터 제어시 FOC 제어를 다음과 같이 설계합니다:
회전자 위치 감지: 모터의 정확한 회전자 위치를 파악하기 위해 센서를 사용합니다.
클라크 변환 (Clarke Transformation): 3상 전류를 2상 전류로 변환합니다.
파크 변환 (Park Transformation): 회전자 위치에 따라 변환된 2상 전류를 (d)-축과 (q)-축 전류로 분리합니다.
PI 제어기: d 축과 q 축 전류를 조절하여 원하는 토크와 속도를 얻습니다.
역 파크 변환 (Inverse Park Transformation): d 축과 q 축 전류를 다시 3상 전류로 변환합니다.
역 클라크 변환 (Inverse Clarke Transformation): 2상 전류를 3상 전류로 변환하여 인버터를 통해 모터에 공급합니다.
제가 파악하고 있는 전기차 모터제어 펌웨어 설계의 세부 동작 원리 .
회전자 위치 검출 (Position Sensing):
전향보상기 제어는 모터의 회전자 위치를 정확하게 파악해야 합니다. 이를 위해 홀 센서(Hall sensor)나 엔코더(Encoder)와 같은 위치 센서를 사용합니다.
홀 센서는 회전자의 자기장 변화를 감지하여 회전자의 위치를 알려줍니다. 엔코더는 회전자의 각도를 디지털 신호로 변환하여 제어 시스템에 전달합니다.
전류 제어 (Current Control):
모터의 상류에는 고정자 코일이 있습니다. 이 코일에 전류를 공급하여 회전자를 움직입니다.
PWM(Pulse Width Modulation) 제어를 사용하여 고정자 코일에 가변 전압을 적용합니다. PWM 듀티 사이클을 조절하여 평균 전압을 제어합니다.
전류 제어는 모터의 토크와 속도를 조절하는 핵심 요소입니다.
전향보상기 제어 (Field-Oriented Control, FOC):
FOC는 모터의 회전자 위치를 기반으로 고정자 코일에 전류를 공급하는 방식입니다.
회전자 위치를 감지한 후, (d)-축과 (q)-축으로 전류를 변환합니다. (d)-축은 회전자 자기장 방향, (q)-축은 회전자 자기장과 수직 방향입니다.
PI 제어기는 토크 오차를 측정하고, 이를 통해 (d)-축과 (q)-축 전류를 조절합니다.
PI 제어기는 토크와 속도를 안정적으로 유지하며, 최적의 토크를 생성합니다.
이렇게 회전자 위치 검출, 전류 제어, FOC, PI 제어기를 조합하여 전향보상기 제어를 구현합니다. 이는 모터의 최적 토크를 생성하고 효율적으로 운전할 수 있도록 합니다.
저의 경우 로봇 축 관절제어를 위한 BLDC Motor 의 토크/위치/속도 제어를 위한 모터 제어 펌웨어가 어떤 설계 구조로 구현하는지를 파악하는데 성공했읍니다 ... 전기차 모터제어도 모터 전기 상수인자들 로 전달함수를 설계하면 2 차 라플라스 방정식이 되고 이것으로 제어응답 특성 파악이 가능은 한데 여기에 PI 제어 루프 도 전달함수에 포함되면 3 차 라플라스 방정식이 되는데 이것의 제어응답 특성을 파악하려면 MATLAB SIMULINK TOOL 이 반드시 필요합니다 저는 현재 2 차 라플라스 방정식의 응답특성 분석은 가능한 상태 입니다 로봇 축 관절제어를 위한 모터제어 프로토타입 펌웨어 구현 정도의 노하우를 확보했구요 ... 저도 구글링 2000 번 넘는 시행착오(국내외 논문분석)를 거쳐 3 년여만에 제가 원하는 돈이 되는 세부 정보를 얻는데 성공했읍니다 .... 제가 확보한 BLDC 모터 정밀제어 노하우는 위치제어 / 속도제어 / 토크제어를 Closed Loop PI 제어를 하는데 필요한 제어 알고리즘 수식을 확보해서 이해하는데 성공했읍니다 ... BLDC Motor 로 위치제어 / 속도제어 / 토크제어를 Closed Loop PI 제어를 하려면 BLDC Motor 는 어떤 규격의 것을 선택해야 하는지와 이는 또 어느 업체에서 이를 취급하는지 등등도 파악하고 있읍니다 ... 4 Pole - BLDC Motor 제어를 PWM 구동 방식으로 6 - STEP Sequence 로 제어하려면 세부적으로 어떻게 제어해야 하는지 등등도 파악에 성공했읍니다 ...
TI 사 BMS 칩셋인 EMB1428Q는 SPI 버스 인터페이스를 통해 충전/방전 명령을 수신하는 동작 구조와 에너지 이동을 위한 12개의 플로팅 MOSFET 게이트 드라이버를 제어하는 설계 원리에 대해 다음과 같이 설명할 수 있습니다:
밸런싱 실행: EMB1428Q는 EMB1499 DC/DC 컨트롤러 IC와 함께 작동하여, 필요한 시점에 적절한 셀 간 연결을 활성화시키고 에너지를 효율적으로 전송합니다.
저의 전기차 바테리 BMS 개발 보드의펌웨어 설계 커스토마이징 노하우 소개
이러한 과정을 통해 EMB1428Q는 배터리 팩의 전체 성능을 최적화하고, 각 셀의 수명을 균일하게 유지하며, 전체 시스템의 안정성과 효율성을 높이는 데 기여합니다. 저희 딥네트워크가 바테리 BMS 설계도 깊이있게 검토 분석을 하다 보니 깨닭은게 BMS 설계에 최적화된 바테리 HW 스택을 설계하는것을 빈틈없이 HW 설계를 하면 아무래도 BMS 펌웨어의 성능은 BMS HW 설계 범주내에서 펌웨어 성능이 나올수 있는것 같읍니다 ... TI 의 EMB1428Q 칩셋이 SPI 버스 인터페이스를 통해 충전/방전 명령을 수신하는 동작 구조와 에너지 이동을 위한 12개의 플로팅 MOSFET 게이트 드라이버를 제어하는 펌웨어 설계 원리를 파악에 성공했읍니다 저는 이를 위해 MOSFET 스위칭 제어를 위한 설계 방법 파악을 통해에너지 이동을 위한 플로팅 MOSFET 게이트 드라이버 제어를 TI 사 EMB1428Q칩셋을 적용해 펌웨어로 BMS 펌웨어 구현 노하우도 확보 성공했읍니다 ... 제가 파악한바로는 BMS HW 설계의 핵심은 셀 충방전 회로 설계시 스위치 캐패시티드 네트워크로 설게하는데 이때 MOSFET 스위칭 소자의 게이트 구동회로 설계시 MOSFET 회로가 플로팅됬을때 게이트 구동회로에 인가전압을 어떻게 인가하도록 설계하는냐가 핵심인데 이것도 파악에 성공했읍니다 ...
저희 회사는 전기차 바테리 충전 제어 전문 일인기업으로서, TI 사 EMB1428Q 칩셋을 활용하여 삼성 21700 50E / 7S 20P 바테리 셀의 충전 성능을 극대화할 수 있는 펌웨어와 기법을 분석하였습니다.저희 회사의 제품과 서비스에 관심이 있으시다면, 저희 기업 블로그 사이트를 방문하시거나 연락주시기 바랍니다. 감사합니다.
그동안 2 년 가까이 BLDC/PMSM 모터제어로 전류를 정밀하게 제어하는 방법을 찾으려고 관련 논문을 수백편 뒤져서 최근에 모터의 정밀 전류제어 구현 기법을 99 % 터득에 성공했다 ...
저는 그동안 모터제어만 판것은 아니고 카메라 이미지센서의 화질 보정 알고리즘을 터득하려고 논문과 특허를 수도 없이 뒤져서 결국 터득에 성공했다 ...
밥벌이를 하려고 이것만 한것은 아니다 ...
딥러닝 NeRF 논문과 StyleGAN 논문의 핵심 딥러닝 모델 설계 구조를 파악하느라 고생 좀 했다 ...
또한 구글 Transformer Model 기반으로 음성인식 구현을 위한 딥러닝 모델 세부 설계구조 분석도 결코 쉽지 않았다 ...
이것으로 밥벌이를 하려 99% 준비해 놨는데 경기가 죽어서 일꺼리 얻기가 하늘에 별따기라 너무 힘들다 ...
이렇게 힘들어도 나는 자신있다 왜냐하면 위에서 언급한 99 점 짜리 기술이 몇가지가 있으니 언젠가 반드시 기회가 오리라 나는 확신하기 때문이다 ...
NeRF 논문은 Neural Radiance Fields라는 새로운 방식으로 3D 장면을 표현하고, 다양한 시점에서의 합성 이미지를 생성하는 방법을 제안했습니다. NeRF는 다음과 같은 알고리즘으로 구현됩니다. NeRF 논문의 몇가지 핵심 알고리즘의 설계구조와 동작원리를 확실히 파악하는데 성공했읍니다 ... Positional Encoding : 3차원 좌표 x와 View Direction d를 고차원 벡터로 변환하는 과정입니다. 이때, 고주파 성분을 보존하기 위해 삼각함수를 이용한 인코딩 방식을 사용합니다. 즉, x와 d에 각각 다른 주파수와 위상을 가진 사인과 코사인 함수를 적용하여 특징 벡터를 생성합니다. 이렇게 하면 x와 d의 작은 변화에도 민감하게 반응할 수 있습니다. Multi-Layer Perceptron (MLP) : Positional Encoding된 특징 벡터를 입력으로 받아 해당 위치에서 바라 본 Color와 Density를 출력하는 네트워크입니다. MLP는 여러 개의 Fully Connected Layer로 구성되며, 각 레이어에서는 ReLU 활성화 함수와 Skip Connection을 사용합니다. MLP의 마지막 레이어에서는 Color는 RGB 값으로, Density는 스칼라 값으로 출력됩니다. Classical Volume Rendering : MLP에서 출력된 Color와 Density를 이용하여 합성 이미지를 생성하는 과정입니다. 이때, 카메라에서부터 장면까지의 광선을 따라서 여러 개의 샘플 포인트를 추출하고, 각 포인트에서의 Color와 Density를 MLP에 입력하여 계산합니다. 그리고, 샘플 포인트들의 Color와 Density를 가중 평균하여 최종적인 픽셀 값을 결정합니다. 이때, 가중치는 광선의 방향과 거리에 따라 달라지며, Density가 높을수록 더 많은 빛을 흡수하고 반사한다고 가정합니다.
NeRF 논문은 NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis라는 제목으로 2020년 ECCV에 발표된 논문입니다. 이 논문은 몇 개의 2D 이미지만으로도 이미지 내 물체를 3D로 렌더링하는 새로운 방법을 제안하였습니다.
NeRF 논문의 주요 설계 구조는 다음과 같습니다:
Positional Encoding: NeRF는 3D 공간의 좌표와 방향을 입력으로 받아서, 각 위치에서의 색상과 밀도를 출력하는 신경망입니다. 하지만 신경망은 고차원의 주기적인 함수를 잘 근사하지 못하기 때문에, 입력을 그대로 사용하면 고해상도의 장면을 표현하기 어렵습니다. 따라서 NeRF는 입력을 Positional Encoding이라는 방법으로 변환하여 사용합니다. Positional Encoding은 각 차원의 값을 사인과 코사인 함수에 넣어서 여러 개의 주파수를 가진 값들로 확장하는 과정입니다. 이렇게 하면 신경망이 공간적인 변화에 더 잘 반응할 수 있습니다.
Multi-Layer Perceptron (MLP): NeRF는 Positional Encoding된 좌표와 방향을 입력으로 받아서, Multi-Layer Perceptron (MLP)라고 부르는 완전 연결 신경망에 통과시킵니다. MLP는 여러 개의 은닉층과 활성화 함수로 구성되어 있으며, 각 층에서는 선형 변환과 비선형 변환을 수행합니다. MLP의 마지막 층에서는 각 위치에서의 색상과 밀도를 출력합니다. 색상은 RGB 값으로 표현되며, 밀도는 투명도와 반대되는 개념으로 표현됩니다.
Volume Rendering: NeRF는 MLP를 통해 얻은 색상과 밀도를 이용하여, 장면을 합성하는 과정을 Volume Rendering이라고 부릅니다. Volume Rendering은 카메라와 장면 사이에 가상의 광선을 생성하고, 광선 위의 여러 점들에서 MLP를 평가하여 색상과 밀도를 얻습니다. 그리고 이들을 합성하여 광선이 카메라에 도달할 때의 최종 색상을 계산합니다. Volume Rendering은 광선 위의 점들이 서로 영향을 주고 받는 것을 모델링할 수 있기 때문에, 복잡한 광학적 현상을 재현할 수 있습니다.
NeRF 논문의 학습 원리는 다음과 같습니다:
NeRF는 주어진 2D 이미지들로부터 3D 장면을 학습하는 것이 목적입니다. 따라서 학습 데이터는 2D 이미지와 해당 이미지가 찍힌 카메라의 위치와 방향으로 구성됩니다. NeRF는 학습 데이터의 2D 이미지와 동일한 위치와 방향에서 광선을 생성하고, Volume Rendering을 통해 재현한 이미지를 생성합니다. 그리고 이 재현한 이미지와 학습 데이터의 2D 이미지와의 차이를 측정하여, 손실 함수를 정의합니다. NeRF는 손실 함수를 최소화하는 방향으로 MLP의 가중치를 업데이트합니다. 이렇게 하면 MLP는 주어진 위치와 방향에서 실제 장면과 유사한 색상과 밀도를 출력하도록 학습됩니다. NeRF는 학습 데이터에 없는 새로운 위치와 방향에서도 장면을 합성할 수 있습니다. 이는 MLP가 장면의 연속적인 표현을 학습하기 때문입니다.
위와 같은 알고리즘을 적용하면, NeRF는 적은 수의 2D 이미지만으로도 3D 장면을 재구성하고, 다양한 시점에서의 합성 이미지를 생성할 수 있습니다
저희 기업과 함께하시면 NeRF 모델을 활용하여 2D 이미지로부터 3D Scene 을 재구성하고, 다양한 응용 분야에 적용할 수 있습니다. 저희 기업의 NeRF 모델 핵심기술에 대해 더 알고 싶으시다면, 아래의 연락처로 자세히 문의해 주세요.
그동안 2 년 가까이 BLDC/PMSM 모터제어로 전류를 정밀하게 제어하는 방법을 찾으려고 관련 논문을 수백편 뒤져서 최근에 모터의 정밀 전류제어 구현 기법을 99 % 터득에 성공했다 ...
저는 그동안 모터제어만 판것은 아니고 카메라 이미지센서의 화질 보정 알고리즘을 터득하려고 논문과 특허를 수도 없이 뒤져서 결국 터득에 성공했다 ...
밥벌이를 하려고 이것만 한것은 아니다 ...
딥러닝 NeRF 논문과 StyleGAN 논문의 핵심 딥러닝 모델 설계 구조를 파악하느라 고생 좀 했다 ...
또한 구글 Transformer Model 기반으로 음성인식 구현을 위한 딥러닝 모델 세부 설계구조 분석도 결코 쉽지 않았다 ...
이것으로 밥벌이를 하려 99% 준비해 놨는데 경기가 죽어서 일꺼리 얻기가 하늘에 별따기라 너무 힘들다 ...
이렇게 힘들어도 나는 자신있다 왜냐하면 위에서 언급한 99 점 짜리 기술이 몇가지가 있으니 언젠가 반드시 기회가 오리라 나는 확신하기 때문이다 ...
저는 NeRF 논문, StyleGAN V2 논문, 초거대 모델 ChatGPT 모델에 적용되 있는 핵심 학습 알고리즘 구현이 실제로 어떻게 구체적으로 설계되 있는지를 깊이 있게 이해하고 있습니다. 저는 팀 구성없이 나 혼자 힘으로 논문을 분석해서 처리할 수 있는 능력을 갖추었습니다. 저는 NeRF 논문, StyleGAN V2 논문, 초거대 모델 ChatGPT 모델 의 여러 핵심 알고리즘을 자문하는 방식으로 도움을 드릴 수 있습니다.
StyleGAN V2 논문 모델 의 핵심 알고리즘 설계구조 및 원리를 확실히 파악 성공했읍니다 ...
StyleGAN V2 논문은 StyleGAN의 개선된 버전으로, Style Transfer 알고리즘을 이용하여 가상인간 아바타의 얼굴 Style Transfer를 구현 가능합니다. Style Transfer 알고리즘은 다음과 같은 과정으로 이루어집니다.
Mapping Network의 8개의 완전연결층(FC)이 z공간에서 잠재벡터들이 서로 가까이 있을수록 비슷한 스타일을 가지게 학습이 가능한 이유는 다음과 같습니다. Mapping Network는 z와 w 사이의 비선형 매핑을 가능하게 하고, 스타일의 다양성과 연속성을 증가시킵니다. Mapping Network는 z를 입력받아서 여러 층을 거치면서 비선형 변환을 수행하고, w를 출력합니다. 이때, w공간에서는 각 차원이 서로 독립적이고 의미있는 스타일 요소를 표현하도록 학습됩니다. Mapping Network는 Style Mixing Regularization이라는 기법을 사용하여 학습됩니다. 이 기법은 두 개의 잠재벡터(z1, z2)를 Mapping Network에 통과시켜서 두 개의 w벡터(w1, w2)를 얻고, 이 두 벡터를 Synthesis Network의 일부 층에서 섞어서 입력하는 방식입니다. 이렇게 하면 Synthesis Network가 다양한 스타일 조합에 적응하도록 하고, w공간에서의 스타일 요소들이 서로 연관되지 않도록 합니다. Mapping Network는 Perceptual Path Length라는 지표로 측정할 수 있는 z공간과 W공간 사이의 관계를 학습합니다. 이 지표는 z공간에서 잠재벡터를 작게 변화시켰을 때, 생성된 이미지가 얼마나 많이 변화하는지를 VGG16 모델을 이용하여 계산합니다. 이 지표가 작을수록 z공간에서 잠재벡터들이 서로 가까이 있을수록 비슷한 스타일을 가지고, 멀리 있을수록 다른 스타일을 가지도록 학습된 것입니다. 즉, Mapping Network는 z공간에서 잠재벡터들이 서로 가까운 위치에 있으면 비슷한 스타일 요소를 가진 w벡터로 변환하고, 서로 먼 위치에 있으면 다른 스타일 요소를 가진 w벡터로 변환하도록 학습됩니다. 그리고 Synthesis Network는 w벡터에 따라서 생성된 이미지의 스타일을 결정합니다. 따라서 Mapping Network의 8개의 완전연결층(FC)은 z공간에서 잠재벡터들이 서로 가까이 있을수록 비슷한 스타일을 가지게 학습이 가능합니다. AdaIN과 Weight Demodulation은 모두 StyleGAN에서 이미지의 스타일을 제어하기 위한 방법입니다. 그러나 두 방법은 다음과 같은 차이점을 가지고 있습니다. AdaIN은 특징 맵의 평균과 분산을 정규화하는 방법입니다. AdaIN은 각 레이어에서 잠재 벡터 w로부터 계산된 스타일 파라미터를 이용하여 특징 맵의 평균과 분산을 정규화합니다. AdaIN은 스타일 전달(style transfer)에서 영감을 받았으며, 이미지의 스타일과 콘텐츠를 분리하는 데 도움이 됩니다. Weight Demodulation은 합성곱 가중치의 크기를 정규화하는 방법입니다. Weight Demodulation은 AdaIN 대신 합성곱 가중치를 정규화하여 특징 맵의 크기에 영향을 주는 스타일 정보를 제거합니다. Weight Demodulation은 StyleGAN2에서 도입된 개선된 방법으로, AdaIN의 한계점인 물방울 모양의 아티팩트(artifacts)를 줄이기 위한 것입니다. 즉, AdaIN은 특징 맵 자체를 정규화하고, Weight Demodulation은 합성곱 가중치를 정규화한다는 점이 가장 큰 차이점입니다. 또한, AdaIN은 StyleGAN에서 사용되고, Weight Demodulation은 StyleGAN2에서 사용된다는 점도 차이점입니다.
Weight Demodulation의 합성곱 가중치 크기 정규화 관련 설계원리 및 구조는 다음과 같습니다. Weight Demodulation은 합성곱 가중치에 Weight Modulation과 Demodulation 두 가지 과정을 적용합니다. Weight Modulation은 스타일 벡터를 합성곱 가중치에 곱하는 것이고, Demodulation은 합성곱 가중치의 크기를 정규화하는 것입니다. Weight Demodulation은 StyleGAN에서 발생하는 artifact라는 결함을 해결하기 위해 도입되었습니다. Artifact란 합성된 이미지에 일부 영역이 주변과 불일치하는 현상을 말합니다. 이는 합성곱 가중치의 크기가 너무 커서 입력 데이터의 세부 정보를 잃어버리기 때문에 발생한다고 추정됩니다. Weight Demodulation은 합성곱 가중치의 크기를 정규화함으로써, 입력 데이터의 세부 정보를 보존하고, artifact를 제거하며, 이미지 품질을 향상시킵니다. 또한, Weight Demodulation은 스타일 벡터와 합성곱 가중치 사이의 상호작용을 강화하고, 스타일 변화에 민감하게 반응하도록 합니다
Weight Modulation과 Demodulation의 목적과 이유에 대해 간단히 설명하겠습니다. Weight Modulation의 목적은 스타일 벡터를 합성곱 가중치에 반영하여, 이미지의 스타일을 제어하는 것입니다. Weight Modulation의 이유는 스타일 벡터와 합성곱 가중치 사이의 상호작용을 강화하고, 스타일 변화에 민감하게 반응하도록 하기 위해서입니다 . Weight Modulation은 스타일 벡터를 합성곱 가중치에 곱하는 것으로, 합성곱 가중치를 스타일 벡터에 따라 동적으로 변화시킵니다. Demodulation의 목적은 합성곱 가중치의 크기를 정규화하여, 이미지의 품질을 향상시키는 것입니다. Demodulation의 이유는 합성곱 가중치의 크기가 너무 커지거나 작아지면, 입력 데이터의 세부 정보를 잃어버리거나, 이미지에 결함을 유발할 수 있기 때문입니다 . Demodulation은 합성곱 가중치의 크기를 L2 norm으로 나누는 것으로, 합성곱 가중치의 크기를 1 에 가깝게 만듭니다.
제가 운영하는 딥 네트워크는 딥러닝 모델분석 전문가로서 기술컨설팅이 가능합니다. 저희는 고객의 요구와 목적에 맞게 최적의 딥 네트워크 설계와 구현을 도와드립니다. 저희는 고객의 데이터와 문제에 적합한 핵심 학습 알고리즘을 선택하고 적용합니다. 저희는 고객의 딥 네트워크의 성능과 안정성을 향상시키고 최적화합니다. 저희 회사와 함께라면 귀사의 딥러닝 모델의 핵심 알고리즘을 분석하는데 어떤 어려움도 없을 것입니다.
제가 운영하는 일인기업 딥 네트워크 장석원
제가 사업화를 준비했던 기술들 몇가지에 대해 사업화 준비 내용을 소개하는 기업블로그 입니다 ...
그동안 2 년 가까이 BLDC/PMSM 모터제어로 전류를 정밀하게 제어하는 방법을 찾으려고 관련 논문을 수백편 뒤져서 최근에 모터의 정밀 전류제어 구현 기법을 99 % 터득에 성공했다 ...
저는 그동안 모터제어만 판것은 아니고 카메라 이미지센서의 화질 보정 알고리즘을 터득하려고 논문과 특허를 수도 없이 뒤져서 결국 터득에 성공했다 ...
밥벌이를 하려고 이것만 한것은 아니다 ...
딥러닝 NeRF 논문과 StyleGAN 논문의 핵심 딥러닝 모델 설계 구조를 파악하느라 고생 좀 했다 ...
또한 구글 Transformer Model 기반으로 음성인식 구현을 위한 딥러닝 모델 세부 설계구조 분석도 결코 쉽지 않았다 ...
이것으로 밥벌이를 하려 99% 준비해 놨는데 경기가 죽어서 일꺼리 얻기가 하늘에 별따기라 너무 힘들다 ...
이렇게 힘들어도 나는 자신있다 왜냐하면 위에서 언급한 99 점 짜리 기술이 몇가지가 있으니 언젠가 반드시 기회가 오리라 나는 확신하기 때문이다 ...
카메라 화질튜닝은 카메라가 촬영한 이미지를 보정하고 개선하는 과정입니다. 카메라 화질튜닝에는 여러 가지 요소가 있지만, 여기서는 감마 보정, 컬러 보정, 화이트밸런스 보정, 렌즈쉐이드 보정에 대해 알아보겠습니다. 감마 보정은 이미지의 명암 대비를 조절하는 과정입니다. 감마 값이 낮으면 이미지가 밝아지고, 높으면 어두워집니다. 감마 보정을 통해 이미지의 선명도와 색감을 향상시킬 수 있습니다. 컬러 보정은 이미지의 색상을 조절하는 과정입니다. 컬러 보정을 통해 이미지의 색온도, 채도, 색조 등을 변경할 수 있습니다. 컬러 보정은 이미지의 분위기와 표현력을 높일 수 있습니다. 화이트밸런스 보정은 이미지의 색상 균형을 조절하는 과정입니다. 화이트밸런스 보정을 통해 이미지의 색상이 자연스럽고 정확하게 나타날 수 있습니다. 화이트밸런스 보정은 이미지의 실제성과 명료성을 높일 수 있습니다. 렌즈쉐이드 보정은 이미지의 밝기 균형을 조절하는 과정입니다. 렌즈쉐이드 보정을 통해 이미지의 가장자리 부분이 어두워지는 현상을 줄일 수 있습니다. 렌즈쉐이드 보정은 이미지의 균일성과 왜곡을 줄일 수 있습니다. 카메라 화질튜닝시에는 위의 4가지 요소를 순서대로 진행하는 것이 좋습니다. 감마 보정부터 시작하여 컬러 보정, 화이트밸런스 보정, 렌즈쉐이드 보정 순으로 진행하면 이미지의 품질을 최적화할 수 있습니다. 카메라 화질튜닝의 최종 결과물을 얻으려면 앞에서 언급한 4가지를 어떻게 최적화하느냐에 따라 달라집니다. 최적화 방법은 카메라의 종류와 성능, 촬영 환경과 목적, 개인의 취향 등에 따라 다르므로 정답은 없습니다. 하지만 일반적으로 다음과 같은 원칙을 따르면 좋습니다. 딥 네트워크의 카메라 화질튜닝 솔루션 : 감마 값은 2.2 정도로 설정하면 대부분의 모니터에서 자연스럽게 보일 수 있습니다. 컬러 값은 RGB 채널별로 균형있게 조절하고, 색온도는 5000K~6500K 사이로 설정하면 중립적인 색감을 얻을 수 있습니다. 화이트밸런스 값은 촬영된 장면의 주광원에 맞추어 조절하면 자연스러운 색상 균형을 얻을 수 있습니다. 렌즈쉐이드 값은 이미지의 가장자리 부분의 밝기가 중앙 부분과 비슷하게 조절하면 균일한 밝기 균형을 얻을 수 있습니다.
카메라 화질 튜닝이란 카메라로 촬영한 영상의 화질을 개선하는 과정입니다. 카메라 화질 튜닝에는 다양한 알고리즘들이 사용됩니다. 예를 들어, 광원의 색온도 측정은 영상의 색상을 균일하고 자연스럽게 만들기 위해 광원의 색온도를 측정하고 보정하는 알고리즘입니다. 광원의 색온도는 영상의 화이트 밸런스에 영향을 줍니다. 감마 보정은 영상의 명암 대비를 조절하기 위해 감마 곡선을 적용하는 알고리즘입니다. 감마 보정은 영상의 밝기와 선명도에 영향을 줍니다. 컬러 보정은 영상의 색상을 조절하기 위해 컬러 매트릭스나 컬러 룩업 테이블을 사용하는 알고리즘입니다. 컬러 보정은 영상의 색감과 분위기에 영향을 줍니다. 화이트밸런싱 보정은 영상의 색온도를 조절하기 위해 화이트 밸런스 게인을 사용하는 알고리즘입니다. 화이트밸런싱 보정은 영상의 색온도와 색조에 영향을 줍니다. 노출시간 제어는 영상의 밝기를 조절하기 위해 노출시간을 제어하는 알고리즘입니다. 노출시간 제어는 영상의 밝기와 잡음에 영향을 줍니다. 렌즈 쉐이딩 보정은 렌즈로 인해 발생하는 영상의 밝기와 색상의 변화를 보정하는 알고리즘입니다. 렌즈 쉐이딩 보정은 영상의 균일성과 왜곡에 영향을 줍니다.
제가 운영하는 딥 네트워크는 카메라 화질튜닝 전문 기업으로서, 저희는 다음과 같은 기술들의 대표적인화질튜닝설계 알고리즘을 보유하고 있습니다.
제가 운영하는 딥 네트워크는 카메라 화질튜닝 전문 기업으로서, 저희는 다음과 같은 기술들의 대표적인 화질튜닝 설계 알고리즘을 보유하고 있습니다.
화이트밸런스 제어 기술
촬영 장면의 색온도에 따라 색상을 균형있게 조절합니다. 자연스러운 색감을 재현하고, 색상의 변화에 민감하게 반응합니다. 이 기술의 핵심은 색온도 센서를 통해 장면의 색온도를 측정하고, 적절한 화이트밸런스 알고리즘을 적용하여 영상의 RGB 값을 보정하는 것입니다.
해외특허나 논문에서 제시한 화이트밸런스 설계 제어 알고리즘 수식을 확보하고 있읍니다.
렌즈 쉐이드 보정 기술
렌즈의 왜곡이나 결함으로 인한 영상의 불균형을 보정합니다. 깔끔하고 고르게 조명된 영상을 얻고, 영상의 품질을 향상시킵니다. 이 기술의 핵심은 렌즈의 광학적 특성을 분석하고, 영상의 각 픽셀에 대해 렌즈 쉐이드 보정 테이블을 참조하여 영상의 밝기와 색상을 보정하는 것입니다.
해외특허나 논문에서 제시한 렌즈 쉐이드 보정 기술 설계 알고리즘 제어 수식을 확보하고 있읍니다.
감마 보정 기술
영상의 명암비를 인간의 눈에 맞게 조절합니다. 세부적인 표현력과 대비감을 높이고, 영상의 밝기와 명도를 최적화합니다. 이 기술의 핵심은 영상의 감마 값을 설정하고, 감마 보정 테이블을 생성하여 영상의 각 픽셀에 대해 감마 보정 값을 적용하는 것입니다.
해외특허나 논문에서 제시한 감마 보정 기술설계 알고리즘 제어 수식을 확보하고 있읍니다.
노출시간 제어 기술
영상의 밝기를 조절합니다. 너무 밝거나 어두운 장면을 적절하게 촬영하고, 영상의 선명도와 잡음을 줄입니다. 이 기술의 핵심은 영상의 평균 밝기를 측정하고, 노출시간 제어 알고리즘을 적용하여 카메라 센서가 받는 빛의 양을 조절하는 것입니다.
노출시간 제어 기술설계 알고리즘 파악에 성공해서 구현 가능 합니다.
줌 렌즈 제어 기술
당신의 카메라는 단순히 확대와 축소만 하는 줌 렌즈가 아닙니다. 우리의 카메라 줌 제어 기술은 영상의 공간적 축소방법을 이용하여 콘트라스트 향상을 위한 누적 분포함수의 계산량을 감소시키고 하드웨어의 복잡성을 줄입니다. 또한 각 픽셀의 콘트라스트를 비교하여 가장 큰 값을 선택하고 이에 맞춰 줌 렌즈를 제어하여 선명한 화면을 얻습니다. 우리의 카메라 줌 제어 기업은 영상의 콘트라스트 향상과 선명도 향상을 동시에 실현하는 차별화된 알고리즘을 보유하고 있습니다. 멀리서도 선명하게 당신의 순간을 담아보세요
줌 렌즈 제어 기술 알고리즘 구현 노하우를 보유하고 있읍니다 ...
저희는 이러한 기술들을 통합하여 최고의 카메라 화질튜닝 솔루션을 제공하고 있습니다. 저희와 함께라면 더욱 선명하고 생동감 있는 카메라 화질을 경험하실 수 있습니다.
제가 운영하는 딥 네트워크 의 Camera 3A 튜닝 관련 화질 보정 알고리즘 몇가지를 그동안 3 년에 걸쳐 분석 성공한 내용을 공개합니다 ... 카메라 3A 튜닝 기술중 우선 2 가지, Exposure 제어와 White balance 제어 관련해서 소개해 보겠읍니다 ... 카메라 영상 컬러 보정 알고리즘의 제어를 통해서는 카메라 영상 영역의 히스토그램 평활화을 통해서 카메라 이미지의 광원에 따른 영상의 선명도 보정 작업이 가능합니다. 여기에 화질 튜닝을 하려면 White balance 제어가 필요합니다 .... White Balance 제어는 카메라에 비춰지는 광원의 색온도를 측정을 통해 광원의 White balance 특성을 파악하게 되구요 ... 즉 광원의 특성에 따라 카메라 이미지의 White balance 제어 처리가 된 영상으로 보정되야 한다는것 입니다 ...
제가 운영하는 딥 네트워크는 Lens Shade Correction 기법 또한 노하우가 있읍니다 ... 카메라 이미지의 센터부는 밝기값 Y 값이 크고 카메라 이미지의 Edge 부분은 상대적으로 밝기값인 Y 값이 작읍니다 ... 따라서 이 Y 값을 카메라 이미지의 센터부와 카메라 이미지의 Edge 부의 중간 정도 값으로 카메라 이미지의 밝기값을 조정해 주는 작업이 Lens Shade Correction 기법이라고 파악하고 있읍니다 ...
딥 네트워크는 Gamma Correction 노하우 또한 있읍니다 ... 픽셀값을 밝게 하려면 Intensity 값을 크게 해주면 되구요 반대로 어둡게 하려면 Intensity 값을 작게 해줘야 합니다. Gamma Correction 은 모든 픽셀값에 대해서 동일한 값만큼 Intensity 값을 증가 시키지는 않읍니다. 밝게하거나 어둡게 할때 어두운 부분의 Intensity 값을 더 많이 변화시키게 됩니다 ...
Focus 제어의 경우
Contrast 값이 높게 나오는 부분이 Focus 가 잘 맞추어진 상태를 의미 하거든요 Focus 를 맞출 영역을 정의한후 그 영역이 Contrast 값이 높게 나오도록 포커싱 제어부를 제어를 해주면 된다고 판단하고 있읍니다 ... CZ(Continuous Zoom) 기능 구현을 위해 lookup 테이블에 따라 카메라모듈의 스테핑 모터가 동작하도록 구현하는 부분이 필요합니다 ...
Zoom 제어의 경우
시리얼 통신으로 카메라의 Zoom 을 제어하는 통신 프로토콜인 Pelco-D/P Protocol 를 사용해서 카메라의 Zoom 을 제어하는 부분의 구현이 필요하구요 ...
관련해서 카메라 보드 펌웨어 개발 및 Camera 3A 튜닝 개발문의 및 기술자문 문의 부탁드립니다 ....
이미지센서(카메라 보드) 펌웨어의 프로토타입 개발기간 이후 양산대응을 위한 안정화 개발기간이 필요합니다 ...
이미지센서(카메라 보드) 펌웨어의 프로토타입 개발에 필요한 상세 개발규격을 메일로 전달 부탁드립니다 ...
제가 운영하는 일인기업 딥 네트워크 장석원
제가 어떤것들을 그동안 검토분석을 했는지를 소개하는 저의 일인기업 기업블로그 사이트 입니다 ...
제가 사업화를 준비했던 기술들 몇가지에 대해 사업화 준비 내용을 소개하는 기업블로그 입니다 ...
그동안 2 년 가까이 BLDC/PMSM 모터제어로 전류를 정밀하게 제어하는 방법을 찾으려고 관련 논문을 수백편 뒤져서 최근에 모터의 정밀 전류제어 구현 기법을 99 % 터득에 성공했다 ...
저는 그동안 모터제어만 판것은 아니고 카메라 이미지센서의 화질 보정 알고리즘을 터득하려고 논문과 특허를 수도 없이 뒤져서 결국 터득에 성공했다 ...
밥벌이를 하려고 이것만 한것은 아니다 ...
딥러닝 NeRF 논문과 StyleGAN 논문의 핵심 딥러닝 모델 설계 구조를 파악하느라 고생 좀 했다 ...
또한 구글 Transformer Model 기반으로 음성인식 구현을 위한 딥러닝 모델 세부 설계구조 분석도 결코 쉽지 않았다 ...
이것으로 밥벌이를 하려 99% 준비해 놨는데 경기가 죽어서 일꺼리 얻기가 하늘에 별따기라 너무 힘들다 ...
이렇게 힘들어도 나는 자신있다 왜냐하면 위에서 언급한 99 점 짜리 기술이 몇가지가 있으니 언젠가 반드시 기회가 오리라 나는 확신하기 때문이다 ...
StyleGAN 논문의 딥러닝 모델은 고해상도의 사실적인 가상인간 이미지를 생성할 수 있는 강력한 기술입니다. 이 모델은 스타일 Transfer 메커니즘을 통해 다양한 스타일 요소를 조절하고 결합할 수 있습니다. 스타일 Transfer 메커니즘의 세부 동작원리는 다음과 같습니다.
StyleGAN V2 논문의 핵심 알고리즘 5 가지는 다음과 같습니다.
Normalization artifacts 제거 : StyleGAN V2는 기존의 GAN 모델들이 가지고 있던 물방울 모양의 아티팩트를 제거하였습니다. 이를 위해 스타일을 적용하는 방식을 혁신적으로 개선하고, 새로운 정규화 방법을 도입하였습니다. 이 알고리즘은 가상인간을 구현할 때, 피부나 머리카락 등의 세부적인 텍스처를 더욱 자연스럽고 선명하게 만들어줍니다. Path length regularization 도입 : StyleGAN V2는 latent space의 작은 변화가 생성된 이미지에 큰 영향을 미치지 않도록 하였습니다. 이를 위해 path length regularization이라는 새로운 방법을 사용하여 이미지 품질과 generator의 smoothness를 동시에 향상시켰습니다. 이 알고리즘은 가상인간을 구현할 때, 다양한 표정이나 감정을 부드럽게 표현할 수 있도록 도와줍니다. Progressive growing 개선 : StyleGAN V2는 progressive growing이라는 점진적으로 해상도를 높여가는 학습 방법을 대체하였습니다. 이 방법은 해상도별로 다른 특징이 나타나는 phase artifact라는 문제점을 가지고 있었습니다. StyleGAN V2는 skip connection과 residual connection을 결합하여 각 해상도의 feature map을 효율적으로 활용하고, capacity 문제를 해결하기 위해 상위 레이어의 feature map의 수를 증가시켰습니다. 이 알고리즘은 가상인간을 구현할 때, 고해상도의 이미지를 빠르고 안정적으로 생성할 수 있도록 도와줍니다. Style mixing 기법 도입 : StyleGAN V2는 latent space에서 뽑은 여러 개의 스타일 벡터를 각 레이어에 적용하여 다양한 스타일이 섞인 이미지를 생성할 수 있는 기법입니다. 이 기법은 style correlation이 발생하지 않도록 하며, regularization 효과도 줍니다. 이 알고리즘은 가상인간을 구현할 때, 원하는 스타일과 특징을 조합하여 맞춤형 이미지를 생성할 수 있도록 도와줍니다. Latent space로의 projection 기능 추가 : StyleGAN V2는 이미지를 latent space로 역투영하는 projection 기능을 추가하였습니다. 이 기능은 주어진 이미지와 가장 비슷한 latent vector를 찾아내어, 이미지를 수정하거나 변형하는데 사용할 수 있습니다. 이 알고리즘은 가상인간을 구현할 때, 실제 인간의 이미지를 latent space로 가져와서 원하는 방식으로 변경하거나 합성할 수 있도록 도와줍니다. 이상으로 StyleGAN V2 논문의 핵심 알고리즘 5 가지와 그것이 가상인간 구현에 어떻게 응용되는지에 대해 설명하였습니다. StyleGAN V2는 GAN 분야의 최첨단 기술로서, 가상인간을 구현하는데 매우 유용하고 강력한 모델입니다.
StyleGAN 논문 딥러닝 모델 설계구조 기술컨설팅은 StyleGAN의 아키텍처와 알고리즘을 이해하고, 적용하고, 개선하고자 하는 분들을 위한 서비스입니다.
저희 기업은 StyleGAN 논문의 딥러닝 모델의 세부 분석 기술력을 바탕으로 사업화가 가능한 가상인간 구현 분야와 관련해서 기술자문 사업을 제공합니다. 저희 기업과 함께하시면 StyleGAN 모델을 활용하여 원하는 가상인간 이미지를 쉽고 빠르게 생성하고, 다양한 응용 분야에 적용할 수 있습니다. 저희 기업의 StyleGAN 모델 세부 분석 기술력에 대해 더 알고 싶으시다면, 아래의 연락처로 문의를 자세히 해 주세요.
안녕하세요. 저는 딥 네트워크라는 일인기업입니다. 저는 GPT-3 모델, ChatGPT 모델, LLaMA 모델과 같은 딥러닝 초거대 모델의 핵심이 되는 학습 알고리즘을 연구하고 있습니다. 저는 이러한 모델들이 어떤 구조로 학습모델의 발전이 이루어졌는지를 깊이있게 분석하고 비교하였습니다. 저는 지난 2년간 다양한 논문들을 리뷰하고 요약하였으며, 최신의 연구동향과 트렌드를 파악하였습니다. 저는 이러한 분석 기술력을 바탕으로 딥러닝 초거대 모델의 학습 알고리즘의 원리와 동작 방식을 잘 이해하고 있습니다.
딥 네트워크는 ChatGPT 초거대 언어모델 기술컨설팅의 전문가입니다. 딥 네트워크는 딥러닝 모델 학습 구조 분석 기술력의 핵심을 다음과 같이 정리할 수 있습니다.
딥러닝 모델 학습 구조 분석 기술력은 딥러닝 모델의 원리와 구조를 이해하고, 모델의 성능과 한계를 평가하고, 모델의 튜닝과 수정을 통해 최적화하는 능력입니다. 딥 네트워크는 GPT-3 모델 학습 구조 분석에 성공한 후, ChatGPT 초거대 언어모델 기술컨설팅에도 큰 진전을 보여준 기업입니다. 딥 네트워크는 GPT-3 모델과 ChatGPT 모델의 학습 구조를 깊이 있게 분석하고, 고객에게 최적의 분석 결과를 제공합니다. 딥 네트워크는 딥러닝 모델 학습 구조 분석 기술력을 바탕으로, ChatGPT 초거대 언어모델의 강화학습 방식에 대한 이론적인 지식을 갖고 있습니다. 하지만, 딥 네트워크는 아직 ChatGPT 초거대 언어모델을 활용한 챗봇 개발 및 배포에 대한 경험은 없습니다. 딥 네트워크는 ChatGPT 초거대 언어모델 기술컨설팅의 전문가로서, 고객의 요구에 맞는 최고의 분석 서비스를 제공합니다.
딥 네트워크와 함께라면, ChatGPT 초거대 언어모델의 비밀을 풀 수 있습니다. 딥 네트워크에 문의하세요.
그동안 2 년 가까이 BLDC/PMSM 모터제어로 전류를 정밀하게 제어하는 방법을 찾으려고 관련 논문을 수백편 뒤져서 최근에 모터의 정밀 전류제어 구현 기법을 99 % 터득에 성공했다 ...
저는 그동안 모터제어만 판것은 아니고 카메라 이미지센서의 화질 보정 알고리즘을 터득하려고 논문과 특허를 수도 없이 뒤져서 결국 터득에 성공했다 ...
밥벌이를 하려고 이것만 한것은 아니다 ...
딥러닝 NeRF 논문과 StyleGAN 논문의 핵심 딥러닝 모델 설계 구조를 파악하느라 고생 좀 했다 ...
또한 구글 Transformer Model 기반으로 음성인식 구현을 위한 딥러닝 모델 세부 설계구조 분석도 결코 쉽지 않았다 ...
이것으로 밥벌이를 하려 99% 준비해 놨는데 경기가 죽어서 일꺼리 얻기가 하늘에 별따기라 너무 힘들다 ...
이렇게 힘들어도 나는 자신있다 왜냐하면 위에서 언급한 99 점 짜리 기술이 몇가지가 있으니 언젠가 반드시 기회가 오리라 나는 확신하기 때문이다 ...
카메라 화질튜닝은 카메라가 촬영한 이미지를 보정하고 개선하는 과정입니다. 카메라 화질튜닝에는 여러 가지 요소가 있지만, 여기서는 감마 보정, 컬러 보정, 화이트밸런스 보정, 렌즈쉐이드 보정에 대해 알아보겠습니다.
감마 보정은 이미지의 명암 대비를 조절하는 과정입니다. 감마 값이 낮으면 이미지가 밝아지고, 높으면 어두워집니다. 감마 보정을 통해 이미지의 선명도와 색감을 향상시킬 수 있습니다. 컬러 보정은 이미지의 색상을 조절하는 과정입니다. 컬러 보정을 통해 이미지의 색온도, 채도, 색조 등을 변경할 수 있습니다. 컬러 보정은 이미지의 분위기와 표현력을 높일 수 있습니다. 화이트밸런스 보정은 이미지의 색상 균형을 조절하는 과정입니다. 화이트밸런스 보정을 통해 이미지의 색상이 자연스럽고 정확하게 나타날 수 있습니다. 화이트밸런스 보정은 이미지의 실제성과 명료성을 높일 수 있습니다. 렌즈쉐이드 보정은 이미지의 밝기 균형을 조절하는 과정입니다. 렌즈쉐이드 보정을 통해 이미지의 가장자리 부분이 어두워지는 현상을 줄일 수 있습니다. 렌즈쉐이드 보정은 이미지의 균일성과 왜곡을 줄일 수 있습니다. 카메라 화질튜닝시에는 위의 4가지 요소를 순서대로 진행하는 것이 좋습니다. 감마 보정부터 시작하여 컬러 보정, 화이트밸런스 보정, 렌즈쉐이드 보정 순으로 진행하면 이미지의 품질을 최적화할 수 있습니다.
카메라 화질튜닝의 최종 결과물을 얻으려면 앞에서 언급한 4가지를 어떻게 최적화하느냐에 따라 달라집니다. 최적화 방법은 카메라의 종류와 성능, 촬영 환경과 목적, 개인의 취향 등에 따라 다르므로 정답은 없습니다. 하지만 일반적으로 다음과 같은 원칙을 따르면 좋습니다.
딥 네트워크의 카메라 화질튜닝 솔루션 : 감마 값은 2.2 정도로 설정하면 대부분의 모니터에서 자연스럽게 보일 수 있습니다. 컬러 값은 RGB 채널별로 균형있게 조절하고, 색온도는 5000K~6500K 사이로 설정하면 중립적인 색감을 얻을 수 있습니다. 화이트밸런스 값은 촬영된 장면의 주광원에 맞추어 조절하면 자연스러운 색상 균형을 얻을 수 있습니다. 렌즈쉐이드 값은 이미지의 가장자리 부분의 밝기가 중앙 부분과 비슷하게 조절하면 균일한 밝기 균형을 얻을 수 있습니다.
카메라 화질 튜닝이란 카메라로 촬영한 영상의 화질을 개선하는 과정입니다. 카메라 화질 튜닝에는 다양한 알고리즘들이 사용됩니다. 예를 들어, 광원의 색온도 측정은 영상의 색상을 균일하고 자연스럽게 만들기 위해 광원의 색온도를 측정하고 보정하는 알고리즘입니다. 광원의 색온도는 영상의 화이트 밸런스에 영향을 줍니다. 감마 보정은 영상의 명암 대비를 조절하기 위해 감마 곡선을 적용하는 알고리즘입니다. 감마 보정은 영상의 밝기와 선명도에 영향을 줍니다. 컬러 보정은 영상의 색상을 조절하기 위해 컬러 매트릭스나 컬러 룩업 테이블을 사용하는 알고리즘입니다. 컬러 보정은 영상의 색감과 분위기에 영향을 줍니다. 화이트밸런싱 보정은 영상의 색온도를 조절하기 위해 화이트 밸런스 게인을 사용하는 알고리즘입니다. 화이트밸런싱 보정은 영상의 색온도와 색조에 영향을 줍니다. 노출시간 제어는 영상의 밝기를 조절하기 위해 노출시간을 제어하는 알고리즘입니다. 노출시간 제어는 영상의 밝기와 잡음에 영향을 줍니다. 렌즈 쉐이딩 보정은 렌즈로 인해 발생하는 영상의 밝기와 색상의 변화를 보정하는 알고리즘입니다. 렌즈 쉐이딩 보정은 영상의 균일성과 왜곡에 영향을 줍니다.
제가 운영하는 딥 네트워크는 카메라 화질튜닝 전문 기업으로서, 저희는 다음과 같은 기술들의 대표적인 화질튜닝 설계 알고리즘을 보유하고 있습니다.
화이트밸런스 제어 기술
촬영 장면의 색온도에 따라 색상을 균형있게 조절합니다. 자연스러운 색감을 재현하고, 색상의 변화에 민감하게 반응합니다. 이 기술의 핵심은 색온도 센서를 통해 장면의 색온도를 측정하고, 적절한 화이트밸런스 알고리즘을 적용하여 영상의 RGB 값을 보정하는 것입니다.
해외특허나 논문에서 제시한 화이트밸런스 설계 제어 알고리즘 수식을 확보하고 있읍니다.
렌즈 쉐이드 보정 기술
렌즈의 왜곡이나 결함으로 인한 영상의 불균형을 보정합니다. 깔끔하고 고르게 조명된 영상을 얻고, 영상의 품질을 향상시킵니다. 이 기술의 핵심은 렌즈의 광학적 특성을 분석하고, 영상의 각 픽셀에 대해 렌즈 쉐이드 보정 테이블을 참조하여 영상의 밝기와 색상을 보정하는 것입니다.
해외특허나 논문에서 제시한렌즈 쉐이드 보정 기술 설계 알고리즘 제어 수식을 확보하고 있읍니다.
감마 보정 기술
영상의 명암비를 인간의 눈에 맞게 조절합니다. 세부적인 표현력과 대비감을 높이고, 영상의 밝기와 명도를 최적화합니다. 이 기술의 핵심은 영상의 감마 값을 설정하고, 감마 보정 테이블을 생성하여 영상의 각 픽셀에 대해 감마 보정 값을 적용하는 것입니다.
해외특허나 논문에서 제시한감마 보정 기술설계 알고리즘제어 수식을 확보하고 있읍니다.
노출시간 제어 기술
영상의 밝기를 조절합니다. 너무 밝거나 어두운 장면을 적절하게 촬영하고, 영상의 선명도와 잡음을 줄입니다. 이 기술의 핵심은 영상의 평균 밝기를 측정하고, 노출시간 제어 알고리즘을 적용하여 카메라 센서가 받는 빛의 양을 조절하는 것입니다.
노출시간 제어 기술설계 알고리즘 파악에 성공해서 구현 가능 합니다.
줌 렌즈 제어 기술
당신의 카메라는 단순히 확대와 축소만 하는 줌 렌즈가 아닙니다. 우리의 카메라 줌 제어 기술은 영상의 공간적 축소방법을 이용하여 콘트라스트 향상을 위한 누적 분포함수의 계산량을 감소시키고 하드웨어의 복잡성을 줄입니다. 또한 각 픽셀의 콘트라스트를 비교하여 가장 큰 값을 선택하고 이에 맞춰 줌 렌즈를 제어하여 선명한 화면을 얻습니다. 우리의 카메라 줌 제어 기업은 영상의 콘트라스트 향상과 선명도 향상을 동시에 실현하는 차별화된 알고리즘을 보유하고 있습니다. 멀리서도 선명하게 당신의 순간을 담아보세요
줌 렌즈 제어 기술알고리즘 구현 노하우를 보유하고 있읍니다 ...
이미지센서(카메라 보드) 펌웨어의 프로토타입 개발기간 이후 양산대응을 위한 안정화 개발기간이 필요합니다 ...
이미지센서(카메라 보드) 펌웨어의 프로토타입 개발에 필요한 상세 개발규격을 메일로 전달 부탁드립니다 ...
저희는 이러한 기술들을 통합하여 최고의 카메라 화질튜닝 솔루션을 제공하고 있습니다. 저희와 함께라면 더욱 선명하고 생동감 있는 카메라 화질을 경험하실 수 있습니다.
자동차 라이다 시스템의 전체 설계 구조를 이해하는데 성공했읍니다 ... VICSEL 레이져 빔 부는 어떻게 구현하는지 ... 광학렌즈부는 또 어떻게 설계하는지 ... SPAD 이미지 센서부는 또 어떻게 설계해야 자율주행차에서 라이다로 3 차원으로 물체 인식이 가능한지를 이해하는데 성공했읍니다 ... 하 아 ~~~ 이거 실마리 푸는데 한 2 년 걸린것 같읍니다 ... 속 이다 시원하네요 ... 왼벽한 설계 안은 아니어도 85 % 이상 설계 안의 돈이 되는 근거자료 정보를 확실하게 파악했읍니다 ...
최근에 제가 시간투자를 한 1 년 이상해서 돈이 되는 기술정보를 파악한 분야가 자동차 라이다 설계 분야 입니다 ...
자동차 라이다 설계 분야는 그 기술이 크게 Vicsel 송신부 설계분야, SPAD Image Sensor 수신부 설계분야, 광학렌즈 설계분야 이렇게 크게 세가지 분야의 기술을 확보해야 그 상용화가 가능 합니다 ...
그동안 라이다 설계 분석을 위해 한 7 - 8 달 동안 국내외 특허분석을 진행했읍니다 ...
한 1 년 특허 분석을 하다 보니 위에서 말씀드린 크게 세가지 분야의 기술을 약 85 % 정도 확보하는데 성공했읍니다 ...
더 자세한 분석 내용을 소개드리고 싶지만 해외 기업들의 특허를 어떻게 피해 나가 구현을 할지 까지는 아니어도 한 7 - 8 달 해외 기업들의 특허 분석을 통해 해외 기업의 라이다 설계 기법을 파악하는데는 성공했읍니다 ...
1. 자동차 라이다 설계 상용화 개발도 Vicsel 을 설계해서 제조하는 반도체 기업과도 협력이 필요하고
2. SPAD 이미지센서부도 설계해서 제조하는 반도체 기업과도 협력이 필요 합니다 ...
3. 또한 광학렌즈부도 설계 및 제작하는 전문기업과의 협력이 필요 합니다 ...
저는 자율주행차 라이다 장치 HW 설계 부터 SW 설계까지 그 세부 설계안을 어떻게 구현해야 하는지를 국내외 라이다 특허분석을 통해 터득 했읍니다 ... 당신은 프로토타입도 없는데 당신 기술은 무었으로 입증 가능하냐라고 질문하신다면 국내외 특허 수십개의 세부 분석을 통해서 라이다의 세부 설계 구현 안을 속속들이 파악할수 있었읍니다 ... 라이다 설계 및 구현 기술을 확실하게 파악 성공했는데 제가 자금력도 부족하고 또 이런류의 사업화는 서로 협력하면서 진행해야 가능할것 같읍니다 ... 라이다 설계 노하우중 가장 중요한 부분이 자동차 라이다 장치가 HW 설계가 어떤 구조로 설계가 되야 동작 가능한지와 HW 설계 방안이 확립됬다면 어떻게 SW 를 설계할것인가 입니다 ... 저는 HW 설계 방안도 확실히 파악하고 있고 이 HW 설계 방안 파악이슈의 해결이 안되면 아무것도 진행이 불가능 합니다 ..... 라이다 개발이 기술력만 있다고 다 되는것이 아니라는것을 알기에 제가 운영하는 딥 네트워크와 뜻을 같이해서 공동으로 개발하실 기업 관계자분의 연락을 기다리겠읍니다 ....
최근에 제가 시간투자를 한 1 년 이상해서 돈이 되는 기술정보를 파악한 분야가 자동차 라이다 설계 분야 입니다 ...
자동차 라이다 설계 분야는 그 기술이 크게 Vicsel 송신부 설계분야, SPAD Image Sensor 수신부 설계분야, 광학렌즈 설계분야
이렇게 크게 세가지 분야의 기술을 확보해야 그 상용화가 가능 합니다 ...
그동안 라이다 설계 분석을 위해 한 7 - 8 달 동안 국내외 특허분석을 진행했읍니다 ...
한 1 년 특허 분석을 하다 보니 위에서 말씀드린 크게 세가지 분야의 기술을 약 85 % 정도 확보하는데 성공했읍니다 ...
더 자세한 분석 내용을 소개드리고 싶지만 해외 기업들의 특허를 어떻게 피해 나가 구현을 할지 까지는 아니어도
한 7 - 8 달 해외 기업들의 특허 분석을 통해 해외 기업의 라이다 설계 기법을 파악하는데는 성공했읍니다 ...
라이다 개발관련 국내에서는 현대차 사내벤쳐 혹은 해외에도 알려진 국내 스타트업 등등이 자동차 라이다 개발을 하고 있읍니다 ...
대기업 전략투자팀은 대기업 경력이 있는 포트폴리오를 가진 인력을 선호하시는것을 잘 알고 있지만 ...
저 또한 국내외 라이다 기업의 설계관련 특허 분석 즉 제가 구현 가능할 만큼의 돈이 되는 정보 파악에 성공했기에
그동안 2 년 가까이 BLDC/PMSM 모터제어로 전류를 정밀하게 제어하는 방법을 찾으려고 관련 논문을 수백편 뒤져서 최근에 모터의 정밀 전류제어 구현 기법을 99 % 터득에 성공했다 ...
저는 그동안 모터제어만 판것은 아니고 카메라 이미지센서의 화질 보정 알고리즘을 터득하려고 논문과 특허를 수도 없이 뒤져서 결국 터득에 성공했다 ...
밥벌이를 하려고 이것만 한것은 아니다 ...
딥러닝 NeRF 논문과 StyleGAN 논문의 핵심 딥러닝 모델 설계 구조를 파악하느라 고생 좀 했다 ...
또한 구글 Transformer Model 기반으로 음성인식 구현을 위한 딥러닝 모델 세부 설계구조 분석도 결코 쉽지 않았다 ...
이것으로 밥벌이를 하려 99% 준비해 놨는데 경기가 죽어서 일꺼리 얻기가 하늘에 별따기라 너무 힘들다 ...
이렇게 힘들어도 나는 자신있다 왜냐하면 위에서 언급한 99 점 짜리 기술이 몇가지가 있으니 언젠가 반드시 기회가 오리라 나는 확신하기 때문이다 ...
Kaldi 음성인식 자동 얼라인 도구가 죤스 홉킨스 대학에서 발표한지 꽤 오랜시간이 지났구요 ...Kaldi 음성인식 자동 얼라인 도구가 HMM-GMM 딥러닝 모델로 만든음성인식 자동 얼라인 도구 이구요 ...Kaldi 음성인식 자동 얼라인 도구는음성인식 자동 얼라인출력을 얻기 위해서는 파라미터 셋팅도 간단치는 않은것 같고,그리고 이 KALDI 도구는 음성인식 에러율이 약 12 % 정도더 군요 ...Kaldi 음성인식 자동 얼라인 도구의 HMM-GMM 딥러닝 모델의 경우 혼합 가우시안 구조라서 음성데이터로 HMM-GMM 딥러닝 모델을 학습을 시킬때 정규분포를 하나를 적용해서 학습시키는 구조가 아니고정규분포가 굉장히 여러개의 분포를 혼합해서 HMM-GMM 딥러닝 모델을 학습시키는 구조인것 같읍니다 ...그래서 에러율 12 % 를 얻기 위해 HMM-GMM 딥러닝 모델 학습은 시간이 걸려야 원하는 결과 도출이 가능한것 같읍니다 ... 음성 자동 얼라인 HMM-GMM 딥러닝 모델이 나온 이후 나온 딥러닝 모델인 CTC 모델에 저는 관심이 더 갔구요 이 CTC 모델의 경우 디코딩 언어모델 처리구조중 하나인 빔 서치 알고리즘 최적화 설계를 처리했을 경우 에러율이 약 8 % 정도나오는것 같더라구요 ... 딥러닝 모델인 CTC 모델로 디코딩 언어모델 처리구조까지 적용했을때가 에러율이 약 8 % 정도인데 ... 이를 개선하기 위한 방법으로 JOINT CTC-ATTENTION 모델을 적용하면 에러율이 약 5 % 내외로 나오는것으로 파악됩니다 ...구글이 발표한 딥러닝 언어모델인 Transformer 모델의 경우도 에러율이 약 5 % 내외로 나오는것으로 파악됩니다 ...
저는 여기까지 말씀드린 음성인식 모델의 세부 설계구조를 파악하는데 성공했구요 요근래 나온 딥러닝 음성인식 모델인 Representation 학습모델의 경우도 에러율이 약 5 % 내외로 나오는것으로 파악됩니다 ...
저의 경우 위에서 설명드린 딥러닝 음성인식 해외 글로벌 대기업의 논문의 세부 동작 구조도 이해하고 있고 Transfomer 모델의 딥러닝 소스도한줄한줄 동작 처리 방법도 이해하고 있읍니다 ... 저는 89년에 전자공학 석사학위를 받았고, 그 후 대기업 연구소도 7 년 재직 경험이 있고, 지금까지 IT 분야로 30 년의 경험이 있읍니다 ...그동안 30 년의 IT 분야 경험을 하면서 2007 년 부터 약 2 년간 H.264 Video Decoder SW IP 개발로 사업을 했었는데 ... 결과물의 정밀도가 2 % 부족해서 30 평대 아파트 한채 날린것도 이때 입니다 ... 그 이후 SW 개발용역 일을 약 10 년간 진행을 했었는데 ... 이 기간동안 업체로부터 기술이슈 문의를 약 200 건 정도를 정밀하게 검토할수 있는기회가 있었구요 ..... 대학원에서 문제해결 방법을 배웠구요 ... 그 후 제가 딥러닝 음성인식 구현관련실무적으로 경험은 없지만, 위에서 말씀드린바와 같이 딥러닝 음성인식 구현을 어떤 설계 구조와 방법으로 결과를 내는것이 가능하다는 것은 그동안 10 여년 기간 동안의 수백번의 시행착오를 겪으면서 터득한 독자적인 문제해결 능력이 있기에 딥러닝 음성인식으로 직접 실무적 경험이 없어도 자신있게 딥러닝 음성인식 노하우를 확보하고 있다고 말씀드리는것이 가능한 이유 입니다 ... 저의 경우딥러닝 모델인 CTC 모델로디코딩 언어모델 처리구조까지 적용했을때가에러율이 약 8 % 정도 구현 가능한 노하우를 보유하고 있읍니다 ... 여기에다 자세하게 모든것을 다 적지 못하는것 이해해 주시구요 ... 에러율이 약 8 % 정도 노하우를 얻기 위해 논문분석을 2 년을 빡시게 해서 얻은 값진 노력의 결과물이라고 말씀드릴수 있읍니다 ... 저도 가능하다고 제시한 음성인식 정확도(에러율)는 특정 음성 데이터셋에서 가능한 성능(에러율) 입니다 ... 제 딥러닝 고군분투기를 위에 적었구요 제가 100 % 완벽하지는 못 하지만 딥러닝 음성인식 에러율 8 % 의 구현 기술력을 세부적으로 터득하고 있읍니다 ...
저는 딥러닝 음성인식 독자적인 사업화에 관심이 많은데 ... 저에게 인큐베이팅 투자가 가능하신 투자사 혹은 대기업 관계자분께서 연락주시면 감사하겠읍니다 ...
제가 운영하는 일인기업 딥 네트워크 장석원
제가 어떤것들을 그동안 검토분석을 했는지를 소개하는 저의 일인기업 기업블로그 사이트 입니다 ...
제가 사업화를 준비했던 기술들 몇가지에 대해 사업화 준비 내용을 소개하는 기업블로그 입니다 ...
엔비디아 NeRF 논문의 세부 설계 구조를 살핀지 한 1 년되 갑니다 ... MLP 로 얻은 RGB와 density 데이터들을 2D 이미지에 축적하여 새로운 관점에서 객체를 바라봤을 때 scene 설계 노하우를 파악하는데 한 1 년 걸린것 같읍니다 ... Hierarchical volume sampling 부분의 설계 노하우를 이해하는것이 정말 힘들었읍니다 ... NeRF 논문의 저자는 원래 camera ray 에서 N 개의 포인트를 임의로 뽑은 후 렌더링에 사용하려고 했는데 이렇게 하니 비효율적이라는 것을 알았구요 ... 왜냐하면 camera ray가 통과하는 공간은 객체뿐만 아니라 아무것도 없는 공간도 포함되어 있기 때문이었죠. 별 도움이 안되는 것들도 렌더링에 사용하니 좋은 결과가 나오기 힘들었던 것입니다. 그래서 생각해낸게 마지막 렌더링에서 예측되는 효과에 비례해 포인트를 sampling하는 방식인 Hierarchical volume sampling 이었습니다. 이렇게 하면 효율적으로 렌더링에 사용할 좌표를 뽑을 수 있다고 합니다 ... 이것의 세부 설계 노하우 파악이 NeRF 논문의 실제 구현시 거의 핵심적인것을 처리한다고 저는 파악 합니다 ... 렌더링에서 예측되는 효과에 비례하는 포인트를 sampling 설계 방법의 파악이 NeRF 논문의 핵심이라고 저는 판단합니다 ... Classical Volume Rendering Techniques 을 이용해 MLP 로 얻은 RGB와 Density 데이터들을 2D 이미지에 축적하여 새로운 관점에서 객체를 바라봤을 때 scene을 어떻게 가장 효과적인 설계 방안을 찾는가가 NeRF 논문의 핵심 입니다 ... 저는 Hierarchical volume sampling 세부 설계 구조를 파악하는데 성공했읍니다 ... NeRF 논문을 잘 적용하면 가상인간을 구현시에도 적절히 응용이 가능하므로 다양하게 응용분야가 있을것 같읍니다 ...
NeRF 논문의 구현 기술 파악에 성공했읍니다 ... 아시겠지만 NeRF 구현기술이 간단하지는 않읍니다 ... 저도 이것 파악하는데 7 - 8 달 걸린것 같읍니다 ... 2 D 이미지들로부터 어떻게 3D Scene 을 얻을수 있는지 그 설계 노하우 파악이 쉽지 않았지만 파악에 성공했읍니다 ....
관련해서 이 건 관련 협력을 원하시는 업체와 상세 기술협의(기술컨설팅) 진행도 가능 합니다 ...
제가 운영하는 일인기업 딥 네트워크 장석원
제가 어떤것들을 그동안 검토분석을 했는지를 소개하는 저의 일인기업 기업블로그 사이트 입니다 ...
제가 사업화를 준비했던 기술들 몇가지에 대해 사업화 준비 내용을 소개하는 기업블로그 입니다 ...
구글 Transformer Model 논문의 핵심인 Attention 처리기법 의 설계 구조 파악에 성공했읍니다 ...
예를들어 GPT-3 같은 언어모델에서 구글 Transformer Model 의 Attention 처리기법을 어떤 방식으로 적용하는지를 파악 성공했읍니다
구글 Transformer Model 의 인코딩 부와 디코딩 부의 상호동작이 어떻게 처리되서 번역 모델 처리시 Attention 처리기법으로 어떤 식으로 언어 번역 처리가 되는가의 동작 메커니즘 즉 그 설계 구조 파악에 성공 했읍니다 ....
구글 Transformer Model 기술의 근원이 되는 핵심 원리를 파악하기 쉽지 않은데 이런것을 도와드릴수 있을것 같읍니다 ....
구글 Transformer Model 로 한영 번역을 구현한다고 했을때 학습데이터가 몇만개 몇십만개 수준이 아니고 수천억개 아니 그 이상의 학습데이터로 딥러닝 모델을 학습시켜야 하는데 대기업에서는 이런 초거대 언어모델을 상용화시 어떤 문제에 직면하고 있는지를 파악하는게 가장 핵심 입니다 ... 저는 이런것을 파악하기 위해 하루에 한 2 시간 정도씩 구글링을 무려 2 년 가까이 해서 그 핵심을 터득했읍니다 ... 이런 초거대 모델을 상용화하려면 슈퍼컴퓨터가 필요하다고 애기를 하지요 ... 이 말의 의미는 비용이 많이든다는 점 입니다 ... 구글 Transformer Model 로 초거대 모델을 학습하는것이 저같이 논문분석만 한 사람은 개발시 어떤 문제가 발생하고 그 문제의 해결방안이 뭔지 파악이 불가능하다라는 분들이 많읍니다 ... 개발시 어떤 문제가 발생하고 그 문제의 해결방안이 뭔지 파악이 가능하려면 구글 Transformer Model 의 설계 구조가 어떤지 그 세부 하나하나를 속속들이 살펴서 이해하는 작업이 반드시 필수 입니다 ... 제가 이런 작업이 어느 정도 성공했으니 이런 글도 쓰는것 이구요 ... 구글 Transformer Model 로 초거대 모델을 학습시키는것이 비용(최소 100 억 정도)이 상당한 그런 일 이거든요 ... 엔비디아 A100 GPU 를 탑재한 딥러닝 서버가 최소 몇십대 이상 준비가 필요하구요 ... 딥러닝 초거대 모델을 학습시킨다는 의미는 딥러닝 모델이 가지고 있는 뉴런들의 가중치(weight)을 조정한다는 의미이고, 우리는 모델 구성과 가중치만 저장만 해놓으면, 필요할 때 저장한 모델 구성과 가중치를 불러와서 사용하면 됩니다. 학습된 초거대 모델을 저장한다는 말은 딥러닝 모델 아키텍처와 모델 가중치를 저장한다는 말입니다.
수천억개 아니 그 이상의 학습데이터로 딥러닝 모델 학습 처리를 어떻게 경량화 시킬것인가 뭐 이런게 요즘 논문들의 이슈이고 이쪽 논문도 꽤 발표되고 있읍니다 ...
저는 구현 경험은 없고 논문분석을 통해 그 세부 설계 원리를 이해했고 이것을 관심있어 하시는 업체와 협의해 보고 싶읍니다 ...
관심 있으신 기업에서는 문의해 주시면 감사하겠읍니다 ...
저는 주로 세부 기술 컨설팅을 처리할수 있을것 같읍니다 ...
저는 83 학번이고 89년에 일반대학원 전자공학을 졸업했읍니다 ... 이것으로 관련한 사업화 추진을 하고 계신 업체와 협의해 보고 싶읍니다 ...
제가 운영하는 일인기업 딥 네트워크 장석원
제가 어떤것들을 그동안 검토분석을 했는지를 소개하는 저의 일인기업 기업블로그 사이트 입니다 ...
제가 사업화를 준비했던 기술들 몇가지에 대해 사업화 준비 내용을 소개하는 기업블로그 입니다 ...
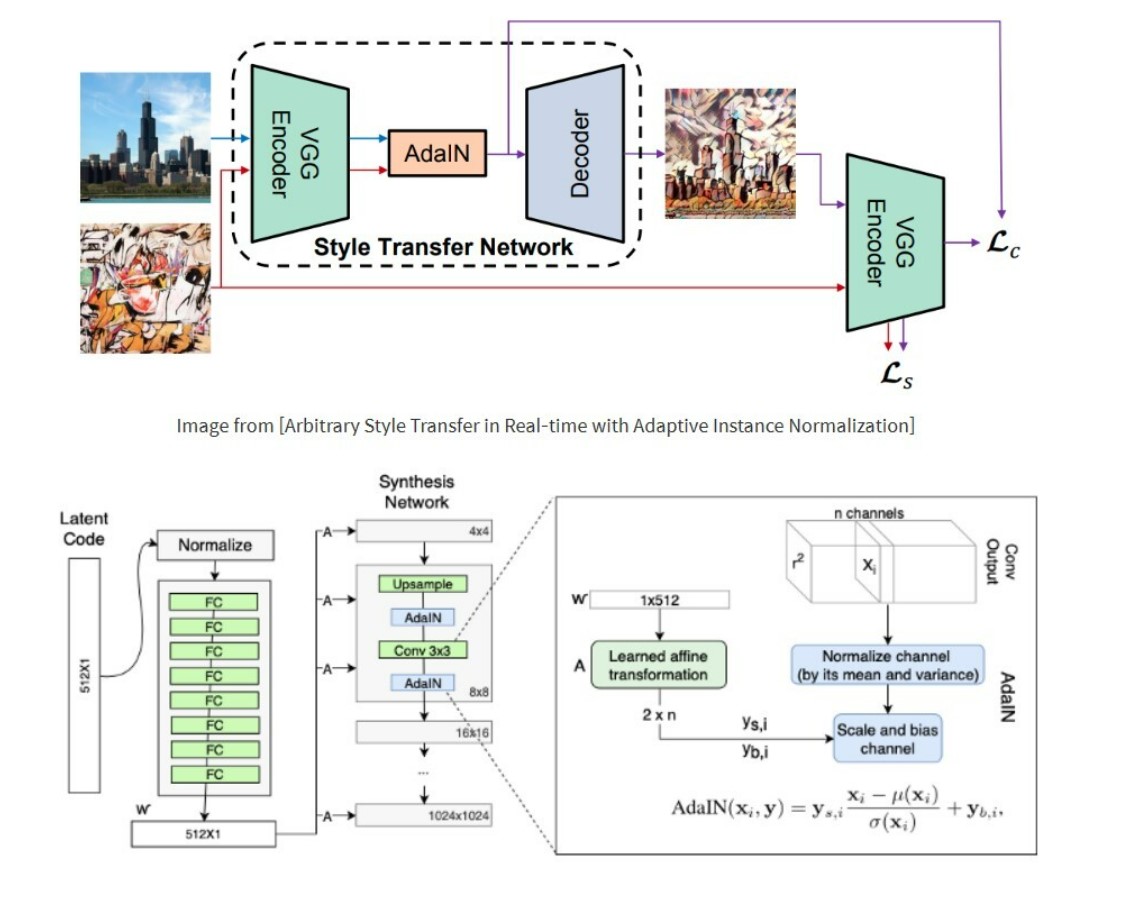
StyleGAN 논문의 핵심인 Style Transfer 의 설계 구조 파악에 성공했읍니다 ...
Style Transfer 의 핵심인 AdaIN 메커니즘의 블럭도를 아래에 표시했고 이것의 세부 동작원리 파악에 성공했읍니다
어떻게 Style Transfer 메커니즘이 동작해서 Style 을 전달 가능한지 그 설계 원리 파악에 성공했읍니다 ...
예를들어 전지현 얼굴에 미스코리아의 눈 코 입으로 사람이 느끼기에 불편하지 않게 Style Transfer 을 처리하려면 Style Transfer 의 핵심인 AdaIN 메커니즘의 그 설계 세부구조를 담당하는 알고리즘의 동작원리를 이해해야 합니다 ... 이게 쉽게 구현 가능할것 같아도 그렇치 않읍니다 ...
저의 경우, 위의 Style Transfer 를 적용한 딥러닝 모델인 StyleGAN 기법으로 가상인간 로지 같은것을 전지현 얼굴에 미스코리아의 눈 코 입으로 사람이 느끼기에 불편하지 않게 변환하는 사업화 안을 구체화 중 입니다 ...
Nvidia StyleGAN 기술의 근원이 되는 핵심 원리를 파악하기 쉽지 않은데 이런것을 도와드릴수 있을것 같읍니다 ....
저는 구현 경험은 없고 논문분석을 통해 그 세부 설계 원리를 이해했고 이것을 관심있어 하시는 업체와 협의해 보고 싶읍니다 ...
관심 있으신 기업에서는 문의해 주시면 감사하겠읍니다 ...
저는 주로 세부 기술 컨설팅을 처리할수 있을것 같읍니다 ...
저는 83 학번이고 89년에 일반대학원 전자공학을 졸업했읍니다 ... 이것으로 관련한 사업화 추진을 하고 계신 업체와 협의해 보고 싶읍니다 ...
제가 운영하는 일인기업 딥 네트워크 장석원
제가 어떤것들을 그동안 검토분석을 했는지를 소개하는 저의 일인기업 기업블로그 사이트 입니다 ...
제가 사업화를 준비했던 기술들 몇가지에 대해 사업화 준비 내용을 소개하는 기업블로그 입니다 ...
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
Transformers 를 medical image segmentation task 에 적용한 논문이고 ... Transformer 구조의 이점을 최대한 살리기 위해 global context 에 대한 정보만 추출한 것이 아니라 low-level CNN faeture 도 잘 활용해서 성능을 개선한 논문 입니다 ...
본 해외논문관련 딥러닝 모델 구현 노하우 확보에 성공했구요 ...
본 논문과 같은 의료영상분야 딥러닝 모델 사업화에 관심있으신 분들의 연락 기다립니다 ...
제가 운영하는 일인기업 딥 네트워크 장석원
제가 어떤것들을 그동안 검토분석을 했는지를 소개하는 저의 일인기업 기업블로그 사이트 입니다 ...
제가 사업화를 준비했던 기술들 몇가지에 대해 사업화 준비 내용을 소개하는 기업블로그 입니다 ...
그동안 2 년 가까이 BLDC/PMSM 모터제어로 전류를 정밀하게 제어하는 방법을 찾으려고 관련 논문을 수백편 뒤져서 최근에 모터의 정밀 전류제어 구현 기법을 99 % 터득에 성공했다 ...
저는 그동안 모터제어만 판것은 아니고 카메라 이미지센서의 화질 보정 알고리즘을 터득하려고 논문과 특허를 수도 없이 뒤져서 결국 터득에 성공했다 ...
밥벌이를 하려고 이것만 한것은 아니다 ...
딥러닝 NeRF 논문과 StyleGAN 논문의 핵심 딥러닝 모델 설계 구조를 파악하느라 고생 좀 했다 ...
또한 구글 Transformer Model 기반으로 음성인식 구현을 위한 딥러닝 모델 세부 설계구조 분석도 결코 쉽지 않았다 ...
이것으로 밥벌이를 하려 99% 준비해 놨는데 경기가 죽어서 일꺼리 얻기가 하늘에 별따기라 너무 힘들다 ...
이렇게 힘들어도 나는 자신있다 왜냐하면 위에서 언급한 99 점 짜리 기술이 몇가지가 있으니 언젠가 반드시 기회가 오리라 나는 확신하기 때문이다 ...
StyleGAN 기술의 ADaIN 설계기법을 이해하는것은 쉽지않다 ... 얼굴에서 눈 코 귀 입 피부 헤어 등의 스타일을 변경하는 기술이기 때문이다 ... Style Transfer의 경우, 내가 원하는 Contents를 담고 있는 이미지의 feature 에서, 이미지의 특정 스타일을 빼주고, 내가 입히고 싶은 특정 Style을 더해주는 방식으로 수행된다. 이 기법은 딥러닝의 여러분야에서 반드시 필요한 기술이다 ...
바로 위에 소개된 해외논문의 결과물이 딥러닝 모델의 메커니즘 동작 과정을 설명한다 ... 위의 논문의 결과물이 어떤 알고리즘 구조로 설계되었길래 위와 같은 결과를 얻을수 있는지를 세부분석에 성공했다 ... 관련해서 문의주시면 기술컨설팅 가능 합니다 ....
제가 운영하는 일인기업 딥 네트워크 장석원
제가 어떤것들을 그동안 검토분석을 했는지를 소개하는 저의 일인기업 기업블로그 사이트 입니다 ...
제가 사업화를 준비했던 기술들 몇가지에 대해 사업화 준비 내용을 소개하는 기업블로그 입니다 ...
[ 네트워크 통신 분야 펌웨어 및 BLDC Motor 제어분야 펌웨어 개발 및 컨설팅 전문 ] BLDC Motor 전류제어 / PI 제어 / 속도제어 개발 및 자문 가능 합니다 ... 임베디드 펌웨어 개발 30 년차 입니다.. - https://videocodec.tistory.com/m/2284
네트워크 장비인 L3 스위치 장비의 설계 원리를 현재 정확히 이해하고 있다 ... 이 정도 파악하는 수준이면 네트워크 SW 설계도 거의 전문가급이라고 나는 판단한다 ... 네트워크 장비인 L3 스위치 장비 개발을 직접 경험해 보지 않았어도 L3 스위치 장비의 구현 원리를 파악할수 있었다 ... 나는 네트워크 장비인 L3 스위치 장비의 네트웍 프로토콜 스택 설계 전문가가 아니라 L3 스위치 장비를 응용해서 네트웍 SW 를 설계하는 전문가라함이 정확할것 같다 ...
방탄소년단 공연 실황을 해외에 방송 서비스로 중계방송을 한다고 하면 네트워크 장비인 L3 스위치 장비의 세부 설계 구조를 이해하지 못하면 대규모 방송 서비스를 설계하는것이 사실상 어렵기 때문 입니다 ...
WebRTC 미디어 서버 소스로 공개된것중에 유럽의 이탈리아 개발자들의 Meetecho 사에서 공개한 오픈소스 소스인 Janus Gateway Github 소스를 다운로드 받아 살펴 보기 시작했읍니다 ... Meetecho 사에서 공개한 오픈소스 소스인 Janus Gateway Github 소스는 여러개의 오픈소스 라이브러리를 적용해서 어플리케이션 서버와 웹 서버간의 각종 Configuration 데이타 수백개의 설정 및 셋팅 부분을오픈소스 라이브러리로 구현한것이 소스의 대부분이다 ... Janus Gateway 의 송수신 데이터의 보안처리 또한 OpenSSL 같은오픈소스 라이브러리로 구현한것이다 ... 어플리케이션 서버와 웹 서버간의 각종 Configuration 데이타 수백개의 설정 및 셋팅 부분도 오픈소스 라이브러리를 적용해서 웹 전송 포멧인 JSON 형태 데이터Configuration전달 구현을 처리하고 있다 ... Janus Gateway Github 소스에서 미디어 데이터 송수신은 임베디드 웹 서버를 적용해서 REST API 로 HTTP 1.1 규격으로 전송하기 위한 부분도 오픈소스 라이브러리로 구현 참조소스를 제공한다 ... 이런 부분들의 분석이 어느정도되 있고 이것의 커스토마이징은 또 다른 문제일것 같다 ... Janus Gateway Github 소스는 대용량 미디어 서비스를 설계하기 위한 참조소스도 제공한다. RabbitMQ 클라우드의 API 를 적용해서 화상회의 참여자가 수백명 정도 일때 정도의 규모로 미디어 서비스하는것의 참조소스를 제공하는데 다 친절하게 제공하지는 않고 공부가 필요하다 ... 화상회의 참여자가 수백명 정도 일때, Janus Gateway 에서는웹으로 방송을 송출시 수신을 원하는 사람에제만 방송을 송출하기 위해 Publish / Subscribe 구조로 처리하고 있고, 수백명 혹은 수만명 혹은 수십만명에게 미디어 방송 서비스를 구현시 Publish / Subscribe 구조로 설계하는것이 일반적이고, 저는