분류 전체보기
- [1000 만원에 세부 구현 가능 기술자료 협의후 제공가능] PMSM Motor 의 FOC 제어 구현 알고리즘 세부 수식을 확보하고 있읍니다 ... 2024.07.13 1
- [저전력 로라통신 개발 및 자문 전문][AES-128 암호화 및 AES-CMAC 알고리즘 구현 원리 파악 성공] 로라통신에 적용되는 암호화 알고리즘 설계 기술을 확보 성공했읍니다 ... 2024.07.07
- [위상배열안테나 Beamforming 제어 개발 및 기술자문 전문] 저희 딥네트워크는 위상배열안테나 어레이와 Phase Shifter 를 적용해 정밀한 Beamforming 제어가 가능한 노하우를 보유하고 있읍니다 ... 2024.06.28
- [X 밴드대역 위성 데이터 송수신 기술이전 가능] 딥네트워크 장석원 입니다 ... 2024.06.28
- 제가 운영하는 일인기업 딥네트워크는 AESA Radar 의 위상배열안테나 어레이를 적용해 Beamforming 기술 펌웨어 구현 노하우를 98 % 보유하고 있읍니다 ... 2024.06.22
- 기술전문 일인기업 딥네트워크를 운영중인데 대기업이나 중견기업에 저의 LLM(거대언어모델) 이나 로봇 제어 관련해서 저의 기술력 소개 제안서 넣을때 제일 어려운 점(고민 사항) 말씀드려 봅니다 ... 2024.06.20
- [CAN 통신 개발 및 자문 전문][일인기업 딥네트워크] CAN 통신 동작원리 및 세부 펌웨어 구조 분석 ... 2024.06.18
- LLM 분석 및 개발 자문 일인기업 딥네트워크가 GPT-3.5 모델 설계 구조를 어디까지 어떻게 파악 성공했을까 ? 아래의 이메일 주소로 많은 LLM 개발 및 자문 문의 부탁드립니다 ... 2024.05.30
- [ 장거리 저전력 로라 통신 분야 LoRA Device 단 / LoRa Gateway 단 펌웨어 개발 및 컨설팅 전문 ][로라 통신 Uplink Packet / Downlink Packet 을 암호키로 암복호화 해서 송수신하는 노하우 확보 성공] 2024.05.27 3
- [LLM(거대 언어 모델) 딥러닝 개발 및 자문 전문 일인기업 딥네트워크][이 글을 살펴 보시고 저에게 딥러닝 개발 및 자문 일꺼리를 혹시라도 맡기실 기업이 있으시면 연락 주십시요 ....] 2024.05.15 2
- [일인기업 딥네트워크 딥러닝 LLM 구현 기술력 소개][구글 트랜스포머 LLM 모델 구현 개발 과 텐서플로우 개발환경 구축] 2024.05.15
- Whether it’s Korean or American corporations, securing massive funds like Middle Eastern oil money is indeed everything for being number one in AI. 2024.05.11
- 한국 대기업 이든 미국 대기업 이든 AI 1 등을 위해 반드시 필요한게 중동의 오일 머니 같이 초대규모 자금확보가 사실 AI 세계 1 등의 모든것 이라고 해도 틀린 말이 아닙니다 .. 2024.05.11
- 물론 대기업 AI 연구소에서는 GPT-3.0 모델이 2020년 중반쯤 논문이 발표되면서 GPT-3.0 모델의 위력이 어느정도 라는것을 이미 알 사람은 다 알고 있었다 ... 2024.05.03
- [일인기업 딥네트워크의 SAR 위성 합성개구 레이더의 스펙클 노이즈 감쇄 알고리즘 구현 노하우 확보 성공] 2024.04.28 2
- DeepNetwork :: Synthetic Aperture Radar (SAR) Doppler Effect Operation Principle Analysis Specialist Company DeepNetwork 2024.04.08
- I am Seok-won Jang , the head of DeepNetwork, a sole proprietorship that has achieved some degree of success in securing detailed implementation strategies in the TensorFlow environment based on the detailed analysis of the structure design of the LLM. 2024.04.07
- The implementation of the lightweighting of deep learning LLM is burdensome for a small business like me to do everything alone, so I am looking for a partner to co-work with, but I have not yet received any contact. 2024.04.05
- I have finally succeeded in understanding the theory of Kalman filters, which are applied in missile attitude control or robot attitude control. 2024.04.03
- [Expert in Optical Character Recognition Solution Issue Analysis and Technical Consulting] The one-person company DeepNetwork that I operate can provide detailed technical consulting based on the analysis of optical character recognition issues… 2024.03.30
- The importance of reviewing and analyzing the key issues in building a TensorFlow environment on Linux that supports GPU with Docker for the one-person enterprise, DeepNetwork. 2024.03.29
- [일인기업 딥네트워크 칼만필터 기술력 소개][방산 대기업의 기술분야인 레이더/미사일 제어의 핵심인 9 축센서를 사용해 그 어렵다는 칼만필터 구현을 어떻게 노력해 성취했는가 ?] 2024.03.29 4
- One-Person Enterprise DeepNetwork: Pioneering AI Solutions with Proximal Policy Optimization and Reinforcement Learning with Human Feedback 2024.03.26
- As I began to understand the detailed implementation of the Transformer Model using the TensorFlow API, I realized that it was also very important to solve the question of how the GPU Cloud Server Infrastructure is designed… 2024.03.25
- [일인기업 딥네트워크 탱크의 수위 측정 (액체 수준(수위)을 측정) 개발 전문][ToF 원리를 사용하여 탱크의 액체 수준을 측정하는 시스템을 설계하고 구현] 2024.03.24
- Hello, I am the representative of Deepnetwork, a one-person company specializing in electric vehicle battery charging control. 2024.03.22
- “Do you know that a one-person enterprise like me, specializing in the analysis of the detailed algorithm design structure of large language models, can also have expertise related to LLM?” 2024.03.22
- [Introduction to the Know-how of Handling Key Issues in Detail] When implementing LLM (Large Language Model) with Google Transformer Model in TensorFlow environment… 2024.03.15
- [초거대 모델 기술자문 전문] LLM(거대언어모델) 을 구글 트랜스포머 모델로 구현시 텐서플로우 환경에서 세부 핵심이슈 처리 노하우 소개 ... 2024.03.15
- The implementation of NVLink-C2C’s 900GB/s bandwidth should also be based on the time required for the NVIDIA Grace Hopper Superchip to read 96GB of HBM3 memory and write it to GH200’s 141GB of HBM3e memory, shouldn’t it? 2024.03.14
[1000 만원에 세부 구현 가능 기술자료 협의후 제공가능] PMSM Motor 의 FOC 제어 구현 알고리즘 세부 수식을 확보하고 있읍니다 ...
2024. 7. 13. 05:28
PMSM Motor의 FOC 제어 세부 구현 노하우 제공
5. RDC : AD2S1210WDSTZRL7 와
제가 PMSM 모터 FOC 정밀 제어 구현을 위해 논문이나 기술자료 검토 분석한지 한 3 년 됩니다 이것 구현의 목표를 로봇 축 관절제어를 정밀하게 하려면 FOC 제어시 어떤 방식으로 어떻게 처리해야 하는지 논문 등등을 검토한지 한 2 년만에 정밀 모터제어 세부 튜닝 노하우를 실제 구현에 적용 가능하게 확실히 분석에 성공해서 뿌듯합니다
[저전력 로라통신 개발 및 자문 전문][AES-128 암호화 및 AES-CMAC 알고리즘 구현 원리 파악 성공] 로라통신에 적용되는 암호화 알고리즘 설계 기술을 확보 성공했읍니다 ...
2024. 7. 7. 10:10
[AES-128 암호화 및 AES-CMAC 알고리즘 구현 원리 파악 성공]
개인사업자로 IT 분야 펌웨어 개발 등 개발용역 사업을 한지 약 10 년 입니다 ...
로라통신 디바이스단 / 게이트웨이단 프로토타입 펌웨어 개발 Semtech SX1276 으로 가능 합니다 ... 귀사 요구에 맞춰 최대한 시간을 맞춰서 프로토타입 개발 진행이 가능 합니다 ... Semtech 회사 사이트에서 SX1276 에서 다운로드 받은 펌웨어 세부 분석이 되있어서 최대한 빠른 기간내 펌웨어 개발 진행이 가능 합니다 ... 저는 지역이 수원 이고 맡겨 주시면 확실하게 결과물 내는것이 가능합니다 ...
LoRA (Long Range)는 저전력 광역 네트워크 (LPWAN) 기술로, 장거리 통신과 저전력 소비를 가능하게 하는 무선통신 방식입니다. LoRA 시스템은 크게 네 부분으로 나뉩니다: 디바이스단, 게이트웨이단, 네트웍 서버단, 그리고 어플리케이션 서버단. 각 부분의 구현 기술에 대해 상세히 설명드리겠습니다.
디바이스단 (End Device): 디바이스단은 데이터를 수집하고 LoRA 네트워크에 전송하는 IoT 장치입니다. 이들은 주로 센서나 액추에이터로 구성되며, LoRA 모듈을 통해 무선 신호를 전송합니다. 디바이스단의 핵심 기술은 Chirp Spread Spectrum (CSS) 변조 방식을 사용하여 장애물이 많은 환경이나 장거리에서도 간섭을 최소화하면서 데이터를 전송하는 것입니다.
게이트웨이단 (Gateway): 게이트웨이는 디바이스단으로부터 신호를 수신하여 인터넷을 통해 네트웍 서버로 전달하는 역할을 합니다. 게이트웨이는 별 모양의 토폴로지를 형성하여 중앙 네트워크 서버와 백엔드의 최종 장치 간 메시지를 릴레이합니다. 게이트웨이는 일반적인 IP 연결을 사용하여 네트워크 서버에 연결되며, 다수의 디바이스단과 통신할 수 있습니다.
네트워크 서버단 (Network Server): 네트워크 서버는 게이트웨이로부터 받은 데이터를 처리하고, 필요에 따라 디바이스단에 명령을 전송합니다. 또한, 네트워크의 보안과 데이터 라우팅을 관리합니다. 네트워크 서버는 Adaptive Data Rate (ADR) 알고리즘을 통해 연결된 각 센서의 데이터 속도를 관리하여 최적화합니다.
어플리케이션 서버단 (Application Server): 어플리케이션 서버는 사용자가 데이터를 분석하고 관리할 수 있도록 사용자 인터페이스를 제공합니다. 이 서버는 네트워크 서버로부터 데이터를 받아 사용자가 이해할 수 있는 형태로 가공하며, 사용자의 명령을 네트워크 서버로 전송하여 디바이스단의 동작을 제어할 수 있습니다
LoRA 네트워크의 보안은 여러 계층에서 구현되며, 이는 데이터의 무결성과 기기의 인증을 보장하기 위해 설계되었습니다. 주요 보안 기능은 다음과 같습니다:
- 네트워크 세션 키 (Network Session Key): 이 키는 네트워크 서버와 디바이스 간의 통신을 암호화하여 네트워크 레벨의 보안을 제공합니다.
- 애플리케이션 세션 키 (Application Session Key): 이 키는 애플리케이션 서버와 디바이스 간의 통신을 암호화하여 애플리케이션 데이터의 보안을 담당합니다.
- 장치 주소 (Device Address): 각 LoRA 디바이스는 고유한 주소를 가지며, 이를 통해 네트워크는 디바이스를 식별하고 관리합니다.
- 메시지 무결성 코드 (MIC): 전송된 각 메시지에는 MIC가 포함되어 있어, 메시지가 변경되지 않았음을 확인하고, 메시지의 출처가 유효한 디바이스임을 보증합니다.
- 하드웨어 보안 모듈 (Hardware Security Module): 일부 LoRA 솔루션은 키 관리와 암호화 작업을 위해 하드웨어 보안 모듈을 사용합니다. 이는 물리적 해킹으로부터 키를 보호하고, 보안성을 높입니다.
이러한 보안 메커니즘은 LoRA 네트워크가 안전하게 운영될 수 있도록 하며, 다양한 IoT 환경에서의 신뢰성 있는 데이터 전송을 가능하게 합니다. 또한, LoRA Alliance에서 정의한 LoRaWAN 프로토콜은 이러한 보안 기능들을 표준화하여, 네트워크의 호환성과 보안을 강화하고 있습니다.
LoRa Gateway Uplink: radio packets 는 gateway 에 의해 수신된다 , 그리고 Gateway 에 의해 메터데이터가 더해지고 여기에 Gateway Status 정보가 더해져서 Network Server 로 forward 처리된다.
LoRa Gateway Downlink: Network Server 에 의해 패킷이 생성되고 , 부가적인 메터데이터를 포함될수 있고, 또한 Gateway 의 Configuration Data 도 포함되서 Gateway 의 Radio Channel 로 Transmit 된다
SemTech 사가 공개하는 디바이스단의 펌웨어 소스는 ClassA/B/C end-device 구현시 Periodically uplinks a frame 은 the Cayenne LPP protocol 을 사용한다. Cayenne Low Power Payload (LPP) 은 편리하고 쉬운 방안을 제공해서 LoRaWAN 같은 LPWAN networks 로 데이터를 Send 를 구현한다 ... Cayenne LPP 는 payload size restriction 이 있다 11 bytes 보다 적은 수 만 한번에 센서 데이터들을 LoRa 디바이스가 Send 하는것을 허용한다.
로라통신의 보안 메커니즘에서, MAC( Message Authentication Code )은 메시지의 위변조를 확인하기 위해 쓰이는 보안 기술 입니다. CMAC은 알고리즘과 모드 에 따라 AES CBC-MAC 메커니즘이 있구요 ... CMAC 도 마찬가지로 주된 기능은 사용자 인증(authentication)과 데이터 무결성(data integerity) 처리를 위한것 입니다 ... MAC 은 MAC 을 만들때 Block 함수를 사용하면 CMAC( Cipher-based Message Authentication Code )가 됩니다 ...
SX1301 칩셋을 사용하여 LoRa 게이트웨이에서의 주요 기능을 구현하는 방법을 이해하기 위해, 각 기능과 관련된 레지스터 설정을 상세히 설명하겠습니다. SX1301은 LoRaWAN 네트워크의 핵심 구성 요소로서, 디바이스와 네트워크 서버 간의 통신을 관리합니다.
LoRa 게이트웨이의 핵심 역할과 SX1301의 레지스터 설정
- 신호 수신 및 송신
- 역할: LoRa 디바이스로부터 신호를 수신하고, 네트워크 서버로 데이터를 송신합니다.
- 제어 레지스터: REG_OP_MODE, REG_PACONFIG, REG_RFLR_PADAC, REG_HOP_PERIOD
- 수신 모드 설정: REG_OP_MODE 레지스터에서 수신 모드를 설정합니다. 이 레지스터의 값에 따라 칩셋이 수신 모드로 작동하도록 설정할 수 있습니다.
- 송신 모드 설정: REG_OP_MODE 레지스터의 설정을 통해 송신 모드로 전환합니다.
- 주파수 설정: REG_FRF_MSB, REG_FRF_MID, REG_FRF_LSB 레지스터를 통해 주파수를 설정합니다. 이 레지스터들에 대해 원하는 주파수 값을 설정하여, 송신 및 수신 주파수를 조정합니다.
- 출력 전력 설정: REG_PACONFIG, REG_RFLR_PADAC 레지스터를 사용하여 송신 전력을 설정합니다.
- 프레임 복조 및 디코딩
- 역할: 수신된 LoRa 프레임을 복조하고 디코딩하여 네트워크 서버에 전달할 수 있는 데이터로 변환합니다.
- 제어 레지스터: REG_MODEM_CONFIG1, REG_MODEM_CONFIG2, REG_DETECTION_OPTIMIZE, REG_DETECTION_THRESHOLD
- 복조 방식 설정: REG_MODEM_CONFIG1 및 REG_MODEM_CONFIG2 레지스터를 통해 모듈레이션 방식, 대역폭, 코드율 등을 설정합니다.
- 프레임 검출 설정: REG_DETECTION_OPTIMIZE, REG_DETECTION_THRESHOLD 레지스터를 사용하여 패킷의 신호 검출 임계값을 조정합니다.
- 네트워크 서버와의 통신
- 역할: 수신한 데이터를 네트워크 서버에 전송하고, 네트워크 서버의 명령을 디바이스에 전달합니다.
- 제어 레지스터: REG_FIFO, REG_FIFO_ADDR_PTR, REG_FIFO_TX_BASE_ADDR
- 패킷 전송: REG_FIFO 레지스터를 통해 송신할 데이터 패킷을 FIFO에 쓰고, 송신 작업을 시작합니다.
- 패킷 수신: REG_FIFO 레지스터를 통해 수신된 패킷을 읽어들입니다. REG_FIFO_ADDR_PTR 레지스터를 사용하여 읽을 데이터의 위치를 지정합니다.
- 패킷 처리 및 필터링
- 역할: 수신된 패킷을 필터링하고, 오류가 있거나 불필요한 패킷을 제거합니다.
- 제어 레지스터: REG_PKT_SNR_VALUE, REG_PKT_RSSI_VALUE, REG_RX_NB_BYTES
- 패킷 필터링: REG_PKT_SNR_VALUE와 REG_PKT_RSSI_VALUE 레지스터를 통해 패킷의 신호 대 잡음비(SNR)와 수신 신호 세기(RSSI)를 모니터링하여 유효한 패킷을 필터링합니다.
- 패킷 길이 설정: REG_RX_NB_BYTES 레지스터를 통해 수신할 패킷의 길이를 설정합니다.
- 주파수 동기화 및 시간 동기화
- 역할: LoRa 디바이스와의 주파수 및 시간 동기화를 통해 정확한 데이터 전송 및 수신을 보장합니다.
- 제어 레지스터: REG_SYNC_WORD, REG_HOP_PERIOD
- 동기화 단어 설정: REG_SYNC_WORD 레지스터를 사용하여 동기화 단어를 설정합니다. 이 단어는 디바이스와의 통신에서 동기화를 보장합니다.
- 주파수 홉 설정: REG_HOP_PERIOD 레지스터를 통해 주파수 홉 주기를 설정하여 동기화의 정확성을 높입니다.
결론
SX1301 칩셋의 각 레지스터는 LoRa 게이트웨이의 핵심 기능을 구현하는 데 중요한 역할을 합니다. 신호 수신 및 송신, 프레임 복조 및 디코딩, 네트워크 서버와의 통신, 패킷 처리 및 필터링, 주파수 및 시간 동기화는 모두 이러한 레지스터 설정을 통해 효과적으로 수행됩니다. 이들 레지스터를 적절히 제어함으로써, 게이트웨이는 LoRaWAN 네트워크의 원활한 운영을 지원합니다.
LoRa 게이트웨이는 LoRa 패킷을 IP 패킷으로 변환하여 네트워크 서버로 전송하고, 네트워크 서버에서 받은 IP 패킷을 LoRa 패킷으로 변환하여 LoRa 디바이스로 전송합니다. 이 과정은 게이트웨이의 소프트웨어와 네트워크 구조에 의해 관리됩니다. 상세한 송수신 구조와 방식을 설명하겠습니다.
1. LoRa 패킷을 IP 패킷으로 변환하여 네트워크 서버로 전송하는 과정
구조와 방식
- LoRa 패킷 수신
- SX1301 역할: LoRa 디바이스에서 수신된 무선 신호를 디지털 데이터로 복조합니다.
- 레지스터: REG_FIFO, REG_FIFO_ADDR_PTR를 통해 수신된 패킷 데이터를 읽습니다.
- 패킷 처리
- 게이트웨이 애플리케이션 프로세서:
- 수신 데이터의 디코딩: SX1301에서 받은 데이터를 애플리케이션 프로세서가 해석합니다. 데이터는 LoRaWAN 프로토콜에 따라 포맷이 지정되어 있습니다.
- LoRaWAN 프레임 추출: 수신된 LoRa 프레임을 LoRaWAN의 MAC (Medium Access Control) 프레임으로 디코딩하여, 페이로드와 메타데이터(예: 디바이스 주소, 패킷 순서 등)를 추출합니다.
- 게이트웨이 애플리케이션 프로세서:
- IP 패킷 변환
- 게이트웨이 소프트웨어:
- LoRaWAN 데이터의 IP 패킷화: 디코딩된 LoRaWAN 데이터와 메타데이터를 IP 패킷으로 변환합니다. 이 과정에서는 LoRaWAN 프로토콜에서 IP 패킷 포맷으로 데이터를 변환하는 작업이 필요합니다. 일반적으로 MQTT, HTTP, UDP 등 IP 프로토콜을 사용하여 네트워크 서버와 통신합니다.
- 게이트웨이 소프트웨어:
- 네트워크 서버로 전송
- 전송 프로토콜:
- MQTT: LoRaWAN 게이트웨이는 MQTT 프로토콜을 사용하여 IP 패킷을 네트워크 서버로 전송합니다. MQTT는 메시지 브로커를 통해 IP 패킷을 전송하는 방식입니다.
- HTTP/HTTPS: HTTP API를 통해 IP 패킷을 POST 요청으로 전송합니다.
- UDP: UDP 패킷을 통해 IP 패킷을 전송합니다.
- 전송 프로토콜:
2. 네트워크 서버에서 받은 IP 패킷을 LoRa 패킷으로 변환하여 디바이스로 전송하는 과정
구조와 방식
- IP 패킷 수신
- 네트워크 서버 역할: IP 네트워크를 통해 LoRa 게이트웨이로 IP 패킷을 전달합니다.
- IP 패킷 처리
- 네트워크 서버 소프트웨어:
- IP 패킷 디코딩: 네트워크 서버는 IP 패킷에서 LoRaWAN 데이터와 메타데이터를 추출합니다. 이 데이터는 특정 디바이스로 전송될 메시지와 명령을 포함하고 있습니다.
- 네트워크 서버 소프트웨어:
- LoRa 패킷 변환
- 게이트웨이 소프트웨어:
- LoRaWAN 데이터 포맷: IP 패킷의 데이터를 LoRaWAN 프레임으로 변환합니다. 여기서는 LoRaWAN 프로토콜에 맞게 데이터 포맷을 재구성합니다.
- LoRa 프레임 인코딩: LoRaWAN 데이터와 메타데이터를 LoRa 패킷으로 인코딩하여 송신 준비를 합니다.
- 게이트웨이 소프트웨어:
- LoRa 패킷 전송
- SX1301 역할:
- 패킷 송신: REG_FIFO, REG_FIFO_ADDR_PTR, REG_FIFO_TX_BASE_ADDR 레지스터를 사용하여 LoRa 패킷을 FIFO 버퍼에 작성합니다. 이후, REG_OP_MODE 레지스터를 통해 송신 모드를 활성화하여 패킷을 송신합니다.
- 무선 송신: SX1301은 설정된 주파수와 송신 전력으로 패킷을 무선으로 전송합니다.
- SX1301 역할:
요약
- LoRa 패킷 → IP 패킷:
- SX1301: LoRa 신호를 디지털 데이터로 변환.
- 게이트웨이 애플리케이션 프로세서: 데이터 디코딩 및 IP 패킷화.
- 게이트웨이 소프트웨어: IP 패킷 전송 (MQTT, HTTP, UDP).
- IP 패킷 → LoRa 패킷:
- 네트워크 서버: IP 패킷을 디코딩.
- 게이트웨이 소프트웨어: LoRaWAN 데이터 포맷으로 변환.
- SX1301: LoRa 패킷 송신.
이와 같은 구조와 방식으로, LoRa 게이트웨이는 LoRa 디바이스와 네트워크 서버 간의 데이터 송수신을 원활하게 처리합니다.
로라통신은 스마트팜 구현분야에 적용 가능하고 각종 데이터 송수신시 이 데이터들의 보안처리가 중요한 이슈이기에 로라통신에는 AES-CMAC 보안 알고리즘으로 동작하게 규격문서가 그렇게 설계되 있구요 ... 저는 로라통신에 적용되는 암호화/복호화 알고리즘 설계 기술을 확실하게 확보 성공했읍니다 ... 이 부분 감안해서 장거리 저전력 무선통신 로라통신 펌웨어 개발이 가능 합니다 ...
딥네트워크 장석원 010 3350 6509 sayhi7@daum.net 으로 로라통신 펌웨어 개발 문의 부탁드립니다
'Kernel Porting > Linux' 카테고리의 다른 글
[위상배열안테나 Beamforming 제어 개발 및 기술자문 전문] 저희 딥네트워크는 위상배열안테나 어레이와 Phase Shifter 를 적용해 정밀한 Beamforming 제어가 가능한 노하우를 보유하고 있읍니다 ...
2024. 6. 28. 17:47
딥네트워크 빔포밍(Beamforming) 관련 보유기술 소개 ...
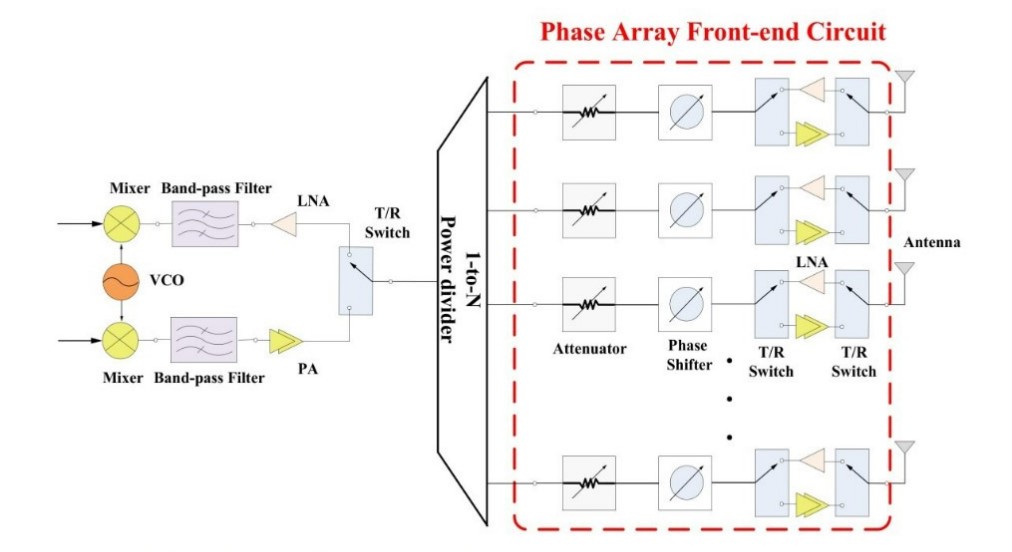
- 위상배열안테나 어레이 와 Phase Shifter 를 적용해 위상배열안테나로 송출시 각각의 Phase Shifter 의 위상을 제어해서 위상배열안테나 어레이 전체의 조향각 제어 알고리즘 수식 확보 성공 ...
- 위상배열안테나 어레이 와 Phase Shifter 를 적용해 위상배열안테나로 송출시 위상배열안테나 어레이 각각의 제어이득 조절을 돌프 체비세프 위도우를 적용해 Main Lobe 와 Side Lobe 의 감쇄 이득 조절을 위한 제어 알고리즘 수식 확보 성공
- 송신 측에서 8 GHz 주파수 대역을 사용하여 16QAM으로 변조한 신호는 수신 측에서 IF 주파수로 변환되더라도, 변조된 정보(데이터)는 변하지 않습니다. 변환된 IF 신호는 8 GHz에서 변조된 신호와 동일한 데이터를 포함하고 있으며, 이를 이용해 수신 측에서 변복조 과정을 수행하여 원래의 데이터를 복원하는 노하우 확보 성공.
- 위성 데이터 송수신을 위해 16QAM 변조 및 복조 알고리즘이 필요한데 이것의 동작 알고리즘 수식 확보 성공 ....
- 위성데이터 송수신시 송수신 데이터가 오류가 있을때 오류가 난 데이터를 보정해주는 FEC 에러 보정 알고리즘 수식 확보 성공
16QAM(16 Quadrature Amplitude Modulation) 변조 신호가 수신 측에서 IF(Intermediate Frequency) 주파수로 변환되더라도 변조된 정보가 왜 변하지 않는지 이해하기 위해서는 주파수 변환의 기본 원리와 16QAM 변조 방식을 자세히 살펴볼 필요가 있습니다. 또한 RF 하드웨어 설계와 펌웨어 구현 방법을 각각 5가지 핵심 사항으로 상세히 설명하겠습니다.
1. 16QAM 변조 신호의 정보 보존
주파수 변환의 원리
- 변조 신호: 16QAM은 디지털 데이터를 16개의 서로 다른 심볼로 변조합니다. 각 심볼은 I(인페이즈)와 Q(쿼드라처) 성분의 조합으로 표현됩니다. 변조된 신호는 고주파수 대역(예: 8 GHz)에서 전송됩니다.
- 주파수 변환: RF 신호를 IF 주파수로 변환할 때, 주파수 변환 과정은 신호의 정보 자체를 변경하지 않습니다. 단지 신호의 주파수 대역을 이동시키는 과정입니다. RF 신호와 로컬 오실레이터(LO) 신호를 믹서에서 혼합하여 IF 신호를 생성합니다.
변조된 정보의 유지
- 신호의 일관성: 16QAM 신호에서 정보는 I/Q 평면상의 심볼 패턴에 의해 정의됩니다. 주파수 변환은 신호의 이러한 심볼 패턴을 변형하지 않고, 단순히 신호의 주파수 대역을 이동시킵니다.
- 정보 전송: 변환된 IF 신호는 원래의 변조 정보와 동일한 I/Q 평면상의 패턴을 유지하므로, 원래의 데이터는 IF 신호에서 변하지 않고 그대로 유지됩니다.
Wilkinson Power Divider를 이용한 8x8 위상배열안테나 어레이 설계와 구현 - 딥네트워크는 안테나 어레이 설계시 RF 전력 급전 회로망 설계 부분도 다음과 같이 검토가 됬읍니다 ...
위상 배열 안테나 시스템에서 Wilkinson Power Divider를 사용하여 병렬 및 직렬 급전 회로망을 설계하는 방법을 설명합니다.
1. Wilkinson Power Divider의 역할
Wilkinson Power Divider는 신호를 여러 경로로 균등하게 분배하고, 각 경로 간의 전기적 고립을 보장하는 데 사용됩니다. 이는 위상 배열 안테나에서 신호 분배에 필수적입니다.
2. 8x8 위상 배열 안테나 개요
8x8 위상 배열 안테나는 64개의 개별 안테나 요소로 구성되며, 각각의 요소는 특정 위상과 전력을 가지도록 조절됩니다. 이를 통해 빔의 방향과 형태를 제어할 수 있습니다.
병렬 급전 회로망 설계
병렬 급전 회로망은 모든 안테나 요소에 동일한 전력과 위상으로 신호를 분배하는 방식입니다. 다음은 병렬 급전 회로망의 설계와 구현 단계입니다:
- 1단계: Wilkinson Power Divider 사용
- 첫 번째 Wilkinson Power Divider는 입력 신호를 두 개의 경로로 나눕니다.
- 각 경로는 다시 Wilkinson Power Divider에 연결되어 4개의 출력으로 나뉩니다.
- 이 과정은 8x8 배열을 위해 총 6단계 반복됩니다 (64 = 2^6).
- 2단계: 안테나 배열 연결
- 마지막 단계의 각 출력은 개별 안테나 요소에 연결됩니다.
- 각 안테나 요소는 동일한 전력을 받고, 고립을 보장하여 신호 간섭을 방지합니다.
- 3단계: 신호 일치 및 제어
- 모든 안테나 요소에 동일한 위상의 신호가 도달하도록 조절됩니다.
- 이를 통해 특정 방향으로 신호가 집속되며, 빔의 방향을 제어할 수 있습니다.
직렬 급전 회로망 설계
직렬 급전 회로망은 신호를 순차적으로 각 안테나 요소에 전달하여 점진적으로 전력을 감소시키는 방식입니다. 다음은 직렬 급전 회로망의 설계와 구현 단계입니다:
- 1단계: Wilkinson Power Divider 사용
- 첫 번째 Wilkinson Power Divider는 신호를 두 개의 경로로 나눕니다.
- 각 경로는 순차적으로 각 안테나 요소에 연결됩니다.
- 각 요소에서 사용된 신호는 다음 요소로 전달되며, 점진적으로 전력이 감소합니다.
- 2단계: 위상 조정
- 각 요소 사이에 위상 이동기를 삽입하여 신호의 위상을 조정합니다.
- 이를 통해 특정 방향으로 신호가 집속되도록 제어합니다.
- 3단계: 신호 일치 및 제어
- 첫 번째 요소는 최대 전력을 받고, 각 요소를 지나면서 전력이 감소하도록 설계됩니다.
- 위상 이동을 통해 빔의 방향을 조절할 수 있습니다.
구현 세부사항
- 안테나 요소 배치
- 8x8 배열의 각 안테나 요소는 동일한 간격으로 배치됩니다.
- 요소 간의 간격은 일반적으로 λ/2 (파장의 절반)로 설정됩니다.
- 전력 분배 네트워크
- Wilkinson Power Divider는 마이크로스트립 라인으로 구현됩니다.
- 각 분배기는 3 dB의 삽입 손실과 높은 고립을 가집니다.
- 위상 이동기
- 위상 이동기는 전자식 또는 기계식으로 구현될 수 있습니다.
- 전자식 위상 이동기는 빠른 속도와 정밀한 제어가 가능합니다.
딥네트워크와 위의 기술관련해서 저와 관련 방산 대기업 관계자분의 공동연구(기술협력)이 가능하시면 연락 부탁드립니다 ...
딥네트워크 장석원 010-3350 6509 sayhi7@daum.net 관련해서 문의주시면 감사하겠읍니다 ...
'Kernel Porting > Linux' 카테고리의 다른 글
[X 밴드대역 위성 데이터 송수신 기술이전 가능] 딥네트워크 장석원 입니다 ...
2024. 6. 28. 13:30
딥네트워크 빔포밍(Beamforming) 관련 보유기술 소개 ...
- 위상배열안테나 어레이 와 Phase Shifter 를 적용해 위상배열안테나로 송출시 각각의 Phase Shifter 의 위상을 제어해서 위상배열안테나 어레이 전체의 조향각 제어 알고리즘 수식 확보 성공 ...
- 위상배열안테나 어레이 와 Phase Shifter 를 적용해 위상배열안테나로 송출시 위상배열안테나 어레이 각각의 제어이득 조절을 돌프 체비세프 위도우를 적용해 Main Lobe 와 Side Lobe 의 감쇄 이득 조절을 위한 제어 알고리즘 수식 확보 성공
- 송신 측에서 8 GHz 주파수 대역을 사용하여 16QAM으로 변조한 신호는 수신 측에서 IF 주파수로 변환되더라도, 변조된 정보(데이터)는 변하지 않습니다. 변환된 IF 신호는 8 GHz에서 변조된 신호와 동일한 데이터를 포함하고 있으며, 이를 이용해 수신 측에서 변복조 과정을 수행하여 원래의 데이터를 복원하는 노하우 확보 성공.
- 위성 데이터 송수신을 위해 16QAM 변조 및 복조 알고리즘이 필요한데 이것의 동작 알고리즘 수식 확보 성공 ....
- 위성데이터 송수신시 송수신 데이터가 오류가 있을때 오류가 난 데이터를 보정해주는 FEC 에러 보정 알고리즘 수식 확보 성공
16QAM(16 Quadrature Amplitude Modulation) 변조 신호가 수신 측에서 IF(Intermediate Frequency) 주파수로 변환되더라도 변조된 정보가 왜 변하지 않는지 이해하기 위해서는 주파수 변환의 기본 원리와 16QAM 변조 방식을 자세히 살펴볼 필요가 있습니다. 또한 RF 하드웨어 설계와 펌웨어 구현 방법을 각각 5가지 핵심 사항으로 상세히 설명하겠습니다.
1. 16QAM 변조 신호의 정보 보존
주파수 변환의 원리
- 변조 신호: 16QAM은 디지털 데이터를 16개의 서로 다른 심볼로 변조합니다. 각 심볼은 I(인페이즈)와 Q(쿼드라처) 성분의 조합으로 표현됩니다. 변조된 신호는 고주파수 대역(예: 8 GHz)에서 전송됩니다.
- 주파수 변환: RF 신호를 IF 주파수로 변환할 때, 주파수 변환 과정은 신호의 정보 자체를 변경하지 않습니다. 단지 신호의 주파수 대역을 이동시키는 과정입니다. RF 신호와 로컬 오실레이터(LO) 신호를 믹서에서 혼합하여 IF 신호를 생성합니다.
변조된 정보의 유지
- 신호의 일관성: 16QAM 신호에서 정보는 I/Q 평면상의 심볼 패턴에 의해 정의됩니다. 주파수 변환은 신호의 이러한 심볼 패턴을 변형하지 않고, 단순히 신호의 주파수 대역을 이동시킵니다.
- 정보 전송: 변환된 IF 신호는 원래의 변조 정보와 동일한 I/Q 평면상의 패턴을 유지하므로, 원래의 데이터는 IF 신호에서 변하지 않고 그대로 유지됩니다.
Wilkinson Power Divider를 이용한 8x8 위상배열안테나 어레이 설계와 구현 - 딥네트워크는 안테나 어레이 설계시 RF 전력 급전 회로망 설계 부분도 다음과 같이 검토가 됬읍니다 ...
위상 배열 안테나 시스템에서 Wilkinson Power Divider를 사용하여 병렬 및 직렬 급전 회로망을 설계하는 방법을 설명합니다.
1. Wilkinson Power Divider의 역할
Wilkinson Power Divider는 신호를 여러 경로로 균등하게 분배하고, 각 경로 간의 전기적 고립을 보장하는 데 사용됩니다. 이는 위상 배열 안테나에서 신호 분배에 필수적입니다.
2. 8x8 위상 배열 안테나 개요
8x8 위상 배열 안테나는 64개의 개별 안테나 요소로 구성되며, 각각의 요소는 특정 위상과 전력을 가지도록 조절됩니다. 이를 통해 빔의 방향과 형태를 제어할 수 있습니다.
병렬 급전 회로망 설계
병렬 급전 회로망은 모든 안테나 요소에 동일한 전력과 위상으로 신호를 분배하는 방식입니다. 다음은 병렬 급전 회로망의 설계와 구현 단계입니다:
- 1단계: Wilkinson Power Divider 사용
- 첫 번째 Wilkinson Power Divider는 입력 신호를 두 개의 경로로 나눕니다.
- 각 경로는 다시 Wilkinson Power Divider에 연결되어 4개의 출력으로 나뉩니다.
- 이 과정은 8x8 배열을 위해 총 6단계 반복됩니다 (64 = 2^6).
- 2단계: 안테나 배열 연결
- 마지막 단계의 각 출력은 개별 안테나 요소에 연결됩니다.
- 각 안테나 요소는 동일한 전력을 받고, 고립을 보장하여 신호 간섭을 방지합니다.
- 3단계: 신호 일치 및 제어
- 모든 안테나 요소에 동일한 위상의 신호가 도달하도록 조절됩니다.
- 이를 통해 특정 방향으로 신호가 집속되며, 빔의 방향을 제어할 수 있습니다.
직렬 급전 회로망 설계
직렬 급전 회로망은 신호를 순차적으로 각 안테나 요소에 전달하여 점진적으로 전력을 감소시키는 방식입니다. 다음은 직렬 급전 회로망의 설계와 구현 단계입니다:
- 1단계: Wilkinson Power Divider 사용
- 첫 번째 Wilkinson Power Divider는 신호를 두 개의 경로로 나눕니다.
- 각 경로는 순차적으로 각 안테나 요소에 연결됩니다.
- 각 요소에서 사용된 신호는 다음 요소로 전달되며, 점진적으로 전력이 감소합니다.
- 2단계: 위상 조정
- 각 요소 사이에 위상 이동기를 삽입하여 신호의 위상을 조정합니다.
- 이를 통해 특정 방향으로 신호가 집속되도록 제어합니다.
- 3단계: 신호 일치 및 제어
- 첫 번째 요소는 최대 전력을 받고, 각 요소를 지나면서 전력이 감소하도록 설계됩니다.
- 위상 이동을 통해 빔의 방향을 조절할 수 있습니다.
구현 세부사항
- 안테나 요소 배치
- 8x8 배열의 각 안테나 요소는 동일한 간격으로 배치됩니다.
- 요소 간의 간격은 일반적으로 λ/2 (파장의 절반)로 설정됩니다.
- 전력 분배 네트워크
- Wilkinson Power Divider는 마이크로스트립 라인으로 구현됩니다.
- 각 분배기는 3 dB의 삽입 손실과 높은 고립을 가집니다.
- 위상 이동기
- 위상 이동기는 전자식 또는 기계식으로 구현될 수 있습니다.
- 전자식 위상 이동기는 빠른 속도와 정밀한 제어가 가능합니다.
딥네트워크와 위의 기술관련해서 저와 관련 방산 대기업 관계자분의 공동연구(기술협력)이 가능하시면 연락 부탁드립니다 ...
딥네트워크 장석원 010-3350 6509 sayhi7@daum.net 관련해서 문의주시면 감사하겠읍니다 ...
'Kernel Porting > Linux' 카테고리의 다른 글
제가 운영하는 일인기업 딥네트워크는 AESA Radar 의 위상배열안테나 어레이를 적용해 Beamforming 기술 펌웨어 구현 노하우를 98 % 보유하고 있읍니다 ...
2024. 6. 22. 18:23
제가 운영하는 일인기업 딥네트워크는 AESA Radar 의 위상배열안테나 어레이를 적용해 Beamforming 기술 구현 노하우를 98 % 보유하고 있읍니다 ...
관심있는 방산 기업들의 기술협력 문의 부탁드립니다 ....
1. 위상 배열 안테나 어레이
위상 배열 안테나 어레이는 다수의 개별 안테나 요소로 구성되며, 각각의 요소가 독립적으로 제어됩니다. 이 안테나 어레이는 전파의 위상을 조절함으로써 빔의 방향을 전자적으로 제어할 수 있습니다.
2. 빔포밍 원리
빔포밍은 여러 안테나 요소에서 방사된 전파가 특정 방향으로 결합되도록 위상을 조절하는 기술입니다. 이를 통해 신호의 이득을 높이고, 특정 방향으로 전파를 집중시킬 수 있습니다.
3. 빔포밍 구현 단계
1) 신호 생성 및 위상 제어
각 안테나 요소에 공급되는 신호의 위상을 조절하기 위해 위상 변이기(Phase Shifter)를 사용합니다. 이는 전파의 합성 방향을 바꾸는 데 필수적입니다.
2) T/R 모듈
각 안테나 요소에는 송수신 모듈(T/R Module)이 포함되어 있습니다. 이 모듈은 신호의 증폭, 위상 조절, 송수신 전환 등을 수행합니다.
3) 신호 처리
디지털 신호 프로세서(DSP) 또는 FPGA를 사용하여 각 안테나 요소에서 수신된 신호를 디지털로 변환하고, 필요한 신호 처리를 수행합니다. 이를 통해 고해상도의 이미지나 데이터를 얻을 수 있습니다.
4) 전자적 빔 스캐닝
빔의 방향을 바꾸기 위해 물리적으로 안테나를 움직일 필요 없이 전자적으로 위상을 조절하여 빔을 스캔합니다. 이는 매우 빠르게 여러 방향을 탐색하고, 목표를 추적하는 데 유리합니다.
4. 이점
- 신속한 방향 전환: 물리적 움직임 없이 전자적으로 빔 방향을 변경할 수 있어, 매우 빠르게 여러 목표를 탐지하고 추적할 수 있습니다.
- 높은 해상도: 각 안테나 요소의 신호를 종합하여 고해상도의 이미지를 얻을 수 있습니다.
- 내구성 및 신뢰성: 기계적 부품이 적어 내구성이 높고 신뢰성이 우수합니다.
5. 응용 분야
AESA 레이더는 항공기, 군함, 지상 레이더 시스템 등 다양한 분야에 적용되며, 주로 군사 및 방위 목적으로 사용됩니다. 최근에는 민간 항공기와 기상 관측 시스템 등에서도 그 활용이 확대되고 있습니다.
이 기술은 고도의 정밀성과 빠른 반응 속도를 요구하는 현대 전자전과 방어 시스템에서 필수적인 역할을 합니다.
딥네트워크 빔포밍(Beamforming) 관련 보유기술 소개 ...
- 위상배열안테나 어레이 와 Phase Shifter 를 적용해 위상배열안테나로 송출시 각각의 Phase Shifter 의 위상을 제어해서 위상배열안테나 어레이 전체의 조향각 제어 알고리즘 수식 확보 성공 ...
- 위상배열안테나 어레이 와 Phase Shifter 를 적용해 위상배열안테나로 송출시 위상배열안테나 어레이 각각의 제어이득 조절을 돌프 체비세프 위도우를 적용해 Main Lobe 와 Side Lobe 의 감쇄 이득 조절을 위한 제어 알고리즘 수식 확보 성공
- 송신 측에서 8 GHz 주파수 대역을 사용하여 16QAM으로 변조한 신호는 수신 측에서 IF 주파수로 변환되더라도, 변조된 정보(데이터)는 변하지 않습니다. 변환된 IF 신호는 8 GHz에서 변조된 신호와 동일한 데이터를 포함하고 있으며, 이를 이용해 수신 측에서 변복조 과정을 수행하여 원래의 데이터를 복원하는 노하우 확보 성공.
- 위성 데이터 송수신을 위해 16QAM 변조 및 복조 알고리즘이 필요한데 이것의 동작 알고리즘 수식 확보 성공 ....
- 위성데이터 송수신시 송수신 데이터가 오류가 있을때 오류가 난 데이터를 보정해주는 FEC 에러 보정 알고리즘 수식 확보 성공
16QAM(16 Quadrature Amplitude Modulation) 변조 신호가 수신 측에서 IF(Intermediate Frequency) 주파수로 변환되더라도 변조된 정보가 왜 변하지 않는지 이해하기 위해서는 주파수 변환의 기본 원리와 16QAM 변조 방식을 자세히 살펴볼 필요가 있습니다. 또한 RF 하드웨어 설계와 펌웨어 구현 방법을 각각 5가지 핵심 사항으로 상세히 설명하겠습니다.
1. 16QAM 변조 신호의 정보 보존
주파수 변환의 원리
- 변조 신호: 16QAM은 디지털 데이터를 16개의 서로 다른 심볼로 변조합니다. 각 심볼은 I(인페이즈)와 Q(쿼드라처) 성분의 조합으로 표현됩니다. 변조된 신호는 고주파수 대역(예: 8 GHz)에서 전송됩니다.
- 주파수 변환: RF 신호를 IF 주파수로 변환할 때, 주파수 변환 과정은 신호의 정보 자체를 변경하지 않습니다. 단지 신호의 주파수 대역을 이동시키는 과정입니다. RF 신호와 로컬 오실레이터(LO) 신호를 믹서에서 혼합하여 IF 신호를 생성합니다.
변조된 정보의 유지
- 신호의 일관성: 16QAM 신호에서 정보는 I/Q 평면상의 심볼 패턴에 의해 정의됩니다. 주파수 변환은 신호의 이러한 심볼 패턴을 변형하지 않고, 단순히 신호의 주파수 대역을 이동시킵니다.
- 정보 전송: 변환된 IF 신호는 원래의 변조 정보와 동일한 I/Q 평면상의 패턴을 유지하므로, 원래의 데이터는 IF 신호에서 변하지 않고 그대로 유지됩니다.
Wilkinson Power Divider를 이용한 8x8 위상배열안테나 어레이 설계와 구현 - 딥네트워크는 안테나 어레이 설계시 RF 전력 급전 회로망 설계 부분도 다음과 같이 검토가 됬읍니다 ...
위상 배열 안테나 시스템에서 Wilkinson Power Divider를 사용하여 병렬 및 직렬 급전 회로망을 설계하는 방법을 설명합니다.
1. Wilkinson Power Divider의 역할
Wilkinson Power Divider는 신호를 여러 경로로 균등하게 분배하고, 각 경로 간의 전기적 고립을 보장하는 데 사용됩니다. 이는 위상 배열 안테나에서 신호 분배에 필수적입니다.
2. 8x8 위상 배열 안테나 개요
8x8 위상 배열 안테나는 64개의 개별 안테나 요소로 구성되며, 각각의 요소는 특정 위상과 전력을 가지도록 조절됩니다. 이를 통해 빔의 방향과 형태를 제어할 수 있습니다.
병렬 급전 회로망 설계
병렬 급전 회로망은 모든 안테나 요소에 동일한 전력과 위상으로 신호를 분배하는 방식입니다. 다음은 병렬 급전 회로망의 설계와 구현 단계입니다:
- 1단계: Wilkinson Power Divider 사용
- 첫 번째 Wilkinson Power Divider는 입력 신호를 두 개의 경로로 나눕니다.
- 각 경로는 다시 Wilkinson Power Divider에 연결되어 4개의 출력으로 나뉩니다.
- 이 과정은 8x8 배열을 위해 총 6단계 반복됩니다 (64 = 2^6).
- 2단계: 안테나 배열 연결
- 마지막 단계의 각 출력은 개별 안테나 요소에 연결됩니다.
- 각 안테나 요소는 동일한 전력을 받고, 고립을 보장하여 신호 간섭을 방지합니다.
- 3단계: 신호 일치 및 제어
- 모든 안테나 요소에 동일한 위상의 신호가 도달하도록 조절됩니다.
- 이를 통해 특정 방향으로 신호가 집속되며, 빔의 방향을 제어할 수 있습니다.
직렬 급전 회로망 설계
직렬 급전 회로망은 신호를 순차적으로 각 안테나 요소에 전달하여 점진적으로 전력을 감소시키는 방식입니다. 다음은 직렬 급전 회로망의 설계와 구현 단계입니다:
- 1단계: Wilkinson Power Divider 사용
- 첫 번째 Wilkinson Power Divider는 신호를 두 개의 경로로 나눕니다.
- 각 경로는 순차적으로 각 안테나 요소에 연결됩니다.
- 각 요소에서 사용된 신호는 다음 요소로 전달되며, 점진적으로 전력이 감소합니다.
- 2단계: 위상 조정
- 각 요소 사이에 위상 이동기를 삽입하여 신호의 위상을 조정합니다.
- 이를 통해 특정 방향으로 신호가 집속되도록 제어합니다.
- 3단계: 신호 일치 및 제어
- 첫 번째 요소는 최대 전력을 받고, 각 요소를 지나면서 전력이 감소하도록 설계됩니다.
- 위상 이동을 통해 빔의 방향을 조절할 수 있습니다.
구현 세부사항
- 안테나 요소 배치
- 8x8 배열의 각 안테나 요소는 동일한 간격으로 배치됩니다.
- 요소 간의 간격은 일반적으로 λ/2 (파장의 절반)로 설정됩니다.
- 전력 분배 네트워크
- Wilkinson Power Divider는 마이크로스트립 라인으로 구현됩니다.
- 각 분배기는 3 dB의 삽입 손실과 높은 고립을 가집니다.
- 위상 이동기
- 위상 이동기는 전자식 또는 기계식으로 구현될 수 있습니다.
- 전자식 위상 이동기는 빠른 속도와 정밀한 제어가 가능합니다.
딥네트워크와 위의 기술관련해서 저와 관련 방산 대기업 관계자분의 공동연구(기술협력)이 가능하시면 연락 부탁드립니다 ...
딥네트워크 개발총괄 겸 대표 장석원 010-3350 6509 sayhi7@daum.net
관련해서 Beamforming 기술 협력 문의 부탁드립니다 ...
'Kernel Porting > Linux' 카테고리의 다른 글
기술전문 일인기업 딥네트워크를 운영중인데 대기업이나 중견기업에 저의 LLM(거대언어모델) 이나 로봇 제어 관련해서 저의 기술력 소개 제안서 넣을때 제일 어려운 점(고민 사항) 말씀드려 봅니다 ...
2024. 6. 20. 04:30
LLM 도 개발하려면 물론 소스코딩도 중요한데요 ... 저는 딥러닝 소스코딩 실력은 약간 모자르는것 인정 하구요 ... 딥러닝 LLM 을 대기업에서 개발시에 물론 소스 코딩 능력도 당연 중요한데 저는 이것보다 더 중요한게 현재 ChatGPT 유사 개발 진행시 가장 큰 이슈로 제가 생각하는것은 ChatGPT 에게 질문을 했을때 도대체 어떻게 ChatGPT 의 학습 알고리즘의 동작원리를 구성(설계/구현)해야 좀 더 정확한 답변이 가능할지 이런것들이 더 중요하다고 저는 판단하거든요 ... 이렇게 원천적인 ChatGPT 의 근본적인 동작 원리의 이슈 한두가지를 대기업에 제안해서 같이 고민해 보자고 제안했더니 핵심 이슈는 자기네 내부적으로 처리한다는 답변을 받았읍니다 ... 혹시 이런 부분의 협력을 조그만 부분부터 단계적으로 저희 딥네트워크와 함께 진행하실 기업이 있으실까요 ? 있으시면 아래의 이메일 주소로 연락 부탁드립니다 ...
또 한가지 저의 고민 분야는 로봇 설계 분야 입니다 ... 저는 로봇 설계의 핵심은 대략 2 가지로 보는데 그 한가지가 정밀모터제어쪽이고 또 하나는 로봇의 정밀 자세제어 부분 이라 생각 합니다 ... 정밀모터 제어를 PMSM Motor 로 FOC 제어를 처리하는 세부 알고리즘 구현 기법을 이해하고 있고 또 로봇의 정밀 자세제어를 위해 칼만필터를 적용해 로봇의 정밀 자세제어가 가능하게 칼만필터의 세부 구현 알고리즘 또한 깊이있게 이해하고 있읍니다 ... 저는 이 두가지 이슈에 대해 전문 지식이 있다는것 입니다 ... 이것도 대기업에 제안서를 넣어 놓고 결과를 기다리면서 제가 소기업이라 대기업이 이런것을 어떻게 검토해줄지 그런게 약간 아니 많이 걱정됩니다 ... 로봇 제어도 얼마전 중견기업에도 간략히 제안했었는데 자기네 이미 상용 기술 있다고 아예 검토의견도 없더라구요 ... 로봇 설계 기술 전체 다 는 아니어도 몇가지 이슈에 대한 전문 노하우를 확보하고 있는데 상대방에게 어떤식으로 제안해야 저희 로봇 기술력을 인정 받아 단계적으로 공동 협력이 가능할지 이런거 제안서 넣을때 부터 제안을 뭘 어떻게 해야 할지 이런거 다 고민이 태산 입니다 ... 로봇도 이렇게 핵심 이슈 두가지 확실한 기술력 확보가 되도 큰기업과 협력 방안 마련이 참 쉽지 않은게 상대방도 저를 잘 모르니 제가 상대방에게 어떻게 제안 해야 할지 고민이 너무 많읍니다 ...
기술전문 일인기업 딥네트워크 장석원 sayhi7@daum.net 010-3350 6509 로 부담없이 문의 주시면 감사하겠읍니다 ...
'Kernel Porting > Linux' 카테고리의 다른 글
[CAN 통신 개발 및 자문 전문][일인기업 딥네트워크] CAN 통신 동작원리 및 세부 펌웨어 구조 분석 ...
2024. 6. 18. 01:04
제가 운영하는 딥네트워크가 그동안 검토분석한 CAN 통신 펌웨어 설계 기술로 CANopen 기술로 PDO (Process Data Object) 와 SDO (Service Data Object)를 사용하여 다양한 데이터를 전송합니다. PDO는 고속 데이터 전송을 위한 프로토콜으로, 일반적으로 하나의 CAN 프레임에 대한 하나의 데이터를 포함합니다. 반면에 SDO는 OD Entry에 대한 접근제어 방식으로, 추가적인 정보와 인자를 포함하여 더 구체적인 데이터를 전송할 수 있습니다.
정밀 CAN 통신 디버깅 툴로는 Vector사의 CANoe와 PCAN Explorer가 대표적입니다. 이 외에도 CANlink와 고급 오실로스코프 같은 고가의 도구가 반드시 필요합니다
CANopen에서 NTM (Network Management)와 관련된 OD (Object Dictionary) 엔트리에 대한 접근 방식은 CAN FD 프레임을 사용하여 구현될 수 있습니다. CAN FD는 CANopen의 기본적인 CAN 프레임을 확장하여 더 큰 데이터를 빠르게 전송할 수 있는 방법입니다. CAN FD 프레임은 더 큰 데이터 트랜스포콜과 더 큰 데이터 크기를 지원하여, CANopen에서의 SDO (Service Data Object) 사용에 유용합니다.
CANopen 네트워크에서 PDO (Process Data Object)와 SDO (Service Data Object)는 데이터를 전송하는 두 가지 주요 메커니즘입니다. 각각의 프로토콜은 특정한 목적과 사용 사례에 맞게 설계되었습니다.
PDO (Process Data Object)
PDO는 실시간 데이터 전송에 최적화되어 있습니다. 이 프로토콜은 다음과 같은 특징을 가집니다:
- 고속 전송: PDO는 주로 실시간 제어 작업에 사용되며, 낮은 지연 시간과 빠른 데이터 전송이 필요한 경우에 적합합니다.
- 단일 프레임: 일반적으로 PDO는 하나의 CAN 프레임에 최대 8바이트의 데이터를 담아 전송합니다.
- 브로드캐스트 가능: PDO는 네트워크 상의 여러 노드에게 동시에 데이터를 전송할 수 있어, 여러 장치가 동일한 데이터를 거의 동시에 받을 수 있습니다.
- 사이클링 전송: PDO는 주기적으로 또는 특정 이벤트가 발생했을 때 자동으로 전송될 수 있습니다.
SDO (Service Data Object)
SDO는 더 복잡한 데이터 전송과 디바이스 구성에 사용됩니다. SDO의 특징은 다음과 같습니다
- 상세한 데이터 전송: SDO는 오브젝트 딕셔너리 내의 특정 항목에 대한 접근을 제공하며, 복잡한 데이터 구조나 대량의 데이터를 전송할 때 사용됩니다.
- 요청/응답 메커니즘: SDO 통신은 요청과 응답의 형태로 이루어집니다. 한 노드가 데이터를 요청하면, 다른 노드가 해당 데이터를 응답으로 보냅니다.
- 블록 전송: SDO는 블록 전송 모드를 지원하여, 한 번에 많은 양의 데이터를 전송할 수 있습니다.
- 비동기 통신: SDO는 주기적인 데이터 전송보다는 필요할 때마다 데이터를 전송하는 비동기 통신에 적합합니다.
예시
예를 들어, 모터 제어 시스템에서 토크 제어와 위치 제어를 위한 데이터를 전송해야 한다고 가정해 보겠습니다.
- 토크 제어: 실시간으로 모터의 토크를 조절해야 하므로, PDO를 사용하여 모터 드라이버에게 토크 값을 빠르게 전송할 수 있습니다.
- 위치 제어: 모터의 위치 설정 값이나 구성 파라미터와 같은 상세한 정보가 필요할 때는 SDO를 사용하여 필요한 데이터를 전송합니다.
이러한 방식으로, CANopen 네트워크는 다양한 제어 요구 사항과 데이터 전송 요구 사항을 효율적으로 처리할 수 있습니다.
CANopen에서의 NTM (Network Management) 동작원리와 설계 구조는 다음과 같습니다:
- NTM의 역할: CANopen에서 NTM은 장치들이 상태를 조절하고 관리하는 데 사용됩니다. 각 장치는 NTM 상태에서 자동으로 실행될 수 있으며, CANopen 장치 초기화와 같은 과정을 통해 NTM 상태를 변경할 수 있습니다.
- NTM 메시지 명령: NTM는 다음과 같은 메시지 명령을 사용하여 장치 상태를 관리합니다:
- Start remote node: 려모 노드를 시작합니다.
- Enter pre-operational: 장치가 전역적인 상태로 변경됩니다.
- Stop remote node: 려모 노드를 중지합니다.
- Reset node: 노드를 초기화합니다.
- Reset communication: 커뮤니케이션을 초기화합니다.
- SYNC 메시지: SYNC 메시지는 상위제어기에서 제공하여 연결된 노드에게 메시지를 전송합니다. 이는 시스템의 시간을 정확하게 관리하는 데 사용됩니다.
- OD Entry와 SDO: NTM는 OD Entry에 대한 접근제어 방식으로, 추가적인 정보와 인자를 포함하여 더 구체적인 데이터를 전송할 수 있습니다. SDO는 CANopen에서 사용되는 서버와 클라이언트 관계로 통신하며, 요청하는 명령의 ID와 예를 들어 Read/Write 등의 고유 ID가 있습니다.
- NTM의 구조: NTM의 구조는 다음과 같습니다:
- NTM master 메시지 명령: Master 노드가 명령을 발행합니다.
- NTM slave 메시지 명령: Slave 노드가 master 로부터 명령을 받아서 상태를 변화시킨다.
CANopen에서 NTM (Network Management) 상태를 자동으로 실행하는 방법은 다음과 같습니다:
- CANopen 장치 초기화: CANopen 장치 초기화를 통해 NTM 상태를 자동으로 실행합니다. 초기화 과정에서는 장치는 Pre-operational 상태로 설정됩니다1.
- NMT 메시지 명령: NTM 메시지 명령을 사용하여 장치 인가시 NTM 상태를 변경할 수 있습니다. 예를 들어, “Start remote node” 메시지 명령을 사용하여 노드를 Operational 상태로 설정하거나, “Reset node” 메시지 명령을 사용하여 노드를 Reset 상태로 설정할 수 있습니다1.
- SYNC 메시지: SYNC 메시지를 사용하여 장치 인가시 NTM 상태를 조절할 수 있습니다. SYNC 메시지는 장치 인가시에게 시간을 제공하여 다음의 작엄을 준비하거나 시작할 수 있도록 돕습니다1.
- NMT 프로토콜 구현: CANopen에서는 NMT 프로토콜을 구현하여 NTM 상태의 관리를 위한 다양한 기능을 제공합니다. 이 프로토콜은 장치 인가시에게 필요한 정보와 명령을 전송하여 NTM 상태를 관리합니다2.
CANopen에서 NTM (Network Management)와 관련된 OD (Object Dictionary) 엔트리에 대한 접근 방식을 CAN FD 프레임을 사용하여 구현 가능한 CAN 통신 칩셋에 대한 제조사와 그 특징은 다음과 같습니다:
- 제조사: CANtronics
- CANtronics는 CAN FD 프레임을 활용한 CAN 통신 칩셋을 제공합니다. 이 칩셋은 CAN FD의 높은 데이터 전송률과 크기를 이용하여 더 빠른 데이터 전송과 더 큰 데이터 필드를 지원합니다1.
- CANtronics의 칩셋은 CAN FD 프레임의 구조와 데이터 전송 방식에 대해 설명하고, CAN FD 프레임을 사용하여 CANopen에서 NTM와 관련된 OD 엔트리에 대한 접근 방식을 구현하기 위해 필요한 정보를 제공합니다1.
- 제조사: Microchip Technology
- 제조사: Bosch
개발과 자문 문의 부탁드립니다 ...
일인기업 딥네트워크 개발총괄 장석원
HP : 010-3350 6509
E-Mail : sayhi7@daum.net
'Kernel Porting > Linux' 카테고리의 다른 글
LLM 분석 및 개발 자문 일인기업 딥네트워크가 GPT-3.5 모델 설계 구조를 어디까지 어떻게 파악 성공했을까 ? 아래의 이메일 주소로 많은 LLM 개발 및 자문 문의 부탁드립니다 ...
2024. 5. 30. 00:56
Transformer 모델의 디코더는 인코딩된 벡터를 사용하여 요약문을 생성하는 복잡한 과정을 거칩니다. 학습과 추론 과정에서 디코더의 동작은 다음과 같이 다릅니다:
학습 과정에서: 디코더는 인코더로부터 전달된 인코딩된 벡터와 함께, 이전에 생성된 토큰들을 입력으로 받습니다. 이러한 입력은 디코더의 각 레이어를 통과하면서, 셀프 어텐션 메커니즘을 사용하여 토큰 간의 관계를 학습합니다. 셀프 어텐션은 각 토큰이 다른 모든 토큰과 어떻게 상호작용하는지를 결정하며, 이는 문맥을 이해하는 데 중요합니다. 학습 과정에서는 교사 강요(Teacher Forcing) 방식을 사용하여, 실제 정답 토큰을 다음 입력으로 제공함으로써 모델이 올바른 출력을 생성하도록 유도합니다. 손실 함수(예: 크로스 엔트로피 손실)를 통해 예측된 출력과 실제 정답 사이의 오차를 계산하고, 이를 최소화하기 위해 모델의 가중치를 업데이트합니다.
추론 과정에서: 학습된 모델을 사용하여 새로운 데이터에 대한 요약문을 생성할 때, 디코더는 이전에 생성된 토큰들을 입력으로 받아 다음 토큰을 예측합니다. 이 과정에서는 실제 정답이 없기 때문에, 모델은 이전에 생성된 자신의 출력을 다음 입력으로 사용합니다. 이를 자기 회귀적(Autoregressive) 방식이라고 합니다. 각 단계에서 모델은 확률이 가장 높은 토큰을 선택하거나, 빔 서치(Beam Search)와 같은 전략을 사용하여 더 나은 결과를 얻을 수 있습니다.
인코더와 디코더의 각 레이어는 멀티-헤드 어텐션과 포지션-와이즈 피드포워드 네트워크를 포함합니다. 이 구성 요소들은 모델이 입력 문장의 문맥을 이해하고, 적절한 요약문을 생성하는 데 필수적입니다. 학습과 추론 과정 모두에서, 포지셔널 인코딩은 각 토큰의 순서 정보를 모델에 제공하여, 문장의 시퀀스 정보를 유지합니다.
Transformer 모델은 문서 요약, 기계 번역, 자연어 이해 등 다양한 자연어 처리 작업에 효과적으로 사용됩니다. 각 작업의 특성에 맞게 모델의 구조와 하이퍼파라미터를 조정하여 최적의 성능을 달성할 수 있습니다.
NLP 평가 분야에서 BLEU 및 ROUGE 점수는 각각 기계 생성 번역 및 요약의 품질을 평가하는 데 일반적으로 사용되는 지표입니다. BLEU 점수는 주로 기계 번역 작업에 사용되지만 ROUGE 점수는 텍스트 요약 작업에 사용됩니다. 두 지표 모두 n-gram 중첩에 의존하여 기계 생성 출력과 참조 번역 또는 요약 간의 유사성을 측정합니다. NLP 모델을 평가하는 간단하고 효과적인 방법을 제공하지만 출력의 전반적인 의미, 유창성 및 일관성을 캡처하는 데 한계가 있습니다. NLP 평가에 사용하는 동안 작업의 특정 요구 사항과 이러한 메트릭의 제한 사항을 고려하는 것이 중요합니다.
결론적으로 BLEU 및 ROUGE 점수는 각각 기계 번역 및 텍스트 요약 작업에서 NLP 모델의 성능을 평가하는 데 유용한 도구입니다. 기계에서 생성된 출력과 참조 번역 또는 요약 간의 유사성을 정량적으로 측정하여 연구자와 실무자가 모델의 품질을 객관적으로 평가할 수 있도록 합니다.
RAG 모델은 두 개의 트랜스포머 모델을 사용하여 두 단계로 작동합니다. 이 두 단계는 각각 검색 단계와 프롬프트 템플릿 생성 단계입니다. 각 단계는 서로 다른 목적을 가지고 있으며, 각각의 트랜스포머 모델은 해당 단계에서 필요한 기능을 수행하기 위해 특별히 학습됩니다.
- 검색 단계: 첫 번째 트랜스포머 모델은 사용자의 질문을 분석하여 핵심 요소와 의미를 파악합니다. 이 모델은 UD 데이터셋을 통해 학습된 문장 구조와 의존 관계를 활용하여, 질문에서 중요한 ‘subject’, ‘object’ 등의 레이블을 식별합니다. 그런 다음, 이 정보를 사용하여 데이터베이스에서 관련 문서를 검색합니다.
- 프롬프트 템플릿 생성 단계: 두 번째 트랜스포머 모델은 검색된 문서와 사용자 질문 사이의 관계를 분석합니다. 이 모델은 ‘self-attention’ 메커니즘을 사용하여 문서 내의 각 단어와 질문 내의 각 단어 사이의 관련성을 평가하고, 가장 관련성 높은 정보를 추출합니다. 이 정보는 사용자 질문과 결합되어 새로운 프롬프트 템플릿을 형성합니다.
이 두 단계는 서로 연결되어 있으며, 각각의 트랜스포머 모델은 자신의 역할에 맞게 최적화되어 학습됩니다. 검색 단계에서 얻은 문서들은 프롬프트 템플릿 생성 단계로 전달되어, 최종적인 응답을 생성하는 데 사용됩니다. 이러한 방식으로 RAG 모델은 사용자 질문에 대한 정확하고 관련성 높은 응답을 생성할 수 있습니다.
LLM 분석 및 개발 자문관련 여러기업의 개발 및 자문 문의 아래의 이메일 주소로 많은 문의 부탁드립니다 ...
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
[ 장거리 저전력 로라 통신 분야 LoRA Device 단 / LoRa Gateway 단 펌웨어 개발 및 컨설팅 전문 ][로라 통신 Uplink Packet / Downlink Packet 을 암호키로 암복호화 해서 송수신하는 노하우 확보 성공]
2024. 5. 27. 09:16
개인사업자로 IT 분야 펌웨어 개발 등 개발용역 사업을 한지 약 10 년 입니다 ...
로라통신 디바이스단 / 게이트웨이단 프로토타입 펌웨어 개발 Semtech SX1276 으로 가능 합니다 ... 귀사 요구에 맞춰 최대한 시간을 맞춰서 프로토타입 개발 진행이 가능 합니다 ... Semtech 회사 사이트에서 SX1276 에서 다운로드 받은 펌웨어 세부 분석이 되있어서 최대한 빠른 기간내 펌웨어 개발 진행이 가능 합니다 ... 저는 지역이 수원 이고 맡겨 주시면 확실하게 결과물 내는것이 가능합니다 ...
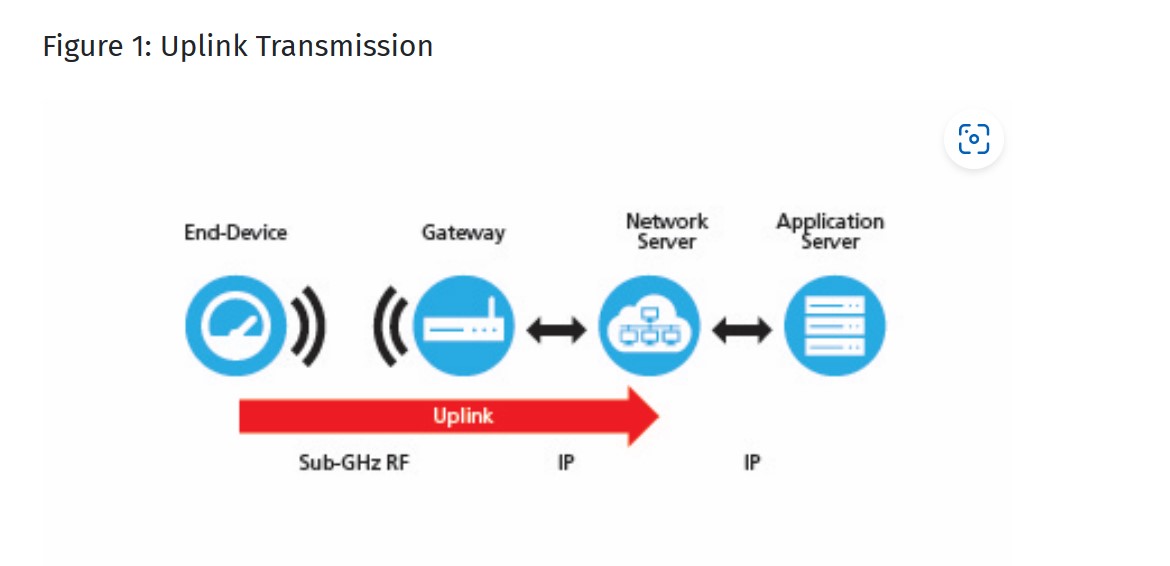
LoRA (Long Range)는 저전력 광역 네트워크 (LPWAN) 기술로, 장거리 통신과 저전력 소비를 가능하게 하는 무선통신 방식입니다. LoRA 시스템은 크게 네 부분으로 나뉩니다: 디바이스단, 게이트웨이단, 네트웍 서버단, 그리고 어플리케이션 서버단. 각 부분의 구현 기술에 대해 상세히 설명드리겠습니다.
디바이스단 (End Device): 디바이스단은 데이터를 수집하고 LoRA 네트워크에 전송하는 IoT 장치입니다. 이들은 주로 센서나 액추에이터로 구성되며, LoRA 모듈을 통해 무선 신호를 전송합니다. 디바이스단의 핵심 기술은 Chirp Spread Spectrum (CSS) 변조 방식을 사용하여 장애물이 많은 환경이나 장거리에서도 간섭을 최소화하면서 데이터를 전송하는 것입니다.
게이트웨이단 (Gateway): 게이트웨이는 디바이스단으로부터 신호를 수신하여 인터넷을 통해 네트웍 서버로 전달하는 역할을 합니다. 게이트웨이는 별 모양의 토폴로지를 형성하여 중앙 네트워크 서버와 백엔드의 최종 장치 간 메시지를 릴레이합니다. 게이트웨이는 일반적인 IP 연결을 사용하여 네트워크 서버에 연결되며, 다수의 디바이스단과 통신할 수 있습니다.
네트워크 서버단 (Network Server): 네트워크 서버는 게이트웨이로부터 받은 데이터를 처리하고, 필요에 따라 디바이스단에 명령을 전송합니다. 또한, 네트워크의 보안과 데이터 라우팅을 관리합니다. 네트워크 서버는 Adaptive Data Rate (ADR) 알고리즘을 통해 연결된 각 센서의 데이터 속도를 관리하여 최적화합니다.
어플리케이션 서버단 (Application Server): 어플리케이션 서버는 사용자가 데이터를 분석하고 관리할 수 있도록 사용자 인터페이스를 제공합니다. 이 서버는 네트워크 서버로부터 데이터를 받아 사용자가 이해할 수 있는 형태로 가공하며, 사용자의 명령을 네트워크 서버로 전송하여 디바이스단의 동작을 제어할 수 있습니다
LoRA 네트워크의 보안은 여러 계층에서 구현되며, 이는 데이터의 무결성과 기기의 인증을 보장하기 위해 설계되었습니다. 주요 보안 기능은 다음과 같습니다:
- 네트워크 세션 키 (Network Session Key): 이 키는 네트워크 서버와 디바이스 간의 통신을 암호화하여 네트워크 레벨의 보안을 제공합니다.
- 애플리케이션 세션 키 (Application Session Key): 이 키는 애플리케이션 서버와 디바이스 간의 통신을 암호화하여 애플리케이션 데이터의 보안을 담당합니다.
- 장치 주소 (Device Address): 각 LoRA 디바이스는 고유한 주소를 가지며, 이를 통해 네트워크는 디바이스를 식별하고 관리합니다.
- 메시지 무결성 코드 (MIC): 전송된 각 메시지에는 MIC가 포함되어 있어, 메시지가 변경되지 않았음을 확인하고, 메시지의 출처가 유효한 디바이스임을 보증합니다.
- 하드웨어 보안 모듈 (Hardware Security Module): 일부 LoRA 솔루션은 키 관리와 암호화 작업을 위해 하드웨어 보안 모듈을 사용합니다. 이는 물리적 해킹으로부터 키를 보호하고, 보안성을 높입니다.
이러한 보안 메커니즘은 LoRA 네트워크가 안전하게 운영될 수 있도록 하며, 다양한 IoT 환경에서의 신뢰성 있는 데이터 전송을 가능하게 합니다. 또한, LoRA Alliance에서 정의한 LoRaWAN 프로토콜은 이러한 보안 기능들을 표준화하여, 네트워크의 호환성과 보안을 강화하고 있습니다.
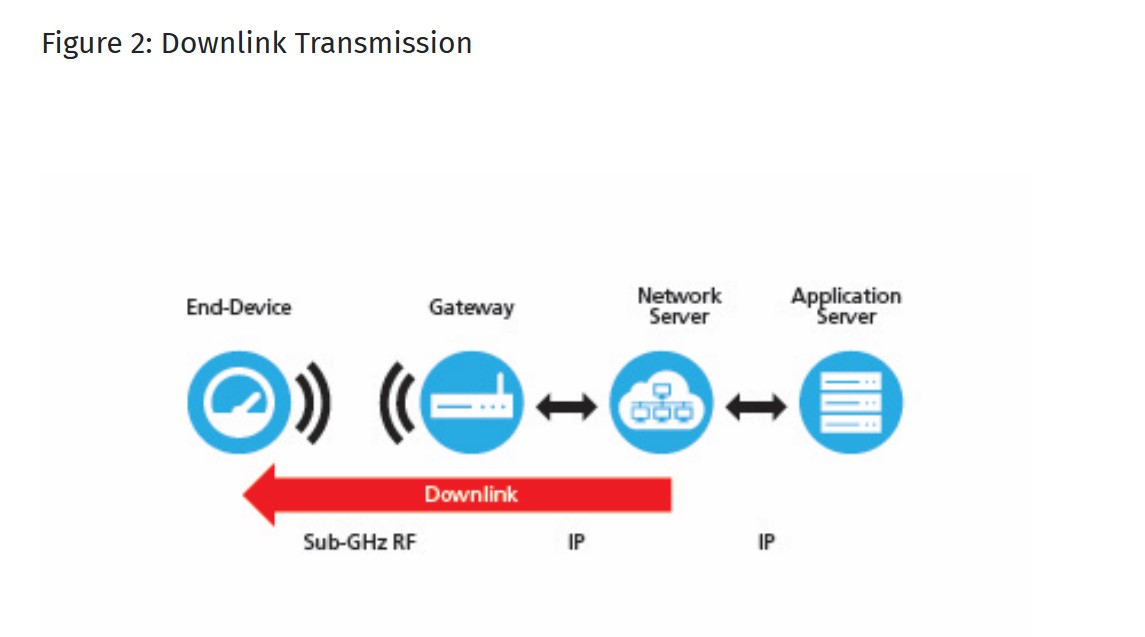
LoRa Gateway Uplink: radio packets 는 gateway 에 의해 수신된다 , 그리고 Gateway 에 의해 메터데이터가 더해지고 여기에 Gateway Status 정보가 더해져서 Network Server 로 forward 처리된다.
LoRa Gateway Downlink: Network Server 에 의해 패킷이 생성되고 , 부가적인 메터데이터를 포함될수 있고, 또한 Gateway 의 Configuration Data 도 포함되서 Gateway 의 Radio Channel 로 Transmit 된다
SemTech 사가 공개하는 디바이스단의 펌웨어 소스는 ClassA/B/C end-device 구현시 Periodically uplinks a frame 은 the Cayenne LPP protocol 을 사용한다. Cayenne Low Power Payload (LPP) 은 편리하고 쉬운 방안을 제공해서 LoRaWAN 같은 LPWAN networks 로 데이터를 Send 를 구현한다 ... Cayenne LPP 는 payload size restriction 이 있다 11 bytes 보다 적은 수 만 한번에 센서 데이터들을 LoRa 디바이스가 Send 하는것을 허용한다.
로라통신의 보안 메커니즘에서, MAC( Message Authentication Code )은 메시지의 위변조를 확인하기 위해 쓰이는 보안 기술 입니다. CMAC은 알고리즘과 모드 에 따라 AES CBC-MAC 메커니즘이 있구요 ... CMAC 도 마찬가지로 주된 기능은 사용자 인증(authentication)과 데이터 무결성(data integerity) 처리를 위한것 입니다 ... MAC 은 MAC 을 만들때 Block 함수를 사용하면 CMAC( Cipher-based Message Authentication Code )가 됩니다 ...
SX1301 칩셋을 사용하여 LoRa 게이트웨이에서의 주요 기능을 구현하는 방법을 이해하기 위해, 각 기능과 관련된 레지스터 설정을 상세히 설명하겠습니다. SX1301은 LoRaWAN 네트워크의 핵심 구성 요소로서, 디바이스와 네트워크 서버 간의 통신을 관리합니다.
LoRa 게이트웨이의 핵심 역할과 SX1301의 레지스터 설정
- 신호 수신 및 송신
- 역할: LoRa 디바이스로부터 신호를 수신하고, 네트워크 서버로 데이터를 송신합니다.
- 제어 레지스터: REG_OP_MODE, REG_PACONFIG, REG_RFLR_PADAC, REG_HOP_PERIOD
- 수신 모드 설정: REG_OP_MODE 레지스터에서 수신 모드를 설정합니다. 이 레지스터의 값에 따라 칩셋이 수신 모드로 작동하도록 설정할 수 있습니다.
- 송신 모드 설정: REG_OP_MODE 레지스터의 설정을 통해 송신 모드로 전환합니다.
- 주파수 설정: REG_FRF_MSB, REG_FRF_MID, REG_FRF_LSB 레지스터를 통해 주파수를 설정합니다. 이 레지스터들에 대해 원하는 주파수 값을 설정하여, 송신 및 수신 주파수를 조정합니다.
- 출력 전력 설정: REG_PACONFIG, REG_RFLR_PADAC 레지스터를 사용하여 송신 전력을 설정합니다.
- 프레임 복조 및 디코딩
- 역할: 수신된 LoRa 프레임을 복조하고 디코딩하여 네트워크 서버에 전달할 수 있는 데이터로 변환합니다.
- 제어 레지스터: REG_MODEM_CONFIG1, REG_MODEM_CONFIG2, REG_DETECTION_OPTIMIZE, REG_DETECTION_THRESHOLD
- 복조 방식 설정: REG_MODEM_CONFIG1 및 REG_MODEM_CONFIG2 레지스터를 통해 모듈레이션 방식, 대역폭, 코드율 등을 설정합니다.
- 프레임 검출 설정: REG_DETECTION_OPTIMIZE, REG_DETECTION_THRESHOLD 레지스터를 사용하여 패킷의 신호 검출 임계값을 조정합니다.
- 네트워크 서버와의 통신
- 역할: 수신한 데이터를 네트워크 서버에 전송하고, 네트워크 서버의 명령을 디바이스에 전달합니다.
- 제어 레지스터: REG_FIFO, REG_FIFO_ADDR_PTR, REG_FIFO_TX_BASE_ADDR
- 패킷 전송: REG_FIFO 레지스터를 통해 송신할 데이터 패킷을 FIFO에 쓰고, 송신 작업을 시작합니다.
- 패킷 수신: REG_FIFO 레지스터를 통해 수신된 패킷을 읽어들입니다. REG_FIFO_ADDR_PTR 레지스터를 사용하여 읽을 데이터의 위치를 지정합니다.
- 패킷 처리 및 필터링
- 역할: 수신된 패킷을 필터링하고, 오류가 있거나 불필요한 패킷을 제거합니다.
- 제어 레지스터: REG_PKT_SNR_VALUE, REG_PKT_RSSI_VALUE, REG_RX_NB_BYTES
- 패킷 필터링: REG_PKT_SNR_VALUE와 REG_PKT_RSSI_VALUE 레지스터를 통해 패킷의 신호 대 잡음비(SNR)와 수신 신호 세기(RSSI)를 모니터링하여 유효한 패킷을 필터링합니다.
- 패킷 길이 설정: REG_RX_NB_BYTES 레지스터를 통해 수신할 패킷의 길이를 설정합니다.
- 주파수 동기화 및 시간 동기화
- 역할: LoRa 디바이스와의 주파수 및 시간 동기화를 통해 정확한 데이터 전송 및 수신을 보장합니다.
- 제어 레지스터: REG_SYNC_WORD, REG_HOP_PERIOD
- 동기화 단어 설정: REG_SYNC_WORD 레지스터를 사용하여 동기화 단어를 설정합니다. 이 단어는 디바이스와의 통신에서 동기화를 보장합니다.
- 주파수 홉 설정: REG_HOP_PERIOD 레지스터를 통해 주파수 홉 주기를 설정하여 동기화의 정확성을 높입니다.
결론
SX1301 칩셋의 각 레지스터는 LoRa 게이트웨이의 핵심 기능을 구현하는 데 중요한 역할을 합니다. 신호 수신 및 송신, 프레임 복조 및 디코딩, 네트워크 서버와의 통신, 패킷 처리 및 필터링, 주파수 및 시간 동기화는 모두 이러한 레지스터 설정을 통해 효과적으로 수행됩니다. 이들 레지스터를 적절히 제어함으로써, 게이트웨이는 LoRaWAN 네트워크의 원활한 운영을 지원합니다.
LoRa 게이트웨이는 LoRa 패킷을 IP 패킷으로 변환하여 네트워크 서버로 전송하고, 네트워크 서버에서 받은 IP 패킷을 LoRa 패킷으로 변환하여 LoRa 디바이스로 전송합니다. 이 과정은 게이트웨이의 소프트웨어와 네트워크 구조에 의해 관리됩니다. 상세한 송수신 구조와 방식을 설명하겠습니다.
1. LoRa 패킷을 IP 패킷으로 변환하여 네트워크 서버로 전송하는 과정
구조와 방식
- LoRa 패킷 수신
- SX1301 역할: LoRa 디바이스에서 수신된 무선 신호를 디지털 데이터로 복조합니다.
- 레지스터: REG_FIFO, REG_FIFO_ADDR_PTR를 통해 수신된 패킷 데이터를 읽습니다.
- 패킷 처리
- 게이트웨이 애플리케이션 프로세서:
- 수신 데이터의 디코딩: SX1301에서 받은 데이터를 애플리케이션 프로세서가 해석합니다. 데이터는 LoRaWAN 프로토콜에 따라 포맷이 지정되어 있습니다.
- LoRaWAN 프레임 추출: 수신된 LoRa 프레임을 LoRaWAN의 MAC (Medium Access Control) 프레임으로 디코딩하여, 페이로드와 메타데이터(예: 디바이스 주소, 패킷 순서 등)를 추출합니다.
- 게이트웨이 애플리케이션 프로세서:
- IP 패킷 변환
- 게이트웨이 소프트웨어:
- LoRaWAN 데이터의 IP 패킷화: 디코딩된 LoRaWAN 데이터와 메타데이터를 IP 패킷으로 변환합니다. 이 과정에서는 LoRaWAN 프로토콜에서 IP 패킷 포맷으로 데이터를 변환하는 작업이 필요합니다. 일반적으로 MQTT, HTTP, UDP 등 IP 프로토콜을 사용하여 네트워크 서버와 통신합니다.
- 게이트웨이 소프트웨어:
- 네트워크 서버로 전송
- 전송 프로토콜:
- MQTT: LoRaWAN 게이트웨이는 MQTT 프로토콜을 사용하여 IP 패킷을 네트워크 서버로 전송합니다. MQTT는 메시지 브로커를 통해 IP 패킷을 전송하는 방식입니다.
- HTTP/HTTPS: HTTP API를 통해 IP 패킷을 POST 요청으로 전송합니다.
- UDP: UDP 패킷을 통해 IP 패킷을 전송합니다.
- 전송 프로토콜:
2. 네트워크 서버에서 받은 IP 패킷을 LoRa 패킷으로 변환하여 디바이스로 전송하는 과정
구조와 방식
- IP 패킷 수신
- 네트워크 서버 역할: IP 네트워크를 통해 LoRa 게이트웨이로 IP 패킷을 전달합니다.
- IP 패킷 처리
- 네트워크 서버 소프트웨어:
- IP 패킷 디코딩: 네트워크 서버는 IP 패킷에서 LoRaWAN 데이터와 메타데이터를 추출합니다. 이 데이터는 특정 디바이스로 전송될 메시지와 명령을 포함하고 있습니다.
- 네트워크 서버 소프트웨어:
- LoRa 패킷 변환
- 게이트웨이 소프트웨어:
- LoRaWAN 데이터 포맷: IP 패킷의 데이터를 LoRaWAN 프레임으로 변환합니다. 여기서는 LoRaWAN 프로토콜에 맞게 데이터 포맷을 재구성합니다.
- LoRa 프레임 인코딩: LoRaWAN 데이터와 메타데이터를 LoRa 패킷으로 인코딩하여 송신 준비를 합니다.
- 게이트웨이 소프트웨어:
- LoRa 패킷 전송
- SX1301 역할:
- 패킷 송신: REG_FIFO, REG_FIFO_ADDR_PTR, REG_FIFO_TX_BASE_ADDR 레지스터를 사용하여 LoRa 패킷을 FIFO 버퍼에 작성합니다. 이후, REG_OP_MODE 레지스터를 통해 송신 모드를 활성화하여 패킷을 송신합니다.
- 무선 송신: SX1301은 설정된 주파수와 송신 전력으로 패킷을 무선으로 전송합니다.
- SX1301 역할:
요약
- LoRa 패킷 → IP 패킷:
- SX1301: LoRa 신호를 디지털 데이터로 변환.
- 게이트웨이 애플리케이션 프로세서: 데이터 디코딩 및 IP 패킷화.
- 게이트웨이 소프트웨어: IP 패킷 전송 (MQTT, HTTP, UDP).
- IP 패킷 → LoRa 패킷:
- 네트워크 서버: IP 패킷을 디코딩.
- 게이트웨이 소프트웨어: LoRaWAN 데이터 포맷으로 변환.
- SX1301: LoRa 패킷 송신.
이와 같은 구조와 방식으로, LoRa 게이트웨이는 LoRa 디바이스와 네트워크 서버 간의 데이터 송수신을 원활하게 처리합니다.
일인기업 딥 네트워크 장석원
기업블로그 : https://videocodec.tistory.com/ 제 기업블로그 사이트도 자세히 살펴봐 주시구요 ....
이메일 : sayhi7@daum.net
HP : 010-3350 6509
'Kernel Porting > Linux' 카테고리의 다른 글
[LLM(거대 언어 모델) 딥러닝 개발 및 자문 전문 일인기업 딥네트워크][이 글을 살펴 보시고 저에게 딥러닝 개발 및 자문 일꺼리를 혹시라도 맡기실 기업이 있으시면 연락 주십시요 ....]
2024. 5. 15. 17:32
나이 60 인 제가 나의 그동안 거의 3 년반 딥러닝 해외논문 분석 및 딥러닝 소스 분석에 대해 애기해 보려 합니다 ... ChatGPT 의 경우도 특정 목적을 위해 GPT-3.0 을 파인튜닝한것인데 ... ChatGPT Service 의 경우도 한가지 목적(목표)만을 구현한 다음 서비스를 발표한것은 아닌것 같고, 사용자들에게 어필이 될만한 목적(목표)을 몇 가지 이상을 구현해 서비스하는것 같다 .... 나는 GPT-3.0 이 모델 구조를 공개하지 않았기 때문에 나는 처음 딥러닝을 접근하는 입장에서 GPT-3.0 으로 접근하는것 보다 구글 Transformer Language Model 로 접근하는것이 나의 공부(사업화) 목적에 더 적합하다고 판단했다 .... 내가 한 3 년 이상 공부해 보니 구글 트랜스포머 모델 구현도 모델 구현시 거기에 적용되는 알고리즘을 뭘 선택해서 구현할지도 상당히 중요한것 같다 ... 나는 구글 트랜스포머 모델의 동작 원리의 이해를 위해 논문도 보고 관련 소스도 보고 그랬다 .... 내가 한 3 년 공부하면서 느끼는건데 딥러닝은 딥러닝 학습 동작시 적용되는 수십 수백개의 알고리즘중 가장 핵심이 되는것은 정말 확실히 이해하는게 필수하고 생각한다 .... 이런 딥러닝의 기초가 덜 되 있으면 이것 저것 살피다 보면 아 이게 이런데서 이렇게 필요하구나를 느낄수 있어서다 .... 나는 현재 트랜스포머 모델도 어느 정도 다 파악이 되 있고 ChatGPT 동작원리를 공부하려니 RLHF 강화학습 부분도 깊이 있게 공부하지 않을수 없었다 .... 미국 글로벌 빅테크 기업인 페이스북(메타)는 AI 인프라 투자도 상당한것 같다 페이스북은 A100 GPU 를 16000 대를 데이터 센터에 클라우드 서비스를 구축하고 LLM 을 개발하는것 같다 ... 내가 요즘 관심을 가지고 살피는 논문이 QLoRA 논문이다 이 논문은 LLM 을 파인튜닝시 엔비디아 GPU 1 대(메모리 48 GB) 로 파인튜닝이 가능하다고 한다 ... 그래서 이 논문의 세부 구조 분석도 어느 정도되 있다 .... 요즘 LLM 의 경량화 구현이 큰 화두이다 ... Quantization / Pruning / 지식증류 기법 등도 관련 논문들 세세히 살피고 있구요 ... 나는 그동안 위와 같이 LLM 구현 관련 논문 분석 및 소스 분석을 해왔다 ... 여기서 가장 중요하다고 판단되는게 GPT-3 와 거의 유사한 성능을 낼수 있는 사전학습 모델 구현 기술려 확보라 판단되서 이것 분석 검토하는라 상당 기간 시간도 보냈었다 .... 이게 되야 100 점 짜리 서비스는 아니어도 특정 목적의 챗봇을 만들때 위의 설명과 같이 GPT-3 파인 튜닝을 위해서 QLoRA 논문의 세부 분석도 이런것 때문에 해놨던것 이구요 ... 나는 완벽하진 않아도 특정 목적 ChatBot 구현을 위한 세부 준비작업은 거의 다 되 있다 ... 내가 부족한 점 이라면 이런 ChatGPT 의 일부 기능으로 동작하는 챗봇 구현에 필요한 딥러닝 소스 한줄 한줄 커스토마이징이 나는 대기업 AI 연구소에서 실무 경험이 없다 보니 이들보다 시간이 좀 더 걸리는것 인데 요즘 한국 경제가 바닥이라 이렇게 나같이 준비가 이렇게 상당히 된 사람도 커스토마이징 시간이 더 걸린다고 하면 기업에서는 탐탁해하지 않는것 같아 무척 아쉽습니다 ... 이 글을 살펴 보시고 저에게 딥러닝 개발 및 자문 일꺼리를 혹시라도 맡기실 기업이 있으시면 연락 주십시요 ....
제가 파고있는 ChatGPT 관련 논문은 두가지 분야 입니다 ... 하나는 RLHF 논문관련이고 또 하나가 RAG 논문쪽 입니다 ... 저의 경우 현재 RLHF 동작원리나 설계 구조도 나름 심도있게 분석이 되있구요 ... ChatGPT 의 또 하나의 핵심 분야인 RAG 분야도 그 원리나 구조를 얼마나 깊게 파악했는가 하면 , 즉, 해당 딥러닝 모델을 어떤 구조와 방식으로 어떤식으로 세부적으로 설계해야 구현 가능한지도 세부 분석에 성공했읍니다 ... 이렇게 파악은 해 놨으니 AI 사업화 내지 기타 등등해서 기회가 온다면 제 꿈을 펼쳐볼수 있을것 같읍니다 ... ChatGPT 구현시 필수적으로 필요한 기술인 RAG 기술이 난이도도 있고 쉽지않은데 그동안 빡시게 검토분석을 해서 대략적으로 90 % 정도 구현에 필요한 노하우 확보에 성공해서 내 자신이 뿌듯하다 그리고 GPT-3.5 와 같은 모델을 학습시키려면 RLHF 기법이 중요하고 이중에서도 문장요약 하는 기능을 파인튜닝 하는것의 구현 기법도 상당히 중요한데 이런것들 한 90 % 가까이 확실하게 노하우가 파악되 있읍니다 ....
RAG(Retrieval-Augmented Generation) 기술과 RLHF(Reinforcement Learning from Human Feedback) 기술은 대규모 언어 모델(Large Language Models, LLMs)의 성능을 향상시키기 위해 사용되는 중요한 기법들입니다. ChatGPT-3.5와 같은 모델을 분석할 때, 이 두 기술은 다음과 같은 이유로 중요합니다:
RAG 기술은 기존의 지식 데이터베이스나 문서를 검색하여 언어 모델의 답변을 보강하는 방식입니다. 이를 통해 모델은 더 정확하고 상세한 정보를 제공할 수 있으며, 실시간으로 업데이트된 데이터에 접근할 수 있습니다. RAG는 다음과 같은 단계로 구성됩니다:
- Query Generation: 모델이 사용자의 질문에 기반하여 검색 쿼리를 생성합니다.
- Document Retrieval: 생성된 쿼리를 사용하여 관련 문서를 검색합니다.
- Answer Generation: 검색된 문서를 참조하여 답변을 생성합니다.
RLHF 기술은 인간의 피드백을 기반으로 모델의 예측을 조정하는 강화 학습 방법입니다. 이 기술은 모델이 사용자의 의도와 더 잘 일치하는 답변을 생성하도록 돕습니다. RLHF는 다음과 같은 단계로 구성됩니다:
- Supervised Fine-Tuning (SFT): 인간이 만든 레이블을 사용하여 모델을 미세 조정합니다.
- Reward Modeling: 인간 평가자가 생성된 답변을 평가하여 보상 모델을 학습합니다.
- Reinforcement Learning: 보상 모델을 사용하여 모델의 예측을 최적화합니다.
RAG와 RLHF를 공부할 때, 다음과 같은 점에 주의를 기울여야 합니다:
- 데이터의 질과 양: RAG는 정확한 문서 검색을 위해 고품질의 데이터가 필요하며, RLHF는 인간의 피드백을 정확하게 반영할 수 있는 충분한 양의 데이터가 필요합니다.
- 모델의 일반화 능력: RAG는 모델이 다양한 주제에 대해 답변할 수 있도록 돕지만, 너무 특정한 데이터에 의존할 경우 일반화 능력이 떨어질 수 있습니다. RLHF는 모델이 사용자의 의도를 더 잘 이해하도록 돕지만, 과도한 튜닝은 모델의 유연성을 저하시킬 수 있습니다.
- 성능과 효율성: RAG와 RLHF 모두 모델의 성능을 향상시키지만, 계산 비용과 시간이 많이 들 수 있으므로 효율적인 구현이 중요합니다.
이러한 기술들을 공부하고 적용함으로써, LLMs의 성능을 향상시키고 사용자 경험을 개선할 수 있습니다. 또한, 이 기술들은 모델이 더 정확하고 신뢰할 수 있는 정보를 제공하도록 도와줍니다. 각 기술의 원리와 적용 방법을 깊이 이해하고, 실제 데이터와 상황에 적용해보면서 학습하는 것이 중요합니다.
저는 ChatGPT 같은 챗봇 구현(논문 분석 및 소스 구현)에 필요한 RLHF 설계 기법과 RAG 설계기법을 약 90 % 를 확실히 파악하고 있읍니다 ...
딥네트워크는 Vision Transformer를 OCR 에 적용하기 위해, 두 가지 방법을 제안하였습니다. 첫 번째 방법은 Vision Transformer를 문자 검출과 인식을 동시에 수행하는 엔드-투-엔드 모델로 사용하는 것입니다. 이 방법은 이미지를 패치들로 나누고, 각 패치에 대해 문자의 존재 여부와 클래스를 예측하는 방식입니다. 이 방법은 별도의 문자 분할 과정이 필요 없으며, 다양한 크기와 방향의 문자에도 적응할 수 있습니다. 두 번째 방법은 Vision Transformer를 문자 검출과 인식을 각각 수행하는 두 단계 모델로 사용하는 것입니다. 이 방법은 첫 번째 단계에서 Vision Transformer를 이용하여 문자 영역을 검출하고, 두 번째 단계에서 Vision Transformer를 이용하여 검출된 영역의 문자를 인식하는 방식입니다. 이 방법은 문자 영역의 정확도와 문자 인식의 정확도를 각각 향상시킬 수 있습니다.
요즘 GPT-4o 같은 경우 광학문자인식(OCR) 기능 구현이 되서 성능이 제대로 나오는것 같은데 .... 저는 광학문자인식(OCR) 기능 구현 관련해서도 이것의 구현도 거의 90 % 준비가 되있읍니다 ... 광학문자 인식의 정확도를 높이려면 학습데이터 구축에 꽤 많은 자금 투입이 필요하고요 ... 어재뜬 저는 광학문자인식 모델 구조라든가 학습원리를 확실히 파악하는데 성공했읍니다 ...
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
[일인기업 딥네트워크 딥러닝 LLM 구현 기술력 소개][구글 트랜스포머 LLM 모델 구현 개발 과 텐서플로우 개발환경 구축]
2024. 5. 15. 10:46
TensorFlow를 사용하여 GPU 지원이 포함된 개발 환경을 설정하는 것은 복잡한 과정일 수 있습니다. 여기에는 여러 단계가 포함되며, 각 단계는 주의 깊게 수행되어야 합니다. 다음은 제가 파악하고 있는 Ubuntu Linux에서 Nvidia A100 GPUs를 사용하여 TensorFlow 개발 환경을 설정하는 방법 소개 입니다.
1. 시스템 요구 사항 확인
- Ubuntu Linux 운영 체제가 설치되어 있는지 확인합니다.
- Nvidia A100 GPUs가 시스템에 설치되어 있고 정상적으로 인식되는지 확인합니다.
2. NVIDIA 드라이버 설치
- Nvidia 웹사이트에서 A100 GPU에 맞는 최신 NVIDIA 드라이버를 다운로드합니다.
- 다운로드한 드라이버를 설치하기 전에, 현재 설치된 드라이버를 제거합니다.3. CUDA Toolkit 설치
- CUDA Toolkit은 GPU에서 병렬 처리를 가능하게 하는 Nvidia의 개발 환경입니다.
3. CUDA Toolkit 설치
- CUDA Toolkit은 GPU에서 병렬 처리를 가능하게 하는 Nvidia의 개발 환경입니다.
4. cuDNN 설치
- cuDNN은 CUDA 위에서 동작하는 딥 러닝 라이브러리로, TensorFlow에서 GPU 가속을 사용하기 위해 필요합니다.
- Nvidia 웹사이트에서 cuDNN을 다운로드하고 설치합니다.
5. Python 및 필수 패키지 설치
- Python과 pip를 설치합니다.
6. TensorFlow 설치 확인
- TensorFlow가 올바르게 설치되었는지 확인합니다.
7. 추가 설정
- 필요에 따라 TensorFlow의 성능을 최적화하기 위한 추가 설정을 수행할 수 있습니다.
- 예를 들어, tf.config.experimental.set_memory_growth를 사용하여 메모리 사용량을 관리할 수 있습니다.
이러한 단계를 통해 TensorFlow와 GPU 지원이 포함된 개발 환경을 성공적으로 설정할 수 있습니다.
LLM 의 분산학습 이슈에 대한 개발환경 구축시 Docker 라는 컨테이너 설계 이슈 개념을 사용하여 각각의 소프트웨어 개발 환경을 분리해 LLM 개발환경을 구축하는게 그 핵심이라 저는 판단합니다. 컨테이너는 격리된 환경에서 실행되는 프로세스로, 각 컨테이너는 독립적인 파일 시스템, 네트워크, 그리고 실행 공간을 가지게 됩니다. 이렇게 되면 하나의 서버 PC에서도 여러 개의 다른 소프트웨어 개발 환경을 독립적으로 운용할 수 있게 됩니다 내가 LLM 분산 개발 환경을 이야기시 Docker 로 텐서플로우 컨테이너를 격리된 환경에서 개발자가 개발하수 있도록 그 환경을 다음과 같이 지원해 줍니다 그래서 왜 이게 중요하냐 하면 다음과 같읍니다 ... GPU를 지원하는 텐서플로우를 사용하기 위해 필요한 NVIDIA 드라이버만 있으면 된다는 것은 Docker가 GPU를 사용하는 텐서플로우 이미지를 제공하기 때문입니다. 이 이미지에는 텐서플로우와 그 버전에 맞는 CUDA 환경이 이미 갖추어져 있습니다. 즉, 도커에는 텐서플로우와 CUDA 툴킷이 설치되어 있고, 호스트에는 NVIDIA 드라이버만 있으면 GPU를 사용할 수 있습니다. 이렇게 하면 CUDA 툴킷을 설치하거나 버전을 맞추는 번거로움을 피할 수 있습니다. 나도 분산 학습 관련 Docker 로 컨테이너를 분리된 환경에서 구축할수 있는데 이것 관련 모든게 준비된거는 아니지만 그 핵심 포인트는 거의 파악하고 있읍니다 ...
텐서플로우 이미지, NVIDIA 드라이버, 그리고 CUDA 환경이 함께 작동하는 방식을 이해하기 위해서는 각각의 역할과 그들이 어떻게 상호작용하는지를 알아야 합니다.
1. 텐서플로우 이미지: 텐서플로우 이미지는 Docker가 제공하는 것으로, 텐서플로우와 그에 맞는 CUDA 환경이 이미 설정되어 있습니다. 이 이미지는 텐서플로우 애플리케이션을 실행하는 데 필요한 모든 소프트웨어 구성 요소와 라이브러리를 포함하고 있습니다. 이를 통해 사용자는 복잡한 설정 과정 없이 바로 텐서플로우를 사용할 수 있습니다.
2. NVIDIA 드라이버: NVIDIA 드라이버는 호스트 시스템에 설치되며, GPU 하드웨어와 운영 체제 사이에서 중개자 역할을 합니다. 드라이버는 운영 체제나 애플리케이션에서 GPU에 대한 요청을 받아, 해당 요청을 GPU가 이해할 수 있는 명령어로 변환합니다. 따라서, NVIDIA 드라이버는 텐서플로우가 GPU를 사용할 수 있게 하는 핵심 요소입니다.
3. CUDA 환경: CUDA는 NVIDIA가 개발한 병렬 컴퓨팅 플랫폼 및 API 세트입니다. CUDA는 GPU의 계산 능력을 활용하여 고성능의 병렬 계산을 가능하게 합니다. 텐서플로우 이미지 내에는 CUDA 툴킷이 포함되어 있으며, 이는 GPU를 활용한 텐서플로우의 연산을 지원합니다.
이 세 가지 요소가 함께 작동함으로써 Docker가 Linux에서 GPU를 지원하는 텐서플로우를 사용할 수 있습니다. 텐서플로우 이미지는 필요한 모든 소프트웨어와 라이브러리를 제공하며, NVIDIA 드라이버는 이러한 소프트웨어가 GPU 하드웨어와 통신할 수 있게 해줍니다. 마지막으로, CUDA 환경은 GPU의 병렬 처리 능력을 활용하여 텐서플로우의 연산을 가속화합니다. 이 세 가지 요소가 모두 동작해야만 Docker가 Linux에서 GPU를 지원하는 텐서플로우를 사용할 수 있는 이유는, 이들이 서로 상호작용하며 텐서플로우의 GPU 가속 연산을 가능하게 하기 때문입니다.
제가 파악하고 있는 구글의 TensorFlow 환경에서 Transformer 라이브러리를 사용하는 방법과 TensorFlow API의 인자 설정에 대해 설명드리겠습니다. 또한, 효율적인 파이썬 TensorFlow 개발 방법에 대한 핵심 사항들을 5 가지로 정리하여 설명하겠습니다.
TensorFlow API와 Transformer 라이브러리 설정
TensorFlow에서 Transformer 모델을 사용하기 위해서는 먼저 TensorFlow 라이브러리를 설치하고, 필요한 Transformer 라이브러리를 설치해야 합니다. 이후, 모델을 구성하고 훈련시키기 위한 API 함수와 인자들을 설정합니다.
- 라이브러리 설치: TensorFlow와 필요한 Transformer 라이브러리를 설치합니다
- 모델 설정: Transformer 라이브러리에서 제공하는 사전 훈련된 모델을 불러오고, 모델의 구성을 설정합니다
- 인자 설정: 모델을 컴파일할 때 최적화 함수, 손실 함수, 평가 지표 등을 설정합니다.
- 훈련 및 평가: 모델을 훈련 데이터로 학습시키고, 테스트 데이터로 평가합니다
- 하이퍼파라미터 조정: 모델의 성능을 최적화하기 위해 배치 크기, 학습률, 에폭 수 등의 하이퍼파라미터를 조정합니다.
제가 파악하는 효율적인 TensorFlow 개발을 위한 5가지 핵심 사항
-
- 모델 구조 이해: 사용하는 모델의 구조를 이해하고, 문제에 맞게 모델을 조정하거나 커스터마이징하는 것이 중요합니다.
- 하이퍼파라미터 튜닝: 모델의 성능을 최적화하기 위해 하이퍼파라미터를 실험적으로 조정해야 합니다.
- 성능 평가: 다양한 평가 지표를 사용하여 모델의 성능을 정확하게 평가하고, 필요한 경우 모델을 개선합니다.
- 코드 최적화: 효율적인 코드 작성과 리소스 관리를 통해 학습 시간을 단축하고, 메모리 사용을 최적화합니다.
- 데이터 전처리: 데이터를 모델에 적합한 형태로 전처리하는 것이 중요합니다. 이는 데이터의 품질과 모델의 성능에 직접적인 영향을 미칩니다.
- 이러한 과정을 통해 TensorFlow 환경에서 Transformer 라이브러리를 사용하여 딥러닝 모델을 효과적으로 구현하고 최적화할 수 있습니다. 각 단계에서 세부적인 설정은 프로젝트의 요구사항과 데이터에 따라 달라질 수 있으며, 실험을 통해 가장 적합한 설정을 찾아야 합니다.
제가 파악하고 있는 텐서플로우 환경 구축과 트랜스포머 라이브러리 사용에 대한 핵심 요소를 세 가지로 정리해 드리겠습니다.
1. 텐서플로우 환경 구축의 핵심 요소:
- 호환성 확인: 사용하고자 하는 TensorFlow 버전과 컴퓨터 및 GPU 사양의 호환성을 확인합니다.
- 필수 구성 요소 설치: Python, Anaconda, CUDA Toolkit, cuDNN 등 필요한 소프트웨어와 라이브러리를 설치합니다.
- 가상 환경 설정: Anaconda를 사용하여 TensorFlow가 설치될 독립적인 가상 환경을 구축합니다.
2. 트랜스포머 라이브러리 수정 및 사용:
- 사전학습된 모델 사용: Hugging Face의 Transformers 라이브러리에서 사전학습된 모델을 불러와 사용합니다.
- 커스텀 모델 생성: 필요에 따라 Keras의 functional API를 사용하여 사전학습된 모델을 수정하고 새로운 레이어를 추가하여 커스텀 모델을 생성합니다.
- 파인튜닝: 사전학습된 모델을 특정 작업에 맞게 파인튜닝하여 성능을 최적화합니다.
3. API 함수 및 인자 설정:
- 인자 이해: 트랜스포머 라이브러리의 API 함수와 인자들을 이해하고, 각 인자가 모델의 동작에 어떤 영향을 미치는지 파악합니다.
- 하이퍼파라미터 조정: 모델의 성능에 중요한 영향을 미치는 하이퍼파라미터를 실험을 통해 조정합니다.
- 효율적인 학습: 배치 크기, 학습률, 에포크 수 등의 학습 파라미터를 설정하여 효율적인 학습을 진행합니다.
이러한 핵심 요소들을 기반으로 TensorFlow 환경을 구축하고, 트랜스포머 라이브러리를 효과적으로 사용하여 딥러닝 모델을 개발할 수 있습니다. 또한, 모델의 성능을 최적화하기 위해 지속적인 실험과 조정이 필요합니다.
- 도커를 이용한 텐서플로우 개발환경 설정
- 딥네트워크는 도커를 이용하여 텐서플로우 개발환경을 설정하는 노하우를 보유하고 있습니다. 도커는 컨테이너 기반의 오픈소스 가상화 플랫폼으로, 개발 환경을 코드로 관리하고 공유할 수 있어 효율적인 개발이 가능합니다. 이를 통해 개발자들은 복잡한 환경 설정 과정 없이 즉시 개발에 착수할 수 있습니다.
- 텐서플로우에서의 토큰나이저 및 토큰 임베딩 구현
- 우리는 텐서플로우 환경에서 효과적인 토큰나이저와 토큰 임베딩을 구현하는 방법을 알고 있습니다. 토큰나이저는 텍스트를 모델이 이해할 수 있는 토큰으로 분리하는 역할을 하며, 토큰 임베딩은 이러한 토큰을 고차원 벡터로 변환하여 모델에 입력하는 역할을 합니다. 이를 통해 텍스트 데이터를 모델이 이해할 수 있는 형태로 변환하는 데 필요한 전처리 작업을 수행합니다.
- 트랜스포머 모델 세부 구현
- 트랜스포머 모델의 주요 구성 요소인 셀프 어텐션, 스케일 닷 어텐션, 피드포워드 네트워크, 레이어 정규화 등을 세부적으로 구현하는 능력을 보유하고 있습니다. 셀프 어텐션은 입력 시퀀스의 각 토큰이 다른 토큰과 얼마나 관련이 있는지를 계산하며, 스케일 닷 어텐션은 셀프 어텐션의 결과를 스케일링하여 안정적인 학습을 돕습니다. 피드포워드 네트워크는 각 토큰에 대한 비선형 변환을 수행하며, 레이어 정규화는 각 레이어의 출력을 정규화하여 학습을 안정화합니다.
- 학습 처리 노하우
- 우리는 트랜스포머 모델의 학습 과정에서 발생하는 다양한 문제를 해결하는 노하우를 보유하고 있습니다. 이에는 Forward 학습 처리와 Backward 학습 처리가 포함되어 있습니다. Forward 학습 처리는 모델의 입력에서 출력까지의 전파 과정을, Backward 학습 처리는 출력에서 입력까지의 그래디언트 전파 과정을 의미합니다.
- NSP 예측 구현
- 딥네트워크는 트랜스포머 모델을 이용하여 Next Sentence Prediction (NSP)을 구현하는 능력을 보유하고 있습니다. NSP는 두 문장이 연속적인지 아닌지를 예측하는 작업으로, 문장 간의 관계를 파악하는 데 사용됩니다.
- 최적의 하이퍼파라미터 설정
- 모델 학습 시 필요한 각종 하이퍼파라미터의 최적값을 설정하는 방법을 알고 있습니다. 하이퍼파라미터는 학습률, 배치 크기, 에폭 수 등을 포함하며, 이들의 적절한 설정은 모델의 성능을 최대한 높이고, 학습 시간을 최소화하는 데 도움이 됩니다.
제가 파악하고 있는 LLM 관련 여러 논문중 그중 맛뵈기로 소개가 가능한 딥네트워크의 LLM 파인튜닝 방안에 대한 논문중 가장 관심을 갖고 세세히 분석 검토한 논문이 QLoRA 모델 논문 입니다 ...
QLoRA 모델은 저비트 어댑터를 사용하여 트랜스포머 기반 거대언어모델(LLM)의 가중치를 효율적으로 업데이트합니다. 이 접근 방식은 특히 GPT-3와 같은 모델에서 1750억 개의 가중치 값에 대한 그래디언트 역전파를 최적화하기 위해 설계되었습니다.
QLoRA의 저비트 어댑터는 다음과 같은 구조로 설계되었습니다:
- 4비트 정규분포 가중치(NF4): QLoRA는 4비트로 양자화된 가중치를 사용하여 메모리 사용량을 줄이고, 정규분포된 가중치에 대해 정보 이론적으로 최적화된 새로운 데이터 타입인 NF4를 도입합니다.
- 더블 양자화(Double Quantization): 양자화 상수를 또 다시 양자화하여 평균 메모리 사용량을 줄입니다.
- 페이징 최적화자(Paged Optimizers): 메모리 스파이크를 관리하고, 메모리 사용량을 추가로 줄이기 위해 도입되었습니다.
GPT-3 모델의 경우, QLoRA는 다음과 같이 그래디언트 역전파를 수행합니다:
- 로우 랭크 어댑터(Low Rank Adapters, LoRA): QLoRA는 양자화된 사전학습된 언어모델을 통해 그래디언트를 역전파하여 LoRA로 전달합니다. 이는 모델의 파라미터를 업데이트하는 동안 메모리 사용량을 줄이는 데 기여합니다.
- 그래디언트 역전파 하이웨이: E3VA(Efficient Visual Adapter) 튜닝 방법론에서 영감을 받아, 어댑터 전용의 명확한 그래디언트 역전파 경로를 제공합니다. 이 경로를 통해 어댑터의 모든 학습 가능한 파라미터가 역전파됩니다.
GPT-3 모델의 경우, 1750억 개의 가중치 값 각각에 대한 그래디언트 역전파는 LoRA 어댑터를 통해 수행됩니다. 이는 모델의 전체 가중치를 업데이트하는 대신, 학습 가능한 어댑터의 파라미터만을 업데이트하여, 전체 모델의 파라미터 수에 비해 상대적으로 적은 수의 파라미터를 효율적으로 학습할 수 있도록 합니다. 이 방식은 메모리 사용량을 크게 줄이면서도 모델의 성능을 유지할 수 있게 해줍니다.
RAG(Retrieval-Augmented Generation) 기술과 RLHF(Reinforcement Learning from Human Feedback) 기술은 대규모 언어 모델(Large Language Models, LLMs)의 성능을 향상시키기 위해 사용되는 중요한 기법들입니다. ChatGPT-3.5와 같은 모델을 분석할 때, 이 두 기술은 다음과 같은 이유로 중요합니다:
RAG 기술은 기존의 지식 데이터베이스나 문서를 검색하여 언어 모델의 답변을 보강하는 방식입니다. 이를 통해 모델은 더 정확하고 상세한 정보를 제공할 수 있으며, 실시간으로 업데이트된 데이터에 접근할 수 있습니다. RAG는 다음과 같은 단계로 구성됩니다:
- Query Generation: 모델이 사용자의 질문에 기반하여 검색 쿼리를 생성합니다.
- Document Retrieval: 생성된 쿼리를 사용하여 관련 문서를 검색합니다.
- Answer Generation: 검색된 문서를 참조하여 답변을 생성합니다.
RLHF 기술은 인간의 피드백을 기반으로 모델의 예측을 조정하는 강화 학습 방법입니다. 이 기술은 모델이 사용자의 의도와 더 잘 일치하는 답변을 생성하도록 돕습니다. RLHF는 다음과 같은 단계로 구성됩니다:
- Supervised Fine-Tuning (SFT): 인간이 만든 레이블을 사용하여 모델을 미세 조정합니다.
- Reward Modeling: 인간 평가자가 생성된 답변을 평가하여 보상 모델을 학습합니다.
- Reinforcement Learning: 보상 모델을 사용하여 모델의 예측을 최적화합니다.
RAG와 RLHF를 공부할 때, 다음과 같은 점에 주의를 기울여야 합니다:
- 데이터의 질과 양: RAG는 정확한 문서 검색을 위해 고품질의 데이터가 필요하며, RLHF는 인간의 피드백을 정확하게 반영할 수 있는 충분한 양의 데이터가 필요합니다.
- 모델의 일반화 능력: RAG는 모델이 다양한 주제에 대해 답변할 수 있도록 돕지만, 너무 특정한 데이터에 의존할 경우 일반화 능력이 떨어질 수 있습니다. RLHF는 모델이 사용자의 의도를 더 잘 이해하도록 돕지만, 과도한 튜닝은 모델의 유연성을 저하시킬 수 있습니다.
- 성능과 효율성: RAG와 RLHF 모두 모델의 성능을 향상시키지만, 계산 비용과 시간이 많이 들 수 있으므로 효율적인 구현이 중요합니다.
이러한 기술들을 공부하고 적용함으로써, LLMs의 성능을 향상시키고 사용자 경험을 개선할 수 있습니다. 또한, 이 기술들은 모델이 더 정확하고 신뢰할 수 있는 정보를 제공하도록 도와줍니다. 각 기술의 원리와 적용 방법을 깊이 이해하고, 실제 데이터와 상황에 적용해보면서 학습하는 것이 중요합니다.
저는 ChatGPT 같은 챗봇 구현(논문 분석 및 소스 구현)에 필요한 RLHF 설계 기법과 RAG 설계기법을 약 90 % 를 확실히 파악하고 있읍니다 ...
나이 60 인 제가 나의 그동안 거의 3 년반 딥러닝 해외논문 분석 및 딥러닝 소스 분석에 대해 애기해 보려 합니다 ... ChatGPT 의 경우도 특정 목적을 위해 GPT-3.0 을 파인튜닝한것인데 ... ChatGPT Service 의 경우도 한가지 목적(목표)만을 구현한 다음 서비스를 발표한것은 아닌것 같고, 사용자들에게 어필이 될만한 목적(목표)을 몇 가지 이상을 구현해 서비스하는것 같다 .... 나는 GPT-3.0 이 모델 구조를 공개하지 않았기 때문에 나는 처음 딥러닝을 접근하는 입장에서 GPT-3.0 으로 접근하는것 보다 구글 Transformer Language Model 로 접근하는것이 나의 공부(사업화) 목적에 더 적합하다고 판단했다 .... 내가 한 3 년 이상 공부해 보니 구글 트랜스포머 모델 구현도 모델 구현시 거기에 적용되는 알고리즘을 뭘 선택해서 구현할지도 상당히 중요한것 같다 ... 나는 구글 트랜스포머 모델의 동작 원리의 이해를 위해 논문도 보고 관련 소스도 보고 그랬다 .... 내가 한 3 년 공부하면서 느끼는건데 딥러닝은 딥러닝 학습 동작시 적용되는 수십 수백개의 알고리즘중 가장 핵심이 되는것은 정말 확실히 이해하는게 필수하고 생각한다 .... 이런 딥러닝의 기초가 덜 되 있으면 이것 저것 살피다 보면 아 이게 이런데서 이렇게 필요하구나를 느낄수 있어서다 .... 나는 현재 트랜스포머 모델도 어느 정도 다 파악이 되 있고 ChatGPT 동작원리를 공부하려니 RLHF 강화학습 부분도 깊이 있게 공부하지 않을수 없었다 .... 미국 글로벌 빅테크 기업인 페이스북(메타)는 AI 인프라 투자도 상당한것 같다 페이스북은 A100 GPU 를 16000 대를 데이터 센터에 클라우드 서비스를 구축하고 LLM 을 개발하는것 같다 ... 내가 요즘 관심을 가지고 살피는 논문이 QLoRA 논문이다 이 논문은 LLM 을 파인튜닝시 엔비디아 GPU 1 대(메모리 48 GB) 로 파인튜닝이 가능하다고 한다 ... 그래서 이 논문의 세부 구조 분석도 어느 정도되 있다 .... 요즘 LLM 의 경량화 구현이 큰 화두이다 ... Quantization / Pruning / 지식증류 기법 등도 관련 논문들 세세히 살피고 있구요 ... 나는 그동안 위와 같이 LLM 구현 관련 논문 분석 및 소스 분석을 해왔다 ... 여기서 가장 중요하다고 판단되는게 GPT-3 와 거의 유사한 성능을 낼수 있는 사전학습 모델 구현 기술려 확보라 판단되서 이것 분석 검토하는라 상당 기간 시간도 보냈었다 .... 이게 되야 100 점 짜리 서비스는 아니어도 특정 목적의 챗봇을 만들때 위의 설명과 같이 GPT-3 파인 튜닝을 위해서 QLoRA 논문의 세부 분석도 이런것 때문에 해놨던것 이구요 ... 나는 완벽하진 않아도 특정 목적 ChatBot 구현을 위한 세부 준비작업은 거의 다 되 있다 ... 내가 부족한 점 이라면 이런 ChatGPT 의 일부 기능으로 동작하는 챗봇 구현에 필요한 딥러닝 소스 한줄 한줄 커스토마이징이 나는 대기업 AI 연구소에서 실무 경험이 없다 보니 이들보다 시간이 좀 더 걸리는것 인데 요즘 한국 경제가 바닥이라 이렇게 나같이 준비가 이렇게 상당히 된 사람도 커스토마이징 시간이 더 걸린다고 하면 기업에서는 탐탁해하지 않는것 같아 무척 아쉽습니다 ... 이 글을 살펴 보시고 저에게 딥러닝 개발 및 자문 일꺼리를 혹시라도 맡기실 기업이 있으시면 연락 주십시요 ....
제가 파고있는 ChatGPT 관련 논문은 두가지 분야 입니다 ... 하나는 RLHF 논문관련이고 또 하나가 RAG 논문쪽 입니다 ... 저의 경우 현재 RLHF 동작원리나 설계 구조도 나름 심도있게 분석이 되있구요 ... ChatGPT 의 또 하나의 핵심 분야인 RAG 분야도 그 원리나 구조를 얼마나 깊게 파악했는가 하면 , 즉, 해당 딥러닝 모델을 어떤 구조와 방식으로 어떤식으로 세부적으로 설계해야 구현 가능한지도 세부 분석에 성공했읍니다 ... 이렇게 파악은 해 놨으니 AI 사업화 내지 기타 등등해서 기회가 온다면 제 꿈을 펼쳐볼수 있을것 같읍니다 ... ChatGPT 구현시 필수적으로 필요한 기술인 RAG 기술이 난이도도 있고 쉽지않은데 그동안 빡시게 검토분석을 해서 대략적으로 90 % 정도 구현에 필요한 노하우 확보에 성공해서 내 자신이 뿌듯하다 그리고 GPT-3.5 와 같은 모델을 학습시키려면 RLHF 기법이 중요하고 이중에서도 문장요약 하는 기능을 파인튜닝 하는것의 구현 기법도 상당히 중요한데 이런것들 한 90 % 가까이 확실하게 노하우가 파악되 있읍니다 ....
딥네트워크는 Vision Transformer를 OCR 에 적용하기 위해, 두 가지 방법을 제안하였습니다. 첫 번째 방법은 Vision Transformer를 문자 검출과 인식을 동시에 수행하는 엔드-투-엔드 모델로 사용하는 것입니다. 이 방법은 이미지를 패치들로 나누고, 각 패치에 대해 문자의 존재 여부와 클래스를 예측하는 방식입니다. 이 방법은 별도의 문자 분할 과정이 필요 없으며, 다양한 크기와 방향의 문자에도 적응할 수 있습니다. 두 번째 방법은 Vision Transformer를 문자 검출과 인식을 각각 수행하는 두 단계 모델로 사용하는 것입니다. 이 방법은 첫 번째 단계에서 Vision Transformer를 이용하여 문자 영역을 검출하고, 두 번째 단계에서 Vision Transformer를 이용하여 검출된 영역의 문자를 인식하는 방식입니다. 이 방법은 문자 영역의 정확도와 문자 인식의 정확도를 각각 향상시킬 수 있습니다.
요즘 GPT-4o 같은 경우 광학문자인식(OCR) 기능 구현이 되서 성능이 제대로 나오는것 같은데 .... 저는 광학문자인식(OCR) 기능 구현 관련해서도 이것의 구현도 거의 90 % 준비가 되있읍니다 ... 광학문자 인식의 정확도를 높이려면 학습데이터 구축에 꽤 많은 자금 투입이 필요하고요 ... 어재뜬 저는 광학문자인식 모델 구조라든가 학습원리를 확실히 파악하는데 성공했읍니다 ...
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
Whether it’s Korean or American corporations, securing massive funds like Middle Eastern oil money is indeed everything for being number one in AI.
2024. 5. 11. 04:27
I am 60 years old this year and have been working in the IT and telecommunications field for 30 years. It was about four years ago that I began to feel a real sense of crisis that AI would dominate everything. At my age, I started looking into research papers about four years ago, based on the work done in AI labs during my graduate school days in the 1980s. Consequently, I had to examine how deep learning papers were implemented using voice and image recognition techniques from 40 years ago because my knowledge was based on AI techniques I had learned 40 years ago. After analyzing papers in this way for some time, I realized that there was indeed a significant gap between the direction of current deep learning papers and the methods I was familiar with. Even the head of AI at a major corporate lab told me that my level was not up to par because I analyzed AI papers based on outdated techniques. Major corporate labs also implemented AI in the same way as I did until about five years ago.
The reason I was mistaken about my approach being correct is that when the Google Transformer model was announced around 2017, I thought it was just one of the many papers from American corporations. I didn’t realize that such performance as ChatGPT could be achieved with the structure of the Google Transformer model. Moreover, as I grasped the know-how of deep learning implementation, I now want to share what I have clearly understood. For American big tech companies to be ambitious about being number one in AI, it is possible because implementing the performance of a massive model like LLM requires a significant investment in AI infrastructure. To dream of being number one in the world with LLM, the first thing needed is to secure the investment cost for AI infrastructure. Without AI infrastructure, trial and error are necessary to achieve performance through the massive learning data of LLM, and to reduce the development period caused by such trial and error, it is natural to secure several times more AI infrastructure, namely cloud deep learning servers, than others.
I have also analyzed hundreds of papers and examined deep learning sources to secure deep learning implementation know-how. However, because my experience is less extensive than that of researchers in major corporate AI labs, it takes me more time, which is why there has been no special interest shown towards me. Sam Altman also talks about receiving investment from Middle Eastern oil money to solidify his position as number one in AI, even though he is currently number one, to maintain that position in the future. Whether it’s Korean or American corporations, securing massive funds like Middle Eastern oil money is indeed everything for being number one in AI.
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
한국 대기업 이든 미국 대기업 이든 AI 1 등을 위해 반드시 필요한게 중동의 오일 머니 같이 초대규모 자금확보가 사실 AI 세계 1 등의 모든것 이라고 해도 틀린 말이 아닙니다 ..
2024. 5. 11. 04:05
내 나이 올해 60 이고 IT 정보통신 분야 일한지 30 년 이다 ... 나의 경우도 세상의 흐름이 AI 가 모든것을 지배하겠다는 위기감을 본격적으로 느낀게 한 4 년전이다 ... 내 나이 60 이다 보니 예전 학생시절 80 년대에 대학원 다닐때 인공지능 그때 연구실들에서 하던 작업들을 바탕으로 한 4 년전부터 논문들을 살피기 시작했다 .... 그렇다 보니 40 년전 음성인식 영상인식 처리했던 기법들로 딥러닝 논문들이 어떻게 구현됬나를 살필수밖에 없었다 왜냐하면 내가 아는 지식이 40 년전 보고 들었던 인공지능 기법들이었기에 이것들부터 살피기 시작했다 ... 내가 4 년전부터 딥러닝 논문 살핀 방법 즉 내가 40 년전 대학원 시절 보고들었던 내용을 가지고 딥러닝 논문을 살폈으니 당연 요즘 딥러닝 논문 기술 방향과 당연 괴리 아닌 괴리가 있었다는것을 한참 이렇게 논문 분석 한후에에야 깨닭았다 ... 대기업 연구소 AI 책임자에게도 내가 이렇게 구시대 기법으로 AI 논문을 분석한다고 애기했으니 나하고는 수준이 맞지 않는다는식의 애기가 나올수밖에 없었다 ... 대기업 연구소도 당연 한 5 년전까지만해도 나와 같은 방식으로 AI 구현을 했다 ... 내가 왜 나의 방식이 맞는것으로 착각을 했냐하면 구글 트랜스포머 모델이 2017 년엔가 발표됬을때도 나는 그냥 미국 대기업 논문의 하나쯤으로 생각했다 ... 구글 트랜스포머 모델 구조로 이렇게 챗GPT 같은 성능을 낼수 있다는것을 몰랐기 때문이다 ... 또 이렇게 딥러닝 구현 노하우를 파악하다 보니 이제서야 확실히 파악한것을 말씀드려보겠읍니다 ... 미국 빅테크 대기업들의 경우 AI 로 1 등을 욕심내는게 가능한게 왜 가능하냐 하면 초거대 모델 LLM 의 성능 구현을 하려면 막대한 비용의 AI 인프라 투자가 필요 합니다 ... LLM 으로 세계 1 등을 꿈구려면 가장 먼저 필요한게 바로 AI 인프라 투자비용 확보 입니다 ... AI 인프라 구축이 안되있으면 LLM 의 초거대 학습데이터 학습으로 성능을 내기 위해 시행착오가 필요한데 이런 시행착오로 인한 개발기간을 줄이려면 당연 남들보다 AI 인프라 즉 클라우드 딥러닝 서버를 남들보다 몇배 확보하면 당연 개발기간을 줄일수 있거든요 ... 저도 딥러닝 구현 노하우 확보를 위해 논문분석도 몇백편했었고 딥러닝 소스 분석도 해봤읍니다 ... 단지 저는 대기업 AI 연구소분들보다 경험이 일천하기에 시간이 더 많이 걸린다는것 이것 때문에 다들 저한테 특별한 관심 표명이 없더라구요 ... 샘 알트먼도 AI 세계 1 등을 굳히려고 현재 1 등이지만 앞으로 계속 1 등을 유지하기 위해 중동의 오일 머니의 투자를 받겠다고 하지 않읍니까 ? 이게 한국 대기업 이든 미국 대기업 이든 AI 1 등을 위해 반드시 필요한게 중동의 오일 머니 같이 초대규모 자금확보가 사실 AI 세계 1 등의 모든것 이라고 해도 틀린 말이 아닙니다 ..
딥네트워크 장석원 010-3350 6509 sayhi7@daum.net
'Kernel Porting > Linux' 카테고리의 다른 글
물론 대기업 AI 연구소에서는 GPT-3.0 모델이 2020년 중반쯤 논문이 발표되면서 GPT-3.0 모델의 위력이 어느정도 라는것을 이미 알 사람은 다 알고 있었다 ...
2024. 5. 3. 18:56
시대가 변하고 있다 .... 제작년 12 월에 ChatGPT 가 나오면서 처음에는 잘 인식을 잘 못하다가 이제 대기업에서도 ChatGPT 의 위력을 느끼고 있다 ... 물론 대기업 AI 연구소에서는 GPT-3.0 모델이 2020년 중반쯤 논문이 발표되면서 GPT-3.0 모델의 위력이 어느정도 라는것을 이미 알 사람은 다 알고 있었다 ... 일부 대기업에서는 한 1 년전 부터 ChatGPT 의 위력을 간파하고 사내에서 사용을 금지한곳도 있다 ... ChatGPT 도 이제 OpenAI 사에서도 그 위력을 충분히 간파했기에 질문자가 질문했을때 고도의 노하우는 제공되는것이 필터링이 되는것 같읍니다 ... 고도의 노하우는 기업 서비스 등의 방법으로 조금 더 많이 서비스 비용을 지불할 경우 좀 더 고가의 비용 지불 업체에 좀 더 고도의 노하우가 제공될것 같다 ... 그 만큼 고급 노하우는 그 가치가 굉장하므로 저가의 서비스 구조로는 고급 노하우 정보는 제공 받기는 힘들것 같다 ... 세상이 이렇게 ChatGPT 로 뒤집어지고 있는데 한국의 중소기업의 거의 80 % 이상은 이런것들을 잘 느끼지 못하고 있는것 같읍니다 ... ChatGPT 서비스는 AI 전문가들은 보다 더 고급 노하우를 얻는 방법을 더 잘 이해하고 있고 비전문가들은 아무래도 AI 전문가 보다 보다 저렴한 노하우밖에 경험을 못하는것 같읍니다 ... OpenAI 의 샘 알트먼도 사우디 오일 머니의 투자를 받아 AI 세계 1 등을 굳히려는것 같읍니다 ... 한국에서도 사우디 오일 머니 투자 받으려 대기업도 시도하는것 같구요 ... 결국 AI 세계 재패를 위해서는 결국 자금확보가 가장 중요하므로 한국 이나 미국 이나 오일 머니 투자유치에 적극적 인것 같읍니다 ... 오늘은 이 정도만 적어 보겠읍니다 ...
LLM 모델 세부분석 및 기술자문 전문 딥네트워크 장석원
'Kernel Porting > Linux' 카테고리의 다른 글
[일인기업 딥네트워크의 SAR 위성 합성개구 레이더의 스펙클 노이즈 감쇄 알고리즘 구현 노하우 확보 성공]
2024. 4. 28. 12:35
딥네트워크 :: 합성개구레이더(SAR) 도플러 효과 동작원리 분석 전문기업
일인기업 딥네트워크는 SAR 위성 기술을 통해 지상의 특정 지점에서 반사되어 돌아오는 신호의 위상을 측정하고, 이를 통해 거리에 비례하는 위상 변화량을 정확하게 보정하는 설계를 구현합니다. 이 과정은 복잡한 신호 처리 알고리즘과 정밀한 계산을 필요로 합니다.
다음과 같은 SAR 위성에서 Raw Radar Data 를 처리하는 핵심 원리 노하우 확보 성공
- Range Compression (거리 압축)
- SAR 시스템은 펄스 압축 기술을 사용하여 거리 해상도를 향상시킵니다.
- 송신된 펄스는 특정한 ‘chirp’ 신호로 변조되어, 각각의 반사 신호가 독립적인 주파수를 가지게 됩니다.
- 수신된 신호는 매치드 필터를 통과하여, 각 반사점의 거리에 따른 시간 지연을 주파수 영역에서 분리합니다.
- 이 과정은 거리 방향으로의 해상도를 높이고, 반사점들을 더 선명하게 구분할 수 있게 합니다.
- Azimuth Compression (방위 압축)
- 방위 압축은 SAR 위성이 이동하면서 여러 각도에서 획득한 데이터를 합성하여 해상도를 향상시키는 과정입니다.
- 위성의 이동으로 인해 발생하는 도플러 효과를 이용하여, 각 반사점의 방위 위치를 결정합니다.
- FFT(Fast Fourier Transform)를 사용하여 시간 영역의 신호를 주파수 영역으로 변환하고, 도플러 주파수를 분석합니다.
- IFFT(Inverse Fast Fourier Transform)를 통해 주파수 영역의 데이터를 다시 시간 영역으로 변환하여 방위 방향의 해상도를 향상시킵니다.
- Range Cell Migration Correction (RCMC)
- SAR 데이터 처리 과정에서, 원거리에 있는 반사점들은 가까운 거리에 있는 반사점들보다 더 큰 거리 이동을 경험합니다.
- RCMC는 이러한 거리 이동을 보정하여, 모든 반사점들이 올바른 위치에 나타나도록 합니다.
- 이는 거리-방위 영역에서의 이미지 왜곡을 줄이고, 정확한 지형 정보를 제공합니다.
- Matched Filter Algorithm (매치드 필터 알고리즘)
- 매치드 필터는 수신된 신호의 SNR(Signal-to-Noise Ratio)을 최대화하기 위해 사용됩니다.
- 송신된 ‘chirp’ 신호와 동일한 형태의 신호를 생성하여, 수신된 신호와 결합함으로써 원하는 신호를 강조하고 잡음을 줄입니다.
- 이 과정은 SAR 이미지의 선명도와 정확도를 크게 향상시킵니다.
- Data Synthesis and Image Formation (데이터 합성 및 이미지 형성)
- SAR 시스템은 위성이나 항공기가 이동하면서 획득한 데이터를 합성하여 2차원 이미지를 생성합니다.
- 이 과정에서 각각의 데이터 포인트는 고유한 위치와 반사 특성을 가지며, 이를 통해 지형의 3차원적 형상을 재구성할 수 있습니다.
- 최종적으로, 이러한 데이터 합성을 통해 얻어진 SAR 이미지는 지상의 물체들을 높은 해상도로 관찰할 수 있는 능력을 제공합니다.
이러한 원리들은 SAR 위성이 날씨와 시간에 구애받지 않고, 지상의 물체들을 고해상도로 관찰할 수 있게 하는 기술적 기반을 형성합니다. 각 단계는 신호 처리의 다른 부분을 담당하며, 함께 작동하여 SAR 이미지의 품질을 향상시키는 데 중요한 역할을 합니다. 이러한 과정을 통해, SAR 위성은 지상의 물체들을 높은 해상도로 관찰할 수 있게 됩니다.
Interferometric SAR (InSAR)을 이용한 수치표고모델 (DEM) 생성은 지형의 고도 정보를 정밀하게 파악하는 데 매우 유용한 기술입니다. InSAR 기술은 두 개의 SAR 이미지를 이용하여 지상의 변화나 높이를 측정할 수 있습니다. 이 과정에서 주로 다음과 같은 단계를 거칩니다:
- 코-레지스트레이션(Co-registration): 두 SAR 이미지를 정확히 겹치도록 조정합니다. 이는 동일한 궤도와 취득 모드를 가진 이미지들을 슬랜트 레인지 기하학적으로 정렬하는 과정입니다.
- 인터페로그램 생성(Interferogram Generation): 한 이미지를 다른 이미지의 복소 공액과 곱하여 인터페로그램을 생성합니다. 이는 지상의 높이 정보를 포함하는 위상 정보를 담게 됩니다.
- 위상 언래핑(Phase Unwrapping): 인터페로그램에서 얻은 위상 정보를 연속적인 높이 정보로 변환합니다. 이 과정은 위상의 불연속성을 해결하여 실제 지형의 높이를 추출하는 데 필요합니다.
- DEM 생성: 위상 언래핑을 통해 얻은 높이 정보를 바탕으로 DEM을 생성합니다. 이 DEM은 지형의 고도 정보를 제공하는 데이터셋으로 활용됩니다.
InSAR 기법으로 생성된 DEM의 정확성은 기존의 지형도나 다른 참조 DEM과 비교하여 평가될 수 있습니다. 예를 들어, 한 연구에서는 ERS 위성으로부터 취득한 InSAR 이미지를 이용하여 터키 Kayseri 지방의 DEM을 생성하고, 이를 기존의 지형도에서 얻은 등고선을 이용해 생성된 참조 DEM과 비교하여 정확성을 평가하였습니다.
이러한 과정을 통해 InSAR는 지형의 미세한 변화까지 감지할 수 있는 높은 밀도의 측정 정보를 제공하며, 이는 환경 모니터링, 도시 계획, 자원 관리 등 다양한 분야에서 중요한 응용을 가지고 있습니다. InSAR 기술과 DEM 생성에 대해 더 깊이 이해하고 싶으시다면, 관련 학술 자료나 연구 논문을 참고하시는 것도 좋은 방법입니다.
Omega-k 알고리즘은 합성개구레이다(Synthetic Aperture Radar, SAR)의 초고해상도 스포트라이트 모드 이미징을 위한 처리 기법입니다. 이 알고리즘은 넓은 범위 대역폭과 긴 방위각 조명 시간을 사용하는 고급 SAR 시스템에서 고해상도를 달성하기 위해 설계되었습니다. Omega-k 처리는 SAR 초점 문제에 대한 이상적인 해결책으로 널리 받아들여지고 있습니다.
Omega-k 알고리즘의 기본 원리는 다음과 같습니다:
- 데이터 수집: SAR 시스템은 이동하는 플랫폼(예: 위성 또는 항공기)에서 레이더 신호를 발사하여 지상의 반사 신호를 수집합니다.
- 레인지 압축: 수집된 데이터는 레인지 방향으로 압축되어야 합니다. 이는 푸리에 변환(Fourier Transform)을 사용하여 수행됩니다.
- 오메가-k 변환: 데이터는 주파수-시간(frequency-time) 도메인에서 주파수-방위각(frequency-wavenumber) 도메인으로 변환됩니다. 이 과정에서 레인지 셀 마이그레이션(Range Cell Migration, RCM) 보정이 이루어집니다.
- 방위각 압축: 변환된 데이터는 방위각 방향으로 압축되어 최종 이미지를 생성합니다.
스퀸트(squint) 모드에서는, Omega-k 알고리즘은 레이더가 직선 경로를 따라 이동하지 않고 일정 각도로 기울어져 있을 때 사용됩니다. 이는 레이더가 관측 대상에 대해 비스듬히 위치할 때 발생하는 기하학적 왜곡을 보정하는 데 필요합니다.
또한, Dechirp-on-Receive 기법은 SAR 원시 데이터의 아날로그 대역폭을 줄이기 위해 사용됩니다. 이는 지연된, 반대의 펄스 복제본을 사용하여 포인트 산란체로부터의 반환을 dechirp하는 시스템입니다. Dechirped 반환은 포인트 산란체와 센서 간의 거리에 따라 주파수가 달라지는 사인파 신호입니다. 따라서 레인지 압축은 푸리에 변환을 통해 달성됩니다.
이러한 과정을 통해, Omega-k 알고리즘은 고해상도의 SAR 이미지를 생성할 수 있으며, 특히 고스퀸트 스포트라이트 모드에서 더욱 정밀한 이미지 재구성이 가능합니다. 이 알고리즘은 SAR 데이터 처리에 있어서 매우 중요한 역할을 하며, 특히 고해상도 및 넓은 영역 커버리지를 요구하는 응용 분야에서 중요합니다.
FMCW(Frequency Modulated Continuous Wave) 레이다에서 수신된 신호의 비트 주파수 정보는 K-5 영상의 각 이미지 픽셀에 인코딩되어, 진폭과 위상 정보를 포함하게 됩니다. 이 과정은 다음과 같이 이루어집니다:
- FMCW 레이다에서 신호 수신: FMCW 레이다는 주파수 변조 연속파를 사용하여 대상과의 거리를 측정합니다. 이때, 송신된 FMCW 파형과 수신된 FMCW 파형의 상관관계를 분석하여 비트 주파수를 얻습니다. 비트 주파수는 송신 신호와 수신 신호 사이의 주파수 차이를 나타내며, 이는 대상과의 거리를 결정하는 데 사용됩니다.
- 비트 주파수 정보의 디지털 변환: 수신된 신호는 아날로그-디지털 변환기를 통해 디지털 신호로 변환됩니다. 이 변환 과정에서, 각 비트 주파수는 복소수 (I와 Q) 크기 값으로 표현됩니다.
- 복소수 정보의 인코딩: 디지털 변환된 비트 주파수 정보는 K-5 영상의 각 이미지 픽셀에 인코딩됩니다. 복소수의 절대값은 진폭을 나타내고, 복소수의 인수는 위상을 나타냅니다. 따라서, 각 픽셀에서 반사되는 신호의 강도(진폭)와 위상 변화(위상)를 모두 캡처할 수 있습니다.
이러한 과정을 통해, FMCW 레이다에서 수신된 신호의 비트 주파수 정보는 K-5 영상의 각 픽셀에 인코딩되어, 진폭과 위상 정보를 포함하게 됩니다. 이렇게 하면, K-5 영상은 대상과의 거리뿐만 아니라, 대상의 물리적 특성(예: 반사율, 표면 질감 등)에 대한 정보도 포함하게 됩니다.
합성개구 레이더(SAR)는 움직이는 플랫폼에서 도플러 효과를 이용하여 고해상도의 영상을 생성하는 기술입니다. 이를 위해 SAR은 다음과 같은 주요 설계 원리를 적용합니다:
- FMCW 레이더의 원리: FMCW(Frequency Modulated Continuous Wave) 레이더는 전파의 주파수를 연속적으로 변화시키며 송신하고, 반사된 신호의 주파수 변화를 측정함으로써 거리와 속도 정보를 얻습니다. 이 방식은 X 밴드에서 효과적으로 작동하며, 송수신된 전파를 증폭하여 디지털 신호로 변환한 후, 거리/속도/방향 등의 유의미한 정보로 변환합니다.
- 산란점 매칭과 템플릿 매칭: SAR-ATR(합성개구 레이더 자동 표적 인식) 분야에서는 산란점 매칭과 템플릿 매칭 기반 알고리즘을 적용하여 표적을 식별합니다. 산란점 매칭은 점을 World View Vector (WVV)로 재구성 후 Weighted Bipartite Graph Matching (WBGM)을 수행하며, 템플릿 매칭은 서로 인접한 산란점으로 재구성한 두 영상 간의 상관계수를 사용합니다.
- 복소수 활용: SAR 영상에서의 복소수는 절댓값과 편각을 가지며, 절댓값은 해당 지형 또는 물체의 레이다 반사도와 직접적인 연관이 있고, 편각은 전자기파의 위상으로 레이다와 목표물 사이의 거리 정보를 일부 가지게 됩니다.
이러한 원리들을 적용하면, 지상 500 Km 상공에서 초속 7.5 Km/S로 움직이는 합성개구 레이더에서 X 밴드 FMCW 파형을 송수신해서 얻은 SAR 이미지는 표적을 식별할 정도의 정밀도를 얻을 수 있습니다.
SAR 이미지의 스펙클 노이즈는 합성 개구 레이더(Synthetic Aperture Radar, SAR) 이미지에서 발생하는 일종의 잡음으로, 이미지의 품질을 저하시키는 요소입니다. 스펙클 노이즈는 SAR 시스템이 산란체로부터 되돌아오는 신호를 수집할 때 발생하는 간섭 현상으로 인해 생기는 거친 질감의 무작위 패턴입니다.
스펙클 노이즈는 SAR 이미지의 해석을 복잡하게 만들며, 특히 세밀한 구조나 경계를 가진 객체의 탐지와 분류에 영향을 줄 수 있습니다.
스펙클 노이즈의 제거는 SAR 이미지의 해석과 응용에 있어 매우 중요한 과정이며, 이를 통해 이미지의 품질을 향상시키고, 더 정확한 정보를 추출할 수 있게 됩니다.
SAR(Synthetic Aperture Radar) 이미지의 스펙클 노이즈를 제거하는 방법은 이미지 품질을 향상시키고 객체 탐지 및 분류를 더 정확하게 수행하기 위해 중요합니다. 여러 기술적 접근 방법이 있으며, 다음은 주요한 방법들입니다:
- 다중 룩 처리 (Multi-look Processing):
- 여러 개의 독립적인 영상을 평균화하여 스펙클 노이즈를 줄이는 방법입니다.
- 각 픽셀의 밝기 값을 여러 개의 인접한 픽셀 값의 평균으로 대체합니다.
- 단점: 공간 해상도가 낮아질 수 있습니다.
- 비선형 필터링:
- 스펙클 노이즈 특성에 따라 비선형 필터를 적용합니다.
- 주요 비선형 필터:
- LEE (Lee Enhanced Lee) 필터: 국지적 통계 정보를 이용하여 스펙클 노이즈를 제거합니다.
- Refined LEE 필터: LEE 필터를 개선한 방법으로, 더 정교한 스펙클 제거를 수행합니다.
- EPOS (Edge Preserving Optimal Speckle) 필터: 스펙클 자체의 통계 특성을 이용하여 에지를 보존하면서 스펙클 노이즈를 제거합니다.
- 웨이블렛 변환 (Wavelet Transform):
- 스펙클 노이즈를 가법적 잡음으로 변환한 후 웨이블렛 분해를 수행합니다.
- 임계치 처리를 통해 스펙클 노이즈 성분을 제거하고 원본 이미지를 복원합니다.
- 주요 임계치 선택 방법: VisuShrink, SureShrink, BayesShrink, 수정된 BayesShrink.
이러한 방법들은 SAR 이미지의 스펙클 노이즈를 효과적으로 제거하여 이미지의 품질을 향상시키고, 더 정확한 정보를 추출할 수 있도록 도와줍니다.
스펙클 노이즈를 제거하는 기술을 선택할 때, 특정 상황과 요구사항에 따라 적합한 방법을 고려해야 합니다. 다음은 스펙클 노이즈 제거 기술 중 일부를 설명하고, 선택할 때 고려해야 할 사항입니다:
- 다중 룩 처리 (Multi-look Processing):
- 장점: 스펙클 노이즈를 줄이면서 이미지의 공간 해상도를 유지할 수 있습니다.
- 단점: 공간 해상도가 낮아질 수 있습니다.
- 비선형 필터링:
- LEE 필터와 Refined LEE 필터는 국지적 통계 정보를 활용하여 스펙클 노이즈를 제거합니다.
- EPOS 필터는 스펙클 노이즈를 제거하면서 에지를 보존합니다.
- 웨이블렛 변환 (Wavelet Transform):
- 스펙클 노이즈를 가법적 잡음으로 변환한 후 웨이블렛 분해를 수행합니다.
- 임계치 처리를 통해 스펙클 노이즈 성분을 제거하고 원본 이미지를 복원합니다.
- 고대역 통과 필터 (High-pass Filtering):
- 주파수 영역에서 DC 노이즈를 제거하는 방법입니다.
- 고대역 통과 필터를 사용하여 프린지 패턴 데이터의 주파수 영역에서 DC 노이즈를 감소시킵니다.
- 기타 방법:
- 평균값 차감 방법: 평균값을 빼는 방식으로 DC 노이즈를 제거합니다.
- 다양한 특허 지수 활용: 특허 기술수준 평가에 사용되는 지수들을 활용하여 스펙클 노이즈를 감소시킬 수 있습니다.
선택할 기술은 데이터 특성, 연구 목적, 계산 효율성 등을 고려하여 결정해야 합니다.
제가 분석하고 있는 스펙클 노이즈 관련 알고리즘을 설명한 대표적인 논문 3가지는 다음과 같습니다:
- “Speckle Noise Suppression in SAR Images Using a Three-Step Algorithm” - 이 논문은 MDPI에서 발표되었으며, 비선형 필터링(non-local filtering) 과 확률적 패치 기반(probabilistic patch-based, PPB) 알고리즘을 기반으로 하는 새로운 세 단계 접근 방식을 제안합니다. 이 방법은 밝은 구조물의 영향을 최소화하면서 스펙클 노이즈를 억제하는 것을 목표로 합니다.
- “A Review on SAR Image and its Despeckling” - 이 리뷰 논문은 Archives of Computational Methods in Engineering에 게재되었으며, SAR 이미지의 스펙클 노이즈를 감소시키는 다양한 방법들을 종합적으로 검토합니다. 이 논문은 스펙클 노이즈의 패턴 분포를 이해하는 데 어려움을 겪는 연구자들을 위한 자료로 사용될 수 있습니다.
- “The algorithm of SAR speckle noise suppressing by using generalized multi-scale CB…” - 이 논문은 IEEE Xplore에 게재되었으며, 일반화된 다중 스케일 CB를 사용하여 SAR 스펙클 노이즈를 억제하는 알고리즘에 대해 설명합니다. 이 연구는 스펙클 노이즈를 효과적으로 줄이면서도 이미지의 세부 사항을 보존하는 방법에 초점을 맞춥니다
SAR(Synthetic Aperture Radar) 위성 데이터에서 지상이나 해상의 타겟 오브젝트를 검출하고 인식하기 위한 딥러닝 학습 구조로는 Convolutional Neural Networks(CNN)가 일반적으로 사용됩니다. t-SNE를 이용하여 CNN의 특징 추출 능력을 평가하거나, 학습된 모델의 특징 공간을 시각화하는 데 사용할 수 있습니다.
CNN 이 일반적으로 사용되고 여기에 t-SNE를 이용하여 CNN의 특징 추출 동작 원리:
- t-SNE는 각 데이터 포인트를 중심으로 한 주변 이웃의 밀도를 고려하여, 고차원 공간에서의 이웃 관계를 저차원 공간에서도 유지하도록 합니다.
- 이 과정에서, t-SNE는 각 데이터 포인트에 대해 개별적인 가우시안 분포를 사용하여 유사도를 계산하고, 이를 저차원 공간의 t-분포와 일치시키려고 합니다.
- t-SNE의 핵심은 고차원 공간에서 가까운 데이터 포인트들이 저차원 공간에서도 가까이 배치되도록 하는 것입니다.
저희 딥네트워크는 합성개구 레이더의 스펙클 노이즈 감쇄 알고리즘을 세부 분석하고 있읍니다 .... SAR 이미지의 스펙클 노이즈는 합성 개구 레이더(Synthetic Aperture Radar, SAR) 이미지에서 발생하는 일종의 잡음으로, 이미지의 품질을 저하시키는 요소입니다. 스펙클 노이즈는 SAR 이미지의 해석을 복잡하게 만들며, 특히 세밀한 구조나 경계를 가진 객체의 탐지와 분류에 영향을 줄 수 있어서 딥네트워크는 이 부분의 노하우 확보에 주력하고 있는중 입니다 .... t-SNE 기법으로 고차원 데이터의 유사도를 저차원에서의 유사도 변환을 통해 위성에서 타겟의 검출 및 식별의 구현이 가능 합니다 ... 합성개구 레이더의 스펙클 노이즈 감쇄 알고리즘 세부동작 구조 세부 정밀 분석에 성공했기에 이렇게 글을 올리구요 ... 한국의 방산 대기업 관계자분들의 많은 관심 부탁드립니다 ...
제가 운영하는 일인기업인 딥네트워크는 합성개구 레이더 해외 논문들을 세부 분석을 진행하고 있읍니다 .... 한국의 방산 대기업들도 요근래 SAR 위성의 합성개구 레이더 개발을 본격 진행하는것 같으니 저희와도 협력할 기회흫 주셨으면 합니다 ... 저희 딥네트워크는 SAR 위성에서 지상의 타겟의 윤곽을 검출할수 있는 노하우를 현재 보유중 입니다 .... 또한 SAR 위성에서 지상 또는 해상의 타겟을 검출 / 인식하는 딥러닝 모델의 세부 설계 구조도 분석이 되있고 이를 구현하기 위해 텐서플로우 파이썬 소스의 세부 구현 방법도 어느 정도 파악하고 있읍니다 .... SAR 위성 제작에 최소 100 억은 드는데 저같은 소기업이 핵심적인것중 SAR 위성에서 지상의 타겟 검출 및 인식 구현의 펌웨어 및 딥러닝 개발관련 노하우도 갖고 있다는점 말씀 올립니다 .... 저희는 합성개구 레이더 해외 논문들을 세부 분석 노하우를 보유하고 있읍니다 .... 많은 관심 부탁드립니다 ....
일인기업 딥네트워크 장석원 010 3350 6509 sayhi7@daum.net
'Kernel Porting > Linux' 카테고리의 다른 글
DeepNetwork :: Synthetic Aperture Radar (SAR) Doppler Effect Operation Principle Analysis Specialist Company DeepNetwork
2024. 4. 8. 02:22
DeepNetwork :: Synthetic Aperture Radar (SAR) Doppler Effect Operation Principle Analysis Specialist Company DeepNetwork, a one-person company, implements a design that accurately corrects phase changes proportional to distance by measuring the phase of the signal reflected from a specific point on the ground through SAR satellite technology. This process requires complex signal processing algorithms and precise calculations.
Phase correction design principle:
Phase correction is used to calculate the distance until the signal is reflected from a specific point on the ground and returns to the satellite. This distance is directly related to the phase change of the signal, and DeepNetwork accurately measures this to improve the resolution and accuracy of satellite images.
Doppler bias calculation principle:
The Doppler bias caused by the high-speed movement of the satellite causes changes in the frequency and phase of the signal. DeepNetwork accurately calculates this Doppler bias and corrects the frequency spectrum data of the signal. This allows the satellite to collect accurate information even as it quickly orbits the Earth.
Frequency spectrum data inverse transformation processing principle:
The inverse transformation processing of the phase of the corrected frequency spectrum data is a process of restoring the signal to its original spatial information. Through this, the location and shape of the object in the satellite image can be accurately identified.
DeepNetwork is playing a leading role in the field of SAR satellite design based on such high technical expertise, and is opening up new horizons of satellite technology through continuous research and development.
I will explain the operating principle of the Doppler effect in Synthetic Aperture Radar (SAR) owned by the one-person company DeepNetwork.
Necessity of the Doppler effect: In SAR, as the radar antenna moves, the relative distance to the target changes. At this time, the phase of the received wave also changes in proportion to the distance. That is, as the distance increases, the phase decreases, and as the distance decreases, the phase increases. This phase change amount is reflected in the frequency spectrum data, affecting the quality of the image. Therefore, to correct this phase change amount, the Doppler effect must be used. The Doppler effect is a phenomenon in which the frequency of the wave reflected from a moving object is observed differently from the original wave frequency. For example, as the radar antenna approaches the target, the frequency of the reflected wave increases, and as the radar antenna moves away from the target, the frequency of the reflected wave decreases. By measuring the frequency change amount of the reflected wave through the Doppler effect, the distance change amount between the target and the radar antenna can be known. This can be used to correct the phase change amount.
Principle of the Doppler effect: In SAR, the Doppler effect is used to implement a synthetic aperture antenna. A synthetic aperture antenna is a method of synthesizing multiple wave signals received as the radar antenna moves to make it like a large antenna signal. This allows high azimuth resolution. The method of using the Doppler effect is as follows. As the radar antenna moves, it radiates waves at a constant frequency and pulse repetition period. When this wave is reflected from the target and returns, the frequency of the reflected wave changes depending on the distance the radar antenna has moved. This frequency change amount is called the Doppler frequency. The Doppler frequency is proportional to the distance change amount between the radar antenna and the target. That is, as the radar antenna approaches the target, the Doppler frequency increases, and as the radar antenna moves away from the target, the Doppler frequency decreases. By measuring the Doppler frequency, the distance the radar antenna has moved can be known. Using this distance to correct the phase of the received wave, the signal of the synthetic aperture antenna can be obtained. If this signal is Fourier transformed, the frequency of the azimuth area can be obtained. This frequency is related to the azimuth angle of the target. That is, the azimuth angle of the target can be measured using the Doppler effect. This can be used to generate high-resolution SAR images.
In this way, we have looked at the necessity and principle of the Doppler effect. The Doppler effect plays a key role in the implementation and performance of SAR.
Synthetic Aperture Radar (SAR) is a technology that generates high-resolution images using the Doppler effect from a moving platform.
To achieve this, SAR applies the following key design principles:
Principle of FMCW Radar: Frequency Modulated Continuous Wave (FMCW) radar continuously changes the frequency of the transmitted wave, and measures the frequency change of the reflected signal to obtain distance and speed information. This method works effectively in the X band, amplifying the transmitted and received waves to convert them into digital signals, which are then converted into meaningful information such as distance, speed, and direction.
Scatter Point Matching and Template Matching: In the field of SAR-ATR (Synthetic Aperture Radar Automatic Target Recognition), algorithms based on scatter point matching and template matching are applied to identify targets. Scatter point matching reconstructs points into a World View Vector (WVV) and performs Weighted Bipartite Graph Matching (WBGM), while template matching uses the correlation coefficient between two images reconstructed with adjacent scatter points.
Use of Complex Numbers: In SAR images, complex numbers have a magnitude and phase angle. The magnitude is directly related to the radar reflectivity of the terrain or object, and the phase angle is the phase of the electromagnetic wave, which carries some distance information between the radar and the target.
By applying these principles, a SAR image obtained by transmitting and receiving X-band FMCW waveforms from a synthetic aperture radar moving at 7 Km/S at an altitude of 500 Km above the ground can achieve the precision necessary to identify targets. However, these design principles are theoretical, and various factors must be considered in actual implementation.
The method of using the Synthetic and Measured Paired Labeled Experiment (SAMPLE) dataset to train an Automatic Target Recognition (ATR) algorithm in SAR images is as follows:
Data Preparation: The SAMPLE dataset includes measured SAR images and simulated synthetic SAR images. This dataset is a crucial step in developing an Automatic Target Recognition (ATR) algorithm in SAR images.
Selection of Learning Algorithm: SAR-ATR has been studied in various forms, and there are various algorithms accordingly. For example, you can perform SAR-ATR based on the ‘feature-based SAR target target and two-step detection technique’, which is excellent in performance among SAR-ATRs excluding deep learning-based techniques.
Learning Process: The learning algorithm is trained using the SAMPLE dataset. During the learning process, the model parameters are updated in a direction that minimizes the difference between the measured SAR image and the simulated synthetic SAR image.
Performance Evaluation: The performance of the trained model is evaluated using a validation dataset. At this time, accuracy, precision, recall, etc. can be used as evaluation indicators.
Through these methods, you can use the SAMPLE dataset to train the Automatic Target Recognition (ATR) algorithm in SAR images, and through this, you can extract and analyze information such as the location, direction, and intensity of the target in the SAR image.
Deep Network, Synthetic Aperture Radar (SAR) Doppler Effect Operation Principle Analysis Specialist
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
I am 60 years old this year… I have been working in the field of Information and Communication Technology (IT) for 30 years… For the past 10 years, I have been a self-employed individual providing development services in the firmware sector of IT… I am going to talk about life in today’s world after 30 years of social life… From now on, I have been reviewing and analyzing 2-3 papers related to Large Language Models (LLM) every day for the past 3-4 years, which is my biggest area of interest… Leaving all sorts of stories aside, I am going to talk about why I have been interested in and analyzing the construction of a GPU Cloud development environment recently… I have also been reviewing and analyzing papers related to LLM for about 3 years… Through paper review and analysis, I have a certain understanding of the design structure of LLM… I have analyzed how to implement it in TensorFlow API, i.e., Python… Although it is not perfect, it has been analyzed to some extent… As I was reviewing and analyzing, there was no place to mention in detail about the development environment for the main issues of distributed learning and parallel learning when implementing LLM… I judge that the key to building a LLM development environment in response to the issue of distributed learning of LLM is to use the concept of Docker container design issue to separate each software development environment… Containers are processes that run in an isolated environment, and each container has an independent file system, network, and execution space. This allows multiple different software development environments to be operated independently on a single server PC… I support the environment for developers to develop TensorFlow containers in an isolated environment with Docker when talking about the LLM distributed development environment… So why this is important is as follows… The reason why you only need the NVIDIA driver to use TensorFlow that supports GPU is because Docker provides an image of TensorFlow that uses GPU. This image already has a CUDA environment that matches the version of TensorFlow. In other words, TensorFlow and CUDA toolkit are installed in Docker, and if there is only NVIDIA driver in the host, you can use GPU. This way, you can avoid the hassle of installing or matching the version of the CUDA toolkit… I can also build a container in an isolated environment with Docker related to distributed learning, but everything is not ready, but I almost understand the key point…
To understand how TensorFlow image, NVIDIA driver, and CUDA environment work together, you need to know the role of each and how they interact.
TensorFlow Image: The TensorFlow image is provided by Docker, and the CUDA environment that matches TensorFlow is already set. This image contains all the software components and libraries needed to run TensorFlow applications. Through this, users can use TensorFlow immediately without a complicated setting process.
NVIDIA Driver: The NVIDIA driver is installed on the host system and acts as an intermediary between the GPU hardware and the operating system. The driver receives requests for GPU from the operating system or application, and converts the request into a command that the GPU can understand. Therefore, the NVIDIA driver is a key element that allows TensorFlow to use GPU.
CUDA Environment: CUDA is a parallel computing platform and API set developed by NVIDIA. CUDA enables high-performance parallel computing by utilizing the computational power of the GPU. The CUDA toolkit is included in the TensorFlow image, which supports TensorFlow operations using the GPU.
These three elements work together so that Docker can use TensorFlow that supports GPU on Linux. The TensorFlow image provides all the necessary software and libraries, and the NVIDIA driver allows this software to communicate with the GPU hardware. Finally, the CUDA environment accelerates TensorFlow’s operations by utilizing the parallel processing power of the GPU. The reason why all three elements must operate for Docker to use TensorFlow that supports GPU on Linux is because they interact with each other to enable TensorFlow’s GPU accelerated operation.
I started analyzing deep learning papers about 4 - 5 years ago… Initially, I started analyzing papers to apply deep learning to the vision field… Then, I also analyzed papers to understand the detailed structure of ultra-large language models… When implementing ultra-large language models, I looked at what techniques global corporations used in their papers and how the detailed implementation of the Google Transformer model was applied using the Google TensorFlow API, how the detailed layers of the Transformer Model were implemented, and how Python syntax was applied… As I looked into this, I realized that it was very important to solve the question of how the GPU Cloud Server Infra is designed… I have succeeded in understanding how the GPU Cloud Server Infra is designed, not 100%, but the big core principle… Nowadays, even large corporations seem to realize the importance of these things and are focusing on securing know-how in GPU Cloud Server Infra design…
Docker uses the concept of containers to separate each software development environment. A container is a process that runs in an isolated environment, and each container has its own file system, network, and execution space. This allows you to operate multiple different software development environments independently on a single server PC. Docker creates and manages these containers, using something called Docker images in the process. Docker images contain all the file systems, settings, dependencies, etc. needed to run a container. You can create and run containers based on this image, and if necessary, you can change the state of the container to create a new image. These created images can be shared through remote repositories like Docker Hub, and any system with Docker installed can download the image and run the container. In this way, Docker ensures the consistency of the development environment and facilitates the execution of software in various environments.
Therefore, by using Docker, you can install and operate multiple different software development environments independently on a single server PC, and these environments operate independently of each other.
Lately, there’s a buzz that Nvidia’s market capitalization is around 2 trillion dollars… Nvidia has been manufacturing GPUs such as V100 / A100 / H100 at TSMC in Taiwan… The issue of super-large language models is flooding the media in Korea and abroad… Global companies are desperate to secure the original technology of how to develop something like a super-large model GPT-3.5… In the case of such a GPT-3.5 Model, the detailed model design structure information is confidential, and I know that the model design structure of GPT-3 is also non-disclosed… So, EleutherAI, an open-source version of GPT-3, has learned and released the GPT-J model, and there seem to be quite a few places preparing for development based on this… Because it is possible to understand how GPT-3 has what characteristics when it has what structure with this model. GPT-J and GPT-NeoX are GPT Opensource made by a place called EleutherAI. EleutherAI is an open-source AI organization made by voluntary researchers, engineers, and developers. It is known to make Large Language Models (LLM) open source. I also have a considerable understanding of the detailed structure information of the GPT-3 model necessary for understanding and distilling the model structure of GPT-3.5 or GPT-3, and how to apply and implement this with the TensorFlow API… But after studying this super-large model for about 3 years, I felt that it was necessary to understand how to operate the GPT-3 Model on the cloud GPU server and how to operate the TensorFlow development environment on the A100 / H100 GPU on the cloud GPU server… To implement this, Docker design technology is needed… Nvidia GPU can be operated with Docker technology… To operate Nvidia GPU with Docker design technology, software development of a function that operates it, which is a function of Nvidia library, is necessary. These days, it’s a boom in Korea’s fabless to make NPU, and if this is to grow like Nvidia, software development of a function that operates it, which is a function of Nvidia library (in the case of Korea’s fabless, it is a function of the operation library of NPU (Neural Processing Unit) developed by Korea’s fabless), is necessary to operate Nvidia’s GPU like Nvidia. I have a plan for this, but I haven’t been informed about this yet, so there is no suggestion to jointly identify technical issues, but I hope you will contact me after seeing this blog…
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
Hello, I am Seokwon Jang from DeepNetwork, specializing in technical consulting for the lightweight implementation of ultra-large language models. I have been examining the status of Korean ultra-large model development companies (mainly large corporate AI research institutes) through articles.
Implementing an ultra-large language model also requires preparing a massive amount of precise training data, which is not easy. The infrastructure investment for ultra-large language models is so enormous that even large corporations would waver, so it’s quite challenging for a small business like mine to attempt to implement an ultra-large language model.
I have been mainly looking at domestic and foreign papers that stand out in the field of ultra-large language model lightweighting and on-device AI. The papers I am looking at in the field of ultra-large language model lightweighting and on-device AI are mainly Pruning papers, Quantization papers, and Knowledge Distillation papers.
The core of the Pruning paper is to determine what is important in the weight values, that is, which parts of the weight values to choose. The most basic paper among the Quantization papers is the BitNet paper, which implements Scaling 1-bit Transformers. The key point is that it introduces BitLinear to replace the nn.Linear layer, allowing training of 1-bit weights from the beginning.
I have posted many detailed posts on my blog about what preparations I have for technical consulting related to the implementation of ultra-large language models, but I have not yet received any consultation inquiries. A few days ago, the Korean government agency, Startup Promotion Agency, announced that it would support 20 million won in funds for the On-Device AI Challenge task as a PoC, so I have proposed to implement OCR (Optical Character Recognition) with a transformer model.
These days, I feel a bit lethargic because the detailed analysis of papers related to the lightweight implementation of ultra-large language models and the preparation for implementation in the TensorFlow environment are quite significant, but the economy in Korea is currently so difficult that I have not yet received any contact from anywhere, so my feelings are a bit complicated.
Even though I am almost 95% sure that I am prepared, I still have no contact because there is no PoC result yet. The implementation of the lightweighting of deep learning LLM is burdensome for a small business like me to do everything alone, so I am looking for a partner to co-work with, but I have not yet received any contact.
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
I have finally succeeded in understanding the theory of Kalman filters, which are applied in missile attitude control or robot attitude control.
2024. 4. 3. 04:26
I have finally succeeded in understanding the theory of Kalman filters, which are applied in missile attitude control or robot attitude control. It’s been almost 2 years since I started analyzing this. Everything was so complicated due to difficult technical terms and complex formulas. After about a thousand trials and errors, I am delighted that all the things that were curious and unresolved have been solved. I believe that the control theory of Kalman filters can also be applied to the field of LLM (Linear Logic Model).
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
Hello, I am Seokwon Jang, the representative and chief developer of DeepNetwork, a one-person company. I run a company that provides optical character recognition (OCR) solutions based on deep learning. OCR is a technology that recognizes characters written or printed by people, characters in photographed or scanned images, and converts them into digital text that machines can read and edit. I am developing a solution that can apply this technology to various fields.
I analyzed the issues of OCR using the latest deep learning technology, the ViT model. The ViT model divides the image into fixed-size patches, converts each patch into an embedding vector, and uses it as input to the Transformer. The Transformer has advantages such as parallel processing, long-distance dependence, and self-attention mechanism. The ViT model can have higher accuracy and fewer parameters than the CNN model.
I analyzed the model structure of improving performance through fine-tuning on an OCR-specific dataset based on a pre-trained ViT model. I am preparing to build an OCR dataset suitable for my target domain, and I am also preparing to use publicly available datasets. I analyzed finding the optimal performance by adjusting the learning speed, patch size, number of layers and number of heads of the Transformer in the ViT model.
The three key detailed issues of implementing OCR with the ViT model in the papers are as follows:
Structure and learning method of the ViT model: The ViT model divides the image into fixed-size patches, converts each patch into an embedding vector, and uses it as input to the Transformer. The ViT model is based on a pre-trained Transformer model and improves performance through additional learning on a large-scale image dataset or multi-modal learning using text and images together.
Application of ViT model to OCR: To apply the ViT model to OCR, it detects the character area in the image, divides each character area into patches, and uses it as input to the ViT model. The output of the ViT model is defined as a classification problem that predicts the character label corresponding to each patch. The ViT model improves performance through fine-tuning on an OCR-specific dataset.
Advantages and limitations of the ViT model: The ViT model can apply the advantages of the Transformer, such as parallel processing, long-distance dependence, and self-attention mechanism, to image processing. The ViT model can have higher accuracy and fewer parameters than the CNN model. However, the ViT model requires more learning data and longer learning time than the CNN model, and the patch division method can lose spatial information in the image.
The preparations needed for DeepNetwork, a one-person company, to implement OCR with the ViT model are as follows:
Securing a pre-trained ViT model: It is effective to use a model pre-trained on a large-scale image dataset for the ViT model. DeepNetwork, a one-person company, needs to secure a pre-trained ViT model by downloading, purchasing, or directly learning a publicly available model.
Building a dataset for OCR: The ViT model improves performance through fine-tuning on an OCR-specific dataset. DeepNetwork, a one-person company, needs to build an OCR dataset suitable for its target domain or use a publicly available dataset. The dataset must include the character area in the image and each character label.
Optimization and evaluation of the ViT model: To apply the ViT model to OCR, you need to set appropriate hyperparameters and learning methods. DeepNetwork, a one-person company, needs to find the optimal performance by adjusting the learning speed, patch size, number of layers and number of heads of the ViT model. In addition, to quantitatively evaluate the OCR performance of the ViT model, you need to set appropriate evaluation indicators and standards.
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
I am 60 years old this year… I have been working in the field of Information and Communication Technology (IT) for 30 years… For the past 10 years, I have been a self-employed individual providing development services in the firmware sector of IT… I am going to talk about life in today’s world after 30 years of social life… From now on, I have been reviewing and analyzing 2-3 papers related to Large Language Models (LLM) every day for the past 3-4 years, which is my biggest area of interest… Leaving all sorts of stories aside, I am going to talk about why I have been interested in and analyzing the construction of a GPU Cloud development environment recently… I have also been reviewing and analyzing papers related to LLM for about 3 years… Through paper review and analysis, I have a certain understanding of the design structure of LLM… I have analyzed how to implement it in TensorFlow API, i.e., Python… Although it is not perfect, it has been analyzed to some extent… As I was reviewing and analyzing, there was no place to mention in detail about the development environment for the main issues of distributed learning and parallel learning when implementing LLM… I judge that the key to building a LLM development environment in response to the issue of distributed learning of LLM is to use the concept of Docker container design issue to separate each software development environment… Containers are processes that run in an isolated environment, and each container has an independent file system, network, and execution space. This allows multiple different software development environments to be operated independently on a single server PC… I support the environment for developers to develop TensorFlow containers in an isolated environment with Docker when talking about the LLM distributed development environment… So why this is important is as follows… The reason why you only need the NVIDIA driver to use TensorFlow that supports GPU is because Docker provides an image of TensorFlow that uses GPU. This image already has a CUDA environment that matches the version of TensorFlow. In other words, TensorFlow and CUDA toolkit are installed in Docker, and if there is only NVIDIA driver in the host, you can use GPU. This way, you can avoid the hassle of installing or matching the version of the CUDA toolkit… I can also build a container in an isolated environment with Docker related to distributed learning, but everything is not ready, but I almost understand the key point…
To understand how TensorFlow image, NVIDIA driver, and CUDA environment work together, you need to know the role of each and how they interact.
TensorFlow Image: The TensorFlow image is provided by Docker, and the CUDA environment that matches TensorFlow is already set. This image contains all the software components and libraries needed to run TensorFlow applications. Through this, users can use TensorFlow immediately without a complicated setting process.
NVIDIA Driver: The NVIDIA driver is installed on the host system and acts as an intermediary between the GPU hardware and the operating system. The driver receives requests for GPU from the operating system or application, and converts the request into a command that the GPU can understand. Therefore, the NVIDIA driver is a key element that allows TensorFlow to use GPU.
CUDA Environment: CUDA is a parallel computing platform and API set developed by NVIDIA. CUDA enables high-performance parallel computing by utilizing the computational power of the GPU. The CUDA toolkit is included in the TensorFlow image, which supports TensorFlow operations using the GPU.
These three elements work together so that Docker can use TensorFlow that supports GPU on Linux. The TensorFlow image provides all the necessary software and libraries, and the NVIDIA driver allows this software to communicate with the GPU hardware. Finally, the CUDA environment accelerates TensorFlow’s operations by utilizing the parallel processing power of the GPU. The reason why all three elements must operate for Docker to use TensorFlow that supports GPU on Linux is because they interact with each other to enable TensorFlow’s GPU accelerated operation.
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
[일인기업 딥네트워크 칼만필터 기술력 소개][방산 대기업의 기술분야인 레이더/미사일 제어의 핵심인 9 축센서를 사용해 그 어렵다는 칼만필터 구현을 어떻게 노력해 성취했는가 ?]
2024. 3. 29. 06:21
레이더나 미사일에 적용되는 9 축센서 상용과 군용의 차이점은 주로 성능과 내구성에 있습니다. 군용 센서는 상용 센서보다 더 높은 온도, 습도, 진동, 충격, 방사선 등의 극한 환경에 견딜 수 있도록 설계되어 있습니다. 또한 군용 센서는 상용 센서보다 더 정확하고 안정적인 데이터를 제공하기 위해 더 높은 해상도와 샘플링 레이트를 가질 수 있습니다. 그러나 이러한 차이는 센서의 제조사와 모델에 따라 다를 수 있다 ... 나는 일인기업이다 보니 9 축센서 파악한 부분도 대부분이 상용 9 축 센서에 대한것 들이다 ... 가속도, 자이로스코프, 자력계의 9 축 센서의 센서데이터를 쿼터니언 값으로 변환해서 레이더나 미사일에 적용한다 ... 가속도, 자이로스코프, 자력계의 9 축 센서의 센서데이터로 부터 미사일의 자세제어 정밀도를 좀 더 높이려면 칼만필터 이론을 적용해야 한다 ...
칼만 필터를 활용한 4족 보행 로봇의 자세 검출 및 제어
칼만 필터는 제어 이론에서 주로 사용되는 기술로, 시스템의 상태를 추정하고 불확실성을 줄이는 데에 적용됩니다. 4족 보행 로봇의 자세 검출 및 자세 제어를 위해 칼만 필터를 사용하는 방법은 다음과 같습니다:
1. 상태 추정 (State Estimation)
- 칼만 필터를 이용하여 로봇의 상태를 추정합니다. 보행 로봇의 상태는 관절 각도, 관절 속도, 위치 등을 포함합니다.
- 초기 상태 추정은 로봇의 초기 상태를 예측하고, 센서 데이터를 이용하여 실제 상태를 업데이트합니다.
2. 예측 단계 (Prediction Phase)
- 칼만 필터는 시스템의 다음 상태를 예측하는 단계를 포함합니다.
- 보행 로봇의 다음 상태를 예측하기 위해 관절 각도 변화율, 관절 가속도 등을 사용합니다.
3. 업데이트 단계 (Update Phase)
- 센서 데이터를 이용하여 예측된 상태를 업데이트합니다.
- 보행 로봇의 관절 각도, 가속도, 위치 등의 센서 데이터를 이용하여 상태를 보정합니다.
칼만 필터를 실제 구현할 때 다음 단계를 따라 진행할 수 있습니다:
- 칼만필터 시스템 모델 설계:
- 먼저, 시스템 모델을 정의합니다. 이 모델은 시스템의 동작 방정식을 나타내며, 상태 변수와 입력 변수 간의 관계를 포함합니다.
- 예를 들어, 안테나 각도를 추정하는 시스템에서는 상태 변수로 안테나의 각도와 속도를 고려할 수 있습니다.
- 칼만 필터 예측 단계:
- 예측 단계에서는 현재 상태를 예측합니다.
- 시스템 모델과 현재 상태를 곱하여 예측된 상태를 계산합니다.
- 칼만 필터 업데이트 단계:
- 측정값을 사용하여 예측된 상태를 보정합니다.
- 측정값과 예측된 상태 간의 차이를 계산하여 오차를 추정합니다.
- 칼만 필터 세부 구현 계산 수식:
- 예측된 상태와 오차 공분산을 계산하는 수식은 다음과 같습니다:
- 예측된 상태 = A x 현재 상태 + B x 입력 변수
- 예측된 오차 공분산 = A x 현재 오차 공분산 x A^T + Q
- 여기서 A는 시스템 모델 행렬, B는 입력 변수 행렬, Q는 프로세스 노이즈 공분산 행렬입니다.
- 예측된 상태와 오차 공분산을 계산하는 수식은 다음과 같습니다:
이렇게 설계된 시스템 모델과 칼만 필터를 사용하여 안테나 각도를 추정할 수 있습니다. 실제 구현에서는 시스템 특성에 맞게 상세한 계산을 수행해야 합니다 .
칼만 필터의 동작 원리를 설명하겠습니다:
- 예측 단계의 확률 분포 (Predicted State Estimate): 이 단계에서는 칼만 필터가 로봇의 다음 상태를 예측합니다. 이 예측은 로봇의 현재 상태와 제어 입력에 기반한 모델을 사용하여 이루어집니다. 이 예측은 불확실성을 가지며, 이는 첨부된 그림에서 파란색 가우시안 분포로 표현되어 있습니다.
- 측정 단계의 확률 분포 (Measurement): 이 단계에서는 로봇의 센서로부터 얻은 측정값을 사용하여 예측된 상태를 업데이트합니다. 이 측정값 또한 불확실성을 가지며, 이는 첨부된 그림에서 주황색 가우시안 분포로 표현되어 있습니다.
- 추정 단계의 확률 분포 (Optimal State Estimate): 이 단계에서는 예측 단계와 측정 단계의 결과를 결합하여 최적의 상태 추정값을 얻습니다. 이는 칼만 이득이라는 가중치를 사용하여 두 가우시안 분포를 결합하는 과정을 통해 이루어집니다. 이 최적의 상태 추정값은 불확실성이 줄어든 상태로, 첨부된 그림에서 초록색 가우시안 분포로 표현되어 있습니다.
이렇게 칼만 필터는 예측 단계와 측정 단계를 반복하여 로봇의 상태를 계속 추정하고 업데이트하게 됩니다. 이 과정을 통해 로봇의 자세 제어에 필요한 정확한 상태 정보를 얻을 수 있습니다.
칼만필터는 파면 팔수록 검토 분석할 기술이슈가 계속 나와 지금도 공부중 입니다 ... 그래도 한 1 년 살펴봤더니 칼만필터 세부 구현 원리를 어느 정도 파악하는데 성공해 기쁩니다 ... 국방쪽이든 로봇쪽이든 관련 업체와 긴밀한 협의를 희망 합니다 ...
딥네트워크 / 장석원 / HP 010 3350 6509 / 이메일 sayhi7@daum.net
'Kernel Porting > Linux' 카테고리의 다른 글
One-Person Enterprise DeepNetwork: Pioneering AI Solutions with Proximal Policy Optimization and Reinforcement Learning with Human Feedback
2024. 3. 26. 17:27
DeepNetwork: Pioneering AI Solutions with Proximal Policy Optimization and Reinforcement Learning with Human Feedback
At one-person enterprise DeepNetwork, we specialize in providing expert technical advisory services in the field of deep learning and artificial intelligence. Our primary focus is on the application and understanding of advanced reinforcement learning algorithms, particularly the Proximal Policy Optimization (PPO) algorithm and Reinforcement Learning with Human Feedback (RLHF).
Proximal Policy Optimization (PPO)
PPO is a family of policy gradient methods for reinforcement learning. It alternates between sampling data through interaction with the environment and optimizing a “surrogate” objective function using stochastic gradient ascent. PPO is simpler to implement, more general, and has better sample complexity compared to other methods.
One of the key technical issues we address at DeepNetwork is how PPO uses the Importance Sampling technique to update samples generated from a previous policy to the current policy. Importance Sampling is a Monte Carlo method where a mathematical expectation with respect to a target distribution is approximated by a weighted average of random draws from another distribution.
Reinforcement Learning with Human Feedback (RLHF)
RLHF is a method where we aim to learn the human’s underlying reward and the MDP’s optimal policy from a set of trajectories induced by human choices. It is challenging due to reasons such as large state space but limited human feedback, the bounded rationality of human decisions, and the off-policy distribution shift.
At DeepNetwork, we delve into the core design structure of the RLHF algorithm, as presented in the RLHF paper, and provide expert advice on its implementation and optimization.
My Expertise
With my deep understanding of these advanced algorithms and techniques, we at DeepNetwork are well-equipped to provide insightful and effective solutions for your AI needs. Whether you’re looking to implement these algorithms in your systems or seeking advice on optimizing their performance, our team of experts is ready to assist.
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
I am 60 years old this year and have been working in the IT software development field for 30 years. I started analyzing deep learning papers about 4-5 years ago… Initially, I started analyzing papers to apply deep learning to the vision field… Then, I also analyzed papers to understand the detailed structure of ultra-large language models… When implementing ultra-large language models, I looked at what techniques global corporations used in their papers and how the detailed implementation of the Google Transformer model was applied using the Google TensorFlow API, how the detailed layers of the Transformer Model were implemented, and how Python syntax was applied… As I looked into this, I realized that it was very important to solve the question of how the GPU Cloud Server Infra is designed… I have succeeded in understanding how the GPU Cloud Server Infra is designed, not 100%, but the big core principle… Nowadays, even large corporations seem to realize the importance of these things and are focusing on securing know-how in GPU Cloud Server Infra design…
Docker uses the concept of containers to separate each software development environment. A container is a process that runs in an isolated environment, and each container has its own file system, network, and execution space. This allows you to operate multiple different software development environments independently on a single server PC. Docker creates and manages these containers, using something called Docker images in the process. Docker images contain all the file systems, settings, dependencies, etc. needed to run a container. You can create and run containers based on this image, and if necessary, you can change the state of the container to create a new image. These created images can be shared through remote repositories like Docker Hub, and any system with Docker installed can download the image and run the container. In this way, Docker ensures the consistency of the development environment and facilitates the execution of software in various environments.
Therefore, by using Docker, you can install and operate multiple different software development environments independently on a single server PC, and these environments operate independently of each other.
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
[일인기업 딥네트워크 탱크의 수위 측정 (액체 수준(수위)을 측정) 개발 전문][ToF 원리를 사용하여 탱크의 액체 수준을 측정하는 시스템을 설계하고 구현]
2024. 3. 24. 16:38
제가 운영하는 딥네트워크 에서는 탱크의 수위를 측정하기 위해 Analog Devices 의 3D Time of Flight (ToF) 기술을 사용하여 깊이 정보를 캡처하는 데 사용되는 칩셋을 사용합니다. 이 기술은 고전력 광 펄스를 사용하여 관심 있는 장면에서 깊이 정보를 캡처합니다. 이러한 칩셋 중 하나는 ADSD3100 ToF 신호 프로세서를 기반으로 하는 깊이 이미지 신호 프로세서인 ADTF3175입니다. 이러한 단계를 따르면, ToF 원리를 사용하여 탱크의 액체 수준을 측정하는 시스템을 설계하고 구현할 수 있습니다.


Analog Devices에서는 3D Time of Flight (ToF) 기술을 사용하여 깊이 정보를 캡처하는 데 사용되는 칩셋을 제공합니다. 이 기술은 고전력 광 펄스를 사용하여 관심 있는 장면에서 깊이 정보를 캡처합니다. 이러한 칩셋 중 하나는 ADSD3100 ToF 신호 프로세서를 기반으로 하는 깊이 이미지 신호 프로세서인 ADTF3175입니다.
ToF 기반의 수위 측정 시스템을 설계하고 구현하는 단계는 다음과 같습니다:
- 센서 선택: 먼저, 적절한 ToF 센서를 선택해야 합니다. 이 경우에는 Analog Devices의 ADSD3100 ToF 신호 프로세서를 사용할 수 있습니다.
- 센서 배치: 센서는 탱크의 상단에 배치되어야 합니다. 이렇게 하면 센서가 탱크 내부의 액체 수준까지의 거리를 측정할 수 있습니다.
- ToF 원리 적용: 센서는 빛의 펄스를 발사하고, 이 펄스가 액체 표면에서 반사되어 센서로 돌아오는 시간을 측정합니다. 이 시간을 사용하여 액체 수준을 계산할 수 있습니다.
- 펌웨어 개발: 펌웨어는 센서에서 수집된 데이터를 처리하고, 액체 수준을 계산하며, 필요한 경우 이 정보를 다른 시스템 또는 사용자에게 전송합니다. 이를 위해, ADI ToF SDK와 같은 소프트웨어 개발 키트를 사용할 수 있습니다.
- 시스템 테스트 및 최적화: 마지막으로, 시스템은 다양한 조건에서 테스트되어야 합니다. 이를 통해 성능을 평가하고 필요한 경우 시스템을 최적화할 수 있습니다.
ADTF3175는 Analog Devices에서 제공하는 3D Time of Flight (ToF) 이미징 솔루션입니다. 이 센서는 주로 iToF 기술을 사용하여 깊이 정보를 캡처합니다. 다음은 ADTF3175의 세부 사양과 관련된 정보입니다:
ADTF3175의 광원 변조 주파수
ADTF3175는 수십 MHz에서 수백 MHz의 변조 주파수를 사용합니다. 정확한 변조 주파수에 대한 정보는 Analog Devices의 공식 문서나 제품 데이터시트에서 확인할 수 있습니다. 제품 데이터시트에 따르면 ADTF3175는 60MHz의 변조 주파수를 사용합니다.
ADTF3175의 ADC 샘플링 속도
ADTF3175의 ADC 샘플링 속도에 대한 명확한 정보를 제공하기 위해 Analog Devices의 제품 문서와 데이터시트를 참조해야 합니다. ADTF3175의 데이터시트에는 ADC의 샘플링 속도가 명시되어 있지 않을 수 있습니다. 하지만, 일반적으로 iToF 센서에서 사용되는 변조 주파수에 기반한 샘플링 속도는 변조 주파수의 최소 2배 이상이어야 합니다. 이는 Nyquist 샘플링 정리에 따른 것입니다.
요약
- 광원 변조 주파수: ADTF3175는 60MHz의 변조 주파수를 사용합니다.
- ADC 샘플링 속도: ADTF3175의 데이터시트에는 명확한 샘플링 속도가 명시되어 있지 않지만, 변조 주파수의 최소 2배 이상의 샘플링 속도가 요구되므로 최소 120MSPS 이상의 샘플링 속도가 필요합니다. 하지만, 실제로는 더 높은 샘플링 속도를 사용하여 신호의 정확성을 높일 수 있습니다.
FFT 변환 및 주파수 스펙트럼 분석
iToF 시스템에서 깊이 데이터를 FFT 변환하여 주파수 스펙트럼을 분석하는 것은 다음과 같은 과정을 거칩니다:
- 신호 수집: 변조된 광신호가 목표물에서 반사되어 센서에 도달합니다.
- 샘플링: 센서에서 수신된 신호를 ADC를 통해 디지털화합니다. 이때 샘플링 속도는 변조 주파수의 최소 2배 이상이어야 합니다.
- FFT 변환: 샘플링된 신호에 대해 FFT를 수행하여 주파수 스펙트럼을 얻습니다.
- 주파수 분석: 주파수 스펙트럼에서 가장 큰 값을 가지는 주파수를 찾습니다. 이 주파수는 광신호의 변조 주파수와 반사 시간 지연에 의해 결정되며, 이를 통해 목표물까지의 거리를 계산할 수 있습니다.
iToF 방식에서 주파수 스펙트럼의 최대값 사용
주파수 스펙트럼의 최대값을 깊이 데이터로 사용하는 방법은 다음과 같이 진행됩니다:
- 주파수 스펙트럼 분석: FFT를 통해 얻은 주파수 스펙트럼에서 최대값을 찾습니다.
- 시간 지연 계산: 해당 주파수를 사용하여 시간 지연을 계산합니다. 이는 변조 주파수와의 관계를 통해 얻을 수 있습니다.
- 거리 계산: 시간 지연을 통해 목표물까지의 거리를 계산합니다.
결론
iToF 시스템에서 깊이 데이터를 측정하기 위해서는 일반적으로 200 MSPS 이상의 ADC가 필요합니다. FFT 변환을 통해 주파수 스펙트럼을 분석하고, 최대값을 이용하여 시간 지연과 거리를 계산할 수 있습니다. ADTF3175는 이러한 방식으로 깊이 데이터를 캡처할 수 있습니다.
이러한 단계를 따르면, ToF 원리를 사용하여 탱크의 액체 수준을 측정하는 시스템을 설계하고 구현할 수 있습니다.
딥네트워크 장석원 010 3350 6509 sayhi7@daum.net
'Kernel Porting > Linux' 카테고리의 다른 글
Hello, I am the representative of Deepnetwork, a one-person company specializing in electric vehicle battery charging control.
2024. 3. 22. 10:09
NXP’s MC33771C is a 14-channel lithium-ion battery cell controller IC that can monitor the status of each cell.
Cell state monitoring: These chipsets monitor the status of each cell through high-precision cell voltage and temperature measurements. They use ADC conversion to measure the difference in cell voltage, and average a maximum of 256 samples to increase accuracy.
Overcharge, overcurrent, high temperature detection: The chipset supports ISO 26262 ASIL D for cell voltage, module voltage, and temperature measurements, allowing it to detect overcharge, overcurrent, and high temperature situations. In addition, these chipsets provide OV/UV, OT/UT, OC fault verification, and support OV/UV, OT/UT monitoring in Sleep mode.
Forced down function: When overcharge, overcurrent, and high temperature situations are detected, the chipset provides various functions to solve these problems. For example, it can maintain cell voltage balance through a programmable balancing timer for each MOSFET. Also, the built-in 300mA low Rdson passive cell balancing MOSFET provides diagnostic functions to monitor and adjust the cell status as needed.
NXP’s MC33771C chipset detects overcharge, overcurrent, and high temperature situations in the following ways:
Overcharge detection: The chipset monitors the voltage of each cell through high-precision cell voltage measurement. If the cell voltage exceeds a certain threshold, the chipset considers this an overcharge state and starts balancing for that cell.
Overcurrent detection: It can measure current with an accuracy of ±0.5% from milliamperes to kiloamperes through a current sensor and programmable gain amplifier (PGA). This allows it to detect overcurrent situations.
High temperature detection: The chipset monitors the temperature of the battery through a built-in temperature sensor. If the temperature exceeds a certain threshold, the chipset considers this a high temperature state.
These detection mechanisms allow the chipset to monitor the battery’s status in real-time and take necessary actions. This plays an important role in ensuring the safety and lifespan of the battery.
Core know-how of charging control firmware for Samsung 21700 50E / 7S 20P battery cell with NXP MC33771C chipset
The NXP MC33771C chipset is a high-performance battery cell controller that can simultaneously monitor and control the charging and discharging of 14 cells. Our company has analyzed the firmware design structure that can precisely measure and manage the voltage, current, temperature, remaining amount, life, etc. of the Samsung 21700 50E / 7S 20P battery cell using this chipset.
Our company’s firmware has the following features:
It sets the optimal charging voltage and current for each cell, and balances the cells to enhance the performance and lifespan of the battery. It detects the temperature of the cell in real-time, and adjusts or stops charging to prevent overheating or overcharging. It accurately predicts the remaining amount and life of the cell, and communicates with smartphones or computers via LED or LCD display or Bluetooth or WiFi.
Deepnetwork, a one-person company, applied the evaluation board to control the charging of Samsung 21700 50E / 7S 20P battery cells
The EVB evaluation board is a board that can evaluate and test the functions and performance of a battery cell controller using the NXP MC33771C chipset. Our company has detailed analysis of developing and verifying the charging control technique for Samsung 21700 50E / 7S 20P battery cells using this board.
Our company’s charging control technique has the following features:
It optimizes the charging curve according to the characteristics and requirements of the Samsung 21700 50E / 7S 20 P battery cell, and improves charging efficiency and safety. It minimizes the heat generated during charging, and monitors and diagnoses the charging state by analyzing the internal resistance and chemical reaction of the cell. It stores and analyzes the data generated during the charging process to evaluate and improve the quality and reliability of the battery.
In active cell balancing, energy is extracted from overcharged cells and moved to low-voltage cells. For this, the active balancing circuit uses switches and resistors between each cell. These circuits control the switch according to the voltage state of each cell to move energy.
The switch control algorithm is as follows:
Voltage monitoring: The firmware periodically monitors the voltage of each cell. This period is determined according to the system requirements and the characteristics of the battery.
Overcharge cell detection and energy movement: When an overcharged cell is detected, the firmware controls the switch between the cell and the low-voltage cell to move energy. This helps maintain the voltage of the cell within a safe range and minimize the voltage difference between cells.
These algorithms must go through a rigorous design and verification process according to ASIL D standards. The verification procedure must include system-level verification that tests electromagnetic compatibility, electrostatic discharge, transient immunity, and communication reliability in harsh environments.
In the firmware design using the NXP MC33774 chipset, the control algorithm for active cell balancing is as follows:
Active balancing circuit design: Active cell balancing is a method of extracting energy from overcharged cells within the battery pack and moving it to low-voltage cells. For this, the active balancing circuit uses switches and resistors between each cell. These circuits control the switch according to the voltage state of each cell to move energy.
Voltage monitoring: The firmware periodically monitors the voltage of each cell. This period is determined according to the system requirements and the characteristics of the battery. Generally, this period is determined considering various factors such as charging state, battery temperature, cell connection status, etc.
Switch control algorithm: The firmware implements an algorithm to control the switch to move energy from overcharged cells to low-voltage cells. This algorithm monitors the voltage state of each cell and controls the energy movement between overcharged cells and low-voltage cells. This allows you to minimize the voltage difference between cells and maintain the voltage of the battery pack uniformly.
These algorithms must go through a rigorous design and verification process according to ASIL D standards. The verification procedure must include system-level verification that tests electromagnetic compatibility, electrostatic discharge, transient immunity, and communication reliability in harsh environments.
The NXP MC33774 chipset provides a maximum cell balancing current of 300 mA for each cell. This means that each battery cell can independently balance through a maximum current of 300 mA.
The control algorithm for passive cell balancing is as follows:
Voltage monitoring: The firmware periodically monitors the voltage of each cell. This period is determined according to the system requirements and the characteristics of the battery. Generally, this period is determined considering various factors such as charging state, battery temperature, cell connection status, etc.
Overcharge cell detection: The firmware analyzes the monitored voltage data to detect overcharged cells. Overcharged cells are cells whose voltage is higher than a certain threshold.
Current leakage: When an overcharged cell is detected, the firmware lowers the voltage by letting current flow through the resistor connected to the cell. This helps maintain the voltage of the cell within a safe range and minimize the voltage difference between cells.
These algorithms must go through a rigorous design and verification process according to ASIL D standards. The verification procedure must include system-level verification that tests electromagnetic compatibility, electrostatic discharge, transient immunity, and communication reliability in harsh environments.
Are there any professional development companies that have confirmed operation without problems during the stringent international safety certification when charging control with the battery cell controller chipset? It seems that a complex detailed safety verification process is necessary to ensure that the firmware and circuit design are definitely completed without any problems in accordance with this certification standard. I wonder if there is a company that is confident that there is no problem with this stringent international certification. After detailed review, it is quite tricky, so I leave additional opinions like this …
Deep Network, a one-person startup specializing in consulting for electric vehicle battery charging control
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
“The GPT-3 model, which applies the theory of conditional probability to large-scale language models to predict the next word, was trained and applied to create GPT-3.5, which has shown remarkable performance. However, when you look closely, the learning algorithm itself does not differ significantly from the learning algorithm based on the design principles of Google’s Transformer. Rather, the reason GPT-3.5 has shown such remarkable performance is due to the quantity and quality of the training data used when applying the theory of conditional probability to large-scale language models to predict the next word. I believe that this is the reason why GPT-3.5 has shown such remarkable performance… Do you think my opinion is wrong?”
- Learning Algorithm: GPT-3.5 is based on Google’s Transformer model. The Transformer model uses an “Attention” mechanism that allows each element of the input data to interact with all other elements. This is very important for understanding context, as the meaning of a word in a sentence can greatly vary depending on the context it is placed in. The Transformer model effectively captures this contextual information for understanding and generating language.
- Quantity and Quality of Data: GPT-3.5 uses a large amount of text data collected from the internet for training. This data includes a variety of topics and styles, allowing the model to enhance its ability to understand and generate language in various contexts. Also, the quality of the data is important. The better the training data is cleaned, diversified, and representative, the better the performance of the model. For example, if the model learns from biased data, it can generate biased results. Therefore, using high-quality data is important.
- Conditional Probability: GPT-3.5 uses “conditional probability” to predict the next word. That is, it calculates the probability of what the next word will be given the context. This is used when the model generates sentences, where at each step, the word with the highest probability is selected to complete the sentence.
These factors combine to allow GPT-3.5 to excel in various language tasks. The reason all of this is possible is because GPT-3.5 learns from a large amount of data, through which it understands the complexity and diversity of language. This plays a crucial role in enhancing the model’s ability to understand and generate language in various contexts.
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
[Introduction to the Know-how of Handling Key Issues in Detail] When implementing LLM (Large Language Model) with Google Transformer Model in TensorFlow environment…
2024. 3. 15. 15:16
I am Seokwon Jang, a technical advisor specializing in ultra-large model technology at DeepNetwork. I approached the commercialization preparation of the ultra-large language model, ChatGPT, somewhat vaguely three years ago. In fact, many corporate officials may wonder if a one-person company like me can understand the implementation know-how of an ultra-large language model like ChatGPT.
For over three years, I have been reviewing and analyzing two foreign papers related to LLM (Large Language Model) every day. After reviewing and analyzing papers for three years, I learned what global companies are concerned about when implementing ultra-large models. The content I have reviewed and analyzed for three years is roughly that I have carefully studied about 100 key issues in the implementation design field of deep learning. Based on this, I first analyzed the design structure of LLM.
Once I understood the design structure of LLM to some extent, in the case of Facebook, it was said that they proceeded with LLM learning by designing and building a clustering of 16,000 NVIDIA A100 GPUs. If such a huge infrastructure cost is incurred, it may be difficult to secure profits, so I looked at a considerable part of the papers that research to reduce the parameters of LLM while maintaining performance. I also reviewed and analyzed papers on what preparations are needed to implement on-device AI, which is a model lightweight.
It was also possible to understand that lightweight implementation can be largely processed with Quantization design and knowledge distillation techniques. The Quantization part is absolutely necessary for on-device AI design and integration design within SOC, and NVIDIA has already integrated FP8 function in H100 GPU.
Did DeepNetwork only review and analyze up to here? This is not all. When implementing LLM or sLLM, it is possible to review and analyze what issues should be considered when customizing each part of several layers of Google Transformer model in TensorFlow environment and how to solve these issues.
I can’t speak English, but I can send and receive English emails. I ask for careful review by AI managers of domestic and foreign global companies. I have learned how to catch fish, so please don’t underestimate the LLM and sLLM technology of DeepNetwork just because there are no fish caught right now.
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang
'Kernel Porting > Linux' 카테고리의 다른 글
초거대 모델 기술자문 전문 딥네트워크 장석원 입니다 ... 초거대 언어 모델 ChatGPT 의 상용화 준비를 하는것에 나도 3 년전에는 약간 막연하게 접근했다 ... 사실 ChatGPT 같은 초거대 언어 모델의 구현 노하우를 저 같은 일인기업이 파악이 가능하기나 하냐 라고 의문을 가지는 기업 관계자가 많을것 입니다 ... 제가 그동안 한 3 년 이상 LLM(거대언어모델)관련 해외 논문을 3 년 동안 매일 매일 하루에 두편씩 세부 검토 분석을 해왔읍니다 ... 이렇게 한 3 년 논문을 검토 분석하다 보니 초거대 모델 구현시 글로벌 기업들이 관련 기술이슈를 어떤것들을 고민하는지를 알게됬읍니다 ... 제가 그동안 3 년동안 논문을 검토 분석한 내용은 대략적으로 딥러닝 분야 구현 설계 핵심 이슈 한 100 가지 정도를 세심히 공부를 했다는것 입니다 ... 이것이 바탕이 되서 맨 처음에는 LLM(거대언어모델) 설계 구조를 분석했읍니다 ... 이렇게 LLM 의 설계구조가 파악이 어느 정도 되다 보니 FaceBook 같은 경우 엔비디아 A100 GPU 를 16000 대를 클러스터링 설계 구축을 한것으로 LLM 을 학습 진행을 했다고 하구요 ... 이렇게 막대한 인프라 비용이 들 경우 이윤 확보가 어려워질수 있어서 LLM 의 파라미터를 줄이면서도 성능을 유지하는 연구들을 하길래 이쪽 논문들을 상당 부분 살펴 봤읍니다 ... 이것도 나름 어느 정도 파악이 되길래 모델 경량화를 아예 온 디바이스 AI 까지 구현 하려면 어떤것을 준비해야 가능한지도 논문들을 검토 분석을 했구요 ... 경량화 구현도 Quantization 설계와 지식증류 기법으로 상당 부분 처리가 가능하다는것도 파악이 가능했읍니다 ... Quantization 부분은 온 디바이스 AI 설계시 SOC 내에 집적화 설계가 반드시 필요하고 이미 엔비디아는 H100 GPU 에 FP8 기능 구현을 이미 집적화시켰구요 ... 그럼 딥네트워크가 여기까지만 검토 분석을 했냐 .... 이게 다 가 아닙니다 ... LLM 을 구현하거나 sLLM 구현시 텐서플로우 환경에서 구글 트랜스포머 모델의 여러 레이어의 각각의 부분의 커스토마이징시 어떤 이슈를 고민해야 하는지 또 어떻게 이 이슈를 해결 가능한지를 검토 분석이 되있읍니다 ... 저는 영어회화는 안되지만 영문 이메일은 주고 받을수 있읍니다 ... 국내외 글로벌 기업의 AI 책임자분들의 세심한 검토 요청드립니다 ... 물고기를 잡는 방법을 터득했으니 당장 지금 잡은 물고기가 없다고 해서 딥네트워크의 LLM 과 sLLM 기술력을 얕잡아보지 마시길 부탁드립니다 ...
딥네트워크 장석원 010 3350 6509 sayhi7@daum.net
The 900GB/s bandwidth between the Grace CPU and NVIDIA Hopper GPU is made possible by NVIDIA’s NVLink-C2C technology. This technology connects the CPU, GPU, and memory in a memory-coherent, high-bandwidth, low-latency manner. It provides a bandwidth that is 7 times faster than PCIe Gen5. NVLink-C2C combines the Grace CPU and Hopper GPU into a single superchip, providing a CPU+GPU coherent memory model for accelerated AI and HPC applications. This optimizes data transfer between the CPU and GPU, enhancing processing for large-scale AI and HPC applications. In addition, the Grace CPU Superchip supports up to 128 PCIe Gen 5 lanes, providing I/O connectivity. Each PCIe Gen 5 x16 link supports a maximum bandwidth of 128GB/s in both directions. This can be split into 2x8 for additional connectivity and supports various PCIe slot formats. Therefore, the combination of NVLink-C2C technology and PCIe Gen 5 lanes enables high bandwidth between the Grace CPU and NVIDIA Hopper GPU. The 900GB/s bandwidth between the Grace CPU and NVIDIA Hopper GPU represents the data transfer speed, which indicates the time required to exchange data between the two chips. This plays a crucial role in large-scale AI and high-performance computing (HPC) applications. This bandwidth represents the time required for the Grace CPU and NVIDIA Hopper GPU to exchange data with each other, which is separate from the internal memory capacity of the two chips. In fact, the NVIDIA Grace Hopper Superchip uses 96GB of HBM3 memory, and the GH200 uses 141GB of HBM3e memory technology, providing more than 3 times the bandwidth of the A100. Therefore, the 900GB/s bandwidth of NVLink-C2C represents the data exchange speed between the Grace CPU and NVIDIA Hopper GPU, which is separate from the internal memory capacity of the two chips. The 900GB/s bandwidth of NVLink-C2C and the data processing speed of HBM3E represent different aspects. The 900GB/s bandwidth of NVLink-C2C represents the data exchange speed between the Grace CPU and NVIDIA Hopper GPU. This is separate from the internal memory capacity of the two chips. NVLink-C2C combines the Grace CPU and Hopper GPU into a single superchip, providing a CPU+GPU coherent memory model for accelerated AI and HPC applications. This optimizes data transfer between the CPU and GPU, enhancing processing for large-scale AI and HPC applications. On the other hand, the data processing speed of HBM3E represents the speed at which the memory chip itself reads and writes data. This plays an important role in data processing within the GPU. Therefore, while the 900GB/s bandwidth of NVLink-C2C technology and the data processing speed of HBM3E represent different aspects, these two performance indicators are related, and both play a crucial role in the overall performance of the system. And yes, a PCIe Gen 5 x16 link does support a maximum bandwidth of 128GB/s in both directions. This is according to the standard specifications of PCIe Gen 5. However, this is separate from the 900GB/s bandwidth of NVLink-C2C. NVLink-C2C is NVIDIA’s proprietary technology, designed for data exchange between the Grace CPU and NVIDIA Hopper GPU. This is a separate performance indicator from the bandwidth of PCIe Gen 5. The 900GB/s bandwidth of NVLink-C2C allows for fast data transfer, but the actual time required to read and write data heavily depends on the performance of the memory. Therefore, the time required for the NVIDIA Grace Hopper Superchip to read data from 96GB of HBM3 memory and for the GH200 to write data to 141GB of HBM3e memory will vary depending on the memory performance of each. Also, the same memory performance is required even if the direction of reading and writing data is reversed. That is, the same memory performance is required even if data is read from HBM3e memory and written to HBM3 memory. Therefore, the data processing bandwidth of HBM3e memory is an important factor. This is essential for quickly processing data and performing high-performance computing tasks. This memory performance plays an important role in high-performance computing, artificial intelligence, machine learning, and other tasks.
Deep Network, a one-person startup specializing in consulting for super-large language models
E-mail : sayhi7@daum.net
Representative of a one-person startup / SeokWeon Jang